 |
Компьютер в бухгалтерском учете и аудите 2000'2
|
|
|
Научно-производственная
фирма “КОНТЭКС”
Эффективная Интеллектуальная Правовая
естественно-языковая система “ВердиктЪ”
Введение
В условиях смены политической и
хозяйственных систем в стране, число
ежемесячно появляющихся и изменяющихся
правовых документов составляет несколько
тысяч.
Кроме того, часто некоторые из
вновь принятых документов полностью или
частично противоречат ранее принятым, но не
утратившим еще юридической силы документам.
Поэтому для руководителей
предприятий, главных бухгалтеров, юристов и
других лиц руководящего состава
предприятий попытка отслеживать эти
изменения и разбираться в динамично
меняющемся законодательстве является
непосильной задачей без использования
компьютерных правовых систем.
В настоящее время разработан
ряд нормативно-справочных правовых систем
как коммерческого характера (таких как: “Консультант+”,
“Гарант”, “Кодекс” и т.п.), так и
государственных, например система “Эталон”
министерства Юстиции РФ и т.п., которые в
дальнейшем мы будем называть традиционными.
Все эти системы основаны на
принципах, заложенных в начале 90-х годов, и
построены на автоматизации одной и той же “принципиальной”
схемы поиска, повторяющей “ручной” (докомпьютерный)
способ поиска полнотекстовых документов
человеком — юристом, который работал
по документам на бумажных носителях
информации (сборники законов,
постановлений и т.п.).
Поскольку человек физически не
в состоянии быстро просмотреть большие
объемы полных текстов документов, то
предварительно составлялась картотека с
использованием того или иного
тематического рубрикатора или
классификатора.
В каждой карточке картотеки
обычно указывался код тематической рубрики,
основные реквизиты документа (номер, дата и
т.п.), а также содержание документа в виде
его краткой аннотации, или реферата, или
списка, так называемых “ключевых” слов, то
есть главных, на его взгляд, слов,
передающих основной смысл документа.
Здесь же указывался адрес
самого документа, входящего в сборник
нормативных документов (законов,
постановлений, распоряжений и т.п.) и
хранящегося на полках его личного архива.
Поэтому во всех указанных
системах, как правило, обязательно
присутствует поиск по рубрикам и ключевым
словам.
Однако поиск по рубрикам
является довольно грубым способом поиска,
поскольку каждая рубрика охватывает
достаточно большую тематическую
предметную область, а поэтому система в
ответ на запрос выдаёт слишком большое
количество документов, которые приходится
просматривать на экране.
Кроме того, число рубрик обычно
бывает небольшим и часто не охватывает все
тематические области документов. При этом
человек фактически снова занимается ручным
поиском, но уже не на бумаге, а просматривая
тексты документов на экране монитора.
Поиск по ключевым словам
позволяет произвести более точный поиск,
однако список ключевых слов также
ограничен и фактически представляет собой
расширенный рубрикатор, то есть этот вид
поиска также не решает проблемы
эффективного поиска с помощью компьютера.
Кроме того, поиск по рубрикам и
ключевым словам часто вызывает у
пользователя затруднения в выборе
требуемой рубрики или ключевого слова,
поскольку количество их весьма ограничено
и не сравнимо с количеством слов
естественного языка пользователя. Это
часто являлось главным источником ошибок
поиска, которые можно обобщенно разделить
на два рода (типа).
-
Ошибка
первого рода, когда система в ответ на
запрос выдает документы, не
соответствующие запросу. В дальнейшем
эту ошибку будем называть ошибкой
выдачи ложного документа, а
совокупность таких ошибок — информационным
шумом.
-
Ошибка
второго рода, когда система не выдает
требуемого пользователем документа, хотя
он и имеется в базе данных. Этот род
ошибок будем называть ошибкой пропуска
документа.
Причем величины этих ошибок, как
показали эксперименты, могут достигать
больших значений.
Поэтому разработчики были
вынуждены ввести во всех системах поиск
непосредственно по тексту документа. При
этом список слов запроса заранее не
фиксируется, и нужное слово выбирается
самим пользователем, исходя из его
информационной потребности.
Поиск по тексту (иногда его еще
называют “сложным”, “интеллектуальным”
или “контекстным” поиском) обычно
производится с использованием элементов
математической (булевой) логики, для связи
слов в тексте запроса, таких как: И, ИЛИ, НЕ,
РЯДОМ и т.п.
Однако такой поиск накладывает
на пользователя большую умственную и
психологическую нагрузку, так как
формальный (математический) смысл
логических операторов, например И и ИЛИ и т.п.
не полностью совпадает со смыслом
аналогичных союзов И и ИЛИ в обычных
текстах.
Это также приводит к появлению
ошибок поиска первого и второго рода.
Для повышения эффективности
поиска по тексту желательно, чтобы
пользователь задавал вопросы на его родном
естественном языке без каких-либо
формальных ограничений, а машина сама
разбиралась бы, какие логические операторы
необходимы для данного запроса, или
использовались бы другие формальные
алгоритмы поиска информации.
Именно к этому классу систем
относится система “ВЕРДИКТЪ”, которая
представляет собой новое поколение
полнотекстовых поисковых систем,
использующих современные методы
статистического, морфологического и
синтаксического анализа текстов русского
языка, а также другие современные
алгоритмические подходы к содержательной
обработке текстовой информации.
Пользователь задает запрос на
естественном русском языке в виде слов,
фраз или предложений именно в том виде, в
котором они возникают в его голове. Это
минимизирует ошибки и время поиска, так как
при задании запросов на поиск отсутствует
необходимость в выборе правильных рубрик,
ключевых слов и логических связок типа “И”,
“ИЛИ”, “НЕ”, “РЯДОМ” и т.п.
Кроме того, слова, связанные
логическими операторами И, ИЛИ, НЕ и др.,
часто могут (особенно для больших текстов)
образовывать ложные логические комбинации,
что также приводит к выдаче дополнительных
ложных документов.
Поиск в системе “ВЕРДИКТЪ”
осуществляется полностью автоматически на
основе уравнения максимизации функции
эффективности поиска, зависящей от ряда
морфологических и синтаксических
параметров текста, имеющих в основе
безтезаурусную модель отношений синонимии
и ассоциации слов естественного языка.
Поиск производится за один шаг,
что обеспечивает максимальное
быстродействие поиска (2–15 секунд при
объеме базы данных в 400 Мб и более).
В последующих разделах данной
статьи рассматриваются вопросы оценки
поисковой эффективности системы “ВЕРДИКТЪ”,
описание ее работы, перечень и структура ее
баз данных, а также приводятся примеры
поиска по запросам различного типа.
Эффективность поиска в системе
Система “ВЕРДИКТЪ” с точки
зрения теории информатики относится к
классу так называемых “документальных”
или “текстовых” информационно-поисковых
систем [1].
Эффективность работы такой
системы является комплексным понятием и
включает в себя собственно поисковую
эффективность, технологическую
эффективность (определяется выбранными
техническими средствами), полноту охвата и
достоверность информационного фонда,
периодичность актуализации данных и т.п.
Среди перечисленных показателей поисковая
эффективность является выходной
характеристикой системы, поскольку она
является функцией всех других показателей
и фактически определяет саму
целесообразность создания системы и ее
эксплуатации.
Выше указывалось, что
вследствие ошибок пользователя при
формулировании запросов возникают ошибки
поиска первого и второго рода. Кроме того,
могут появиться дополнительные ошибки,
поскольку слова естественного языка
обладают внутренней неопределенностью (неполной
четкостью выражения этими словами
обозначаемого ими смысла слова [2].
Таким образом, в результате
поиска могут быть выданы документы как
прямо и полностью соответствующие запросу (то
есть на 100 %), так и косвенно (то есть
частично) соответствующие или даже
полностью не соответствующие запросу.
Эффективной считается такая
система, которая выдает максимум
документов, полностью или косвенно
соответствующих запросу, и минимум
несоответствующих запросу.
Для измерения поисковой
эффективности в настоящее время предложено
много критериев и показателей, однако
наибольшее распостранение получили два
показателя эффективности: П — полнота
поиска и Т — точность поиска [ 1], [3].
Полнота поиска косвенно
характеризует вероятность нахождения
системой документов, соответствующих
запросу. Точность поиска характеризует
способность системы отсеивать не
соответствующие запросу документы.
Система “ВЕРДИКТЪ” позволяет
пользователю дать оперативную
приближенную оценку этих характеристик
непосредственно в процессе сеанса поиска
по каждому из запросов, через количество
выданных ею документов в ответ на запрос
пользователя.
Показатели П и Т зависят друг от
друга в обратной нелинейной зависимости.
При этом Т макс соответствует П мин., а Т мин.
соответствует П макс (см. рис.1).
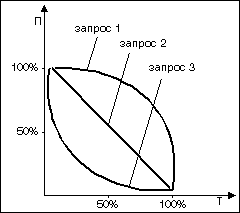
Рис. 1. Взаимосвязь полноты
и точности поиска
При максимальной полноте
поиска, П=100 % Пмакс, система
выдаёт максимальное общее количество
документов, найденных ею в базе данных, а
следовательно, и максимальное число
документов, соответствующих запросу.
Однако число найденных документов, не
соответствующих запросу (то есть ложных
документов), в этом случае будет также
наибольшим.
При максимальной точности
поиска, Т =100 % Тмакс, система
выдаёт минимальное общее число
документов, найденных в базе данных. При
этом процент соответствующих запросу
документов по отношению к не
соответствующим запросу будет гораздо выше,
чем при значениях П макс.
Что лучше, иметь больше
пропущенных документов или ложных
документов, — решает пользователь.
Здесь следует отметить, что
ошибка пропуска документов является более
опасной и дорогой для пользователя, чем
ошибка выдачи ложных документов.
Ошибка пропуска документов
означает, что пользователь не будет знать о
существовании в базе данных нужных ему
документов.
Это, в лучшем случае, приведёт к
напрасной трате пользователем своего
времени на поиск документов из других
альтернативных источников (газеты,
сборники нормативных актов и т.п.), если
пользователь точно знает, что где-то
существует искомый документ. Если же
пользователь вообще не знает о
существовании нужного ему документа, то он
может успокоиться и прекратить поиск.
Это — худший случай, так
как он может привести к материальным (финансовым)
потерям, вследствие незнания нормативных
актов (например, к проигрышу дела в суде,
штрафу налоговой инспекции и т.п.).
Ошибка выдачи ложных
документов приводит только к потерям
времени на их просмотр на экране монитора.
При больших объёмах баз данных это может
потребовать весьма большого времени.
Здесь следует отметить, что
вопросы оценки эффективности поиска в
документации к традиционным системам типа
“Консультант+”, “Гарант”, “Кодекс” и др.
вообще не упоминаются.
Сравнительный
экспериментальный анализ поиска в системе
“ВЕРДИКТЪ” с поиском в упоминавшихся выше
системах показал, что последние системы по
ряду запросов не могут найти документы.
Например, по запросу “О льготах по налогу
на добавленную стоимость для научно-исследовательских
организаций, финансируемых из госбюджета”,
сравниваемые системы не нашли ни одного
документа. Система “ВЕРДИКТЪ” нашла 8
документов (при П=50 % Пмах) за 5 сек.,
из них 3 документа оказались полностью
соответствующими запросу.
Анализ причин ненахождения
системой “Консультант” документов
показал, что она требует:
-
полного
совпадения слов запроса и документа (в
данном же запросе использовано слово “госбюджет”,
которое в явном виде отсутствует в
текстах документов;
-
логика
оператора связи слов “РЯДА”, что
эквивалентно использованию союза “И” в
пределах трех строк текста документа для
длинных запросов (в данном случае, восемь
слов), часто не срабатывает, так как
некоторые слова запроса попадают за
пределы трех строк.
Та же ситуация будет иметь место
и для других частей, использующих
логические запросы.
Система “Вердикт” не требует
полного совпадения слов запроса и
документа, используя другие алгоритмы
поиска.
Среднее время “машинного”
поиска по тексту в системе “ВЕРДИКТЪ”
оказалось в 20 раз меньшим, чем в системе “Консультант+”.
Причём базы данных во всех сравниваемых
системах содержали найденные системой “ВЕРДИКТЪ”
документы. И только после достаточно
длительного времени (более 12–15 мин.), путём
последовательного итерационного
поэтапного (машинного + ручного) поиска
опытным пользователем (по рубрикам,
ключевым словам и логическим запросам) в
сравниваемых системах удалось найти эти
документы.
Если же поиск будет вести “рядовой”
пользователь, то он может так и не найти эти
документы и будет считать, что они не
существуют в данной базе данных или вообще
в законодательстве.
Детальное описание этого
эксперимента выходит за рамки данной
статьи и может быть предметом отдельной
публикации.
Краткое описание работы пользователя с
системой “ВердиктЪ”
Подробное описание порядка
работы пользователя с системой изложено в
Руководстве пользователя [4], здесь же мы
рассмотрим схематично лишь основные
фрагменты этого руководства.
Установка системы на компьютер
пользователя производит представитель
фирмы-разработчика системы.
Для установки системы “ВЕРДИКТЪ”
требуется компьютер со следующими
минимальными значениями характеристик:
процессор уровня IBM486 (желательно Pentium), 8 Мб
оперативной памяти (желательно 16 Мб и более),
200 Мб и более на жестком диске (винчестере) (в
зависимости от количества и состава баз
данных), оперативная система Microsoft Windows 95
OSR/98/NT (любая версия — русская,
паневропейская или американская).
Примечание. Желательно
произвести установку баз данных системы на
компьютер с файловой системой FAT32, так как
это уменьшит требуемый объем памяти для баз
данных на винчестере.
Система защищена паролем и
имеет защиту от копирования. Поэтому
перенос ее на другой компьютер требует
новой установки.
После установки системы “ВЕРДИКТЪ”
на экране монитора появляется основная
панель управления системой (см. рис. 2).
На рис. 2. видны два основных поля.
В первом (верхнем) поле пользователь
выбирает (с помощью мыши) нужную ему базу
данных.
Во втором поле пользователь
вводит текст своего запроса на
естественном русском языке.
Справа от полей имеются три
кнопки.
Нажав (мышью) на кнопку “История
запросов”, пользователь может вывести на
экран всю историю (тексты) заданных им (или
другими пользователями) запросов к данному
моменту времени.
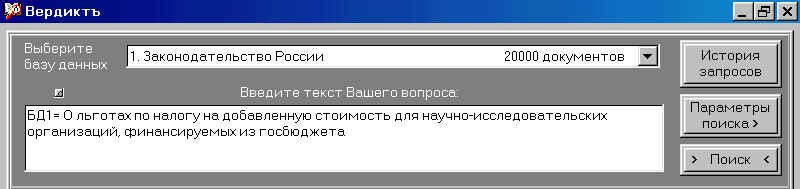
Рис. 2. Основная панель
управления системой.
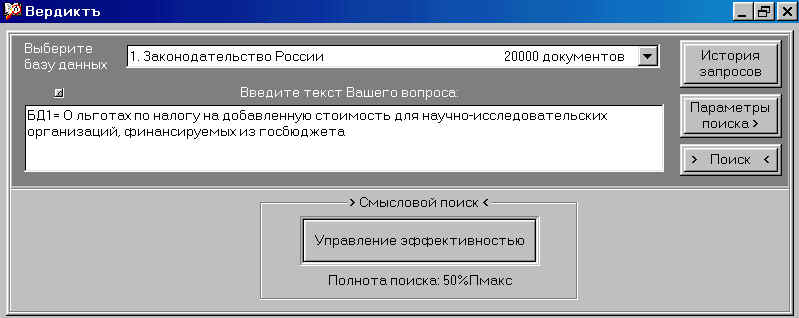
Рис. 3.
Расширенная панель управления системой
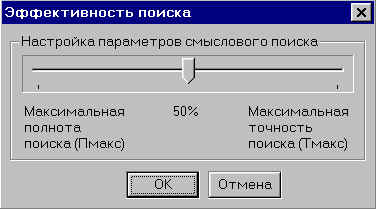
Рис. 4.
Панель управления эффективностью поиска
Кнопка “Параметры поиска”
позволяет вывести на экран монитора
расширенную панель управления, содержащую
дополнительную кнопку, позволяющую
управлять эффективностью поиска (см. рис. 3).
Нажав на кнопку “Управление
эффективностью”, пользователь вызывает на
экран Панель управления эффективностью
поиска (см. рис. 4).
Передвигая мышью движок по
шкале “Полнота-Точность”, пользователь
может оперативно менять полноту и точность
поиска.
Выбрав требуемые значения
полноты и точности поиска (нажав на кнопку
“ОК”), пользователь нажимает на кнопку “Поиск”
основной панели управления (рис. 2, 3).
Система производит поиск
документов и выводит его результат на
Панель результатов поиска (см. рис. 5).
Результаты поиска приведены в
нижней части панели в виде таблицы.
В первом столбце таблицы указан
служебный (внутрисистемный) номер
документа.
Во втором столбце указана
величина степени смыслового соответствия
запроса и документа, при этом все документы
отсортированы (отранжированы) по убыванию
степени смыслового соответствия запросу.
Это позволяет уменьшить время
просмотра и анализа текстов найденных
документов, так как, просмотрев несколько
первых документов, пользователь может
прекратить просмотр и анализ последующих
документов.
Степень смыслового
соответствия вычисляется по критерию
смыслового соответствия, учитывающего
различные параметры текста документа и
запроса. Примеры аналогичных критериев и их
сравнение можно найти в работе [5].
В третьем столбце указана
служебная информация. В четвёртом столбце
указан факт нахождения системой документа.
В предпоследнем столбце указан
объем документов в байтах. В последнем —
дата обновления документа.
Для просмотра текста документа
надо выбрать мышью требуемый документ и
нажать на кнопку “Просмотреть” или на
клавишу “Enter”.
Система обращается к редактору
“Word” и выводит на экран текст найденного
документа.
При этом на экран выводится
Панель просмотра текста документа (рис. 6).
Для облегчения степени
визуальной оценки соответствия найденного
документа запросу все слова запроса
выделяются в тексте документа красным
цветом.
При этом на экран выводится, в
первую очередь, тот фрагмент документа, где
компактно появляются слова запроса.
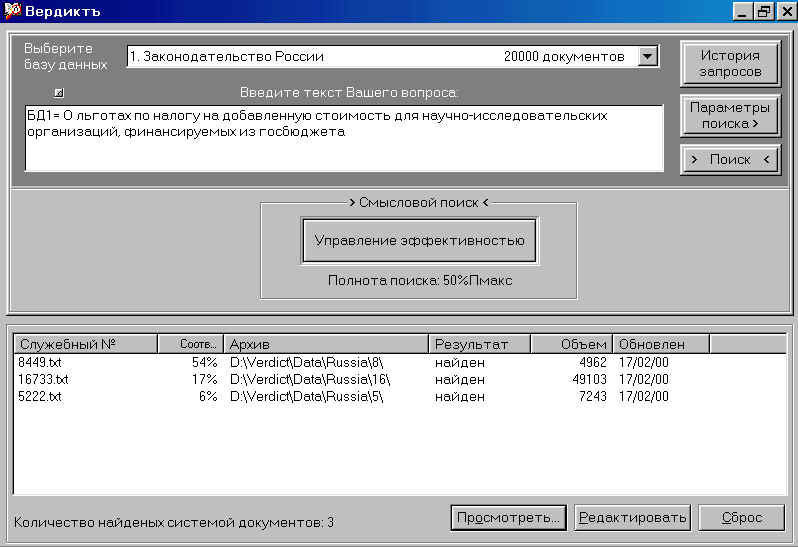
Рис. 5. Панель результатов
поиска
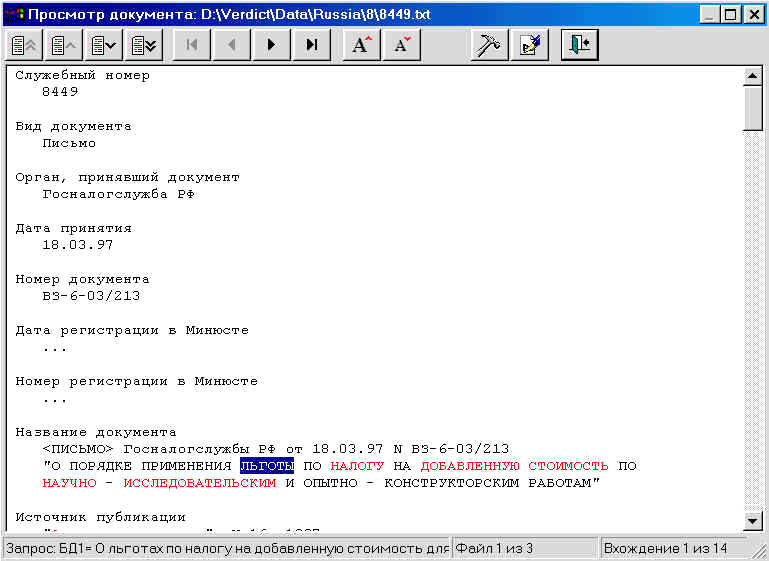
Рис. 6. Панель просмотра
текста документа
В верхней части Панели
просмотра имеется кнопка, которая
позволяет изменить количество выделенных
красным цветом слов в тексте документа.
Нажимая на эту кнопку мышью,
можно вывести на экран Панель подсветки
слов запроса (см. рис. 7).
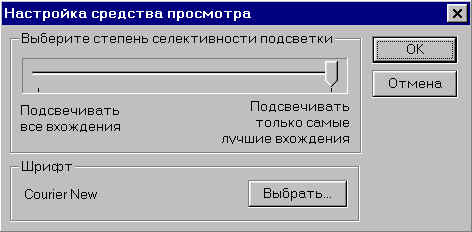
Рис. 7. Панель подсветки
слов запроса
Передвигая движок шкалы, можно
увеличивать или уменьшать число
подсвечиваемых слов.
Для перехода от одного
найденного документа к другому документу
можно использовать комбинации так
называемых “горячих” клавиш клавиатуры:
-
F4 — переход
к следующему документу;
-
F3 — переход
к предыдущему документу;
-
Ctrl+F3 — переход
к первому найденному документу (можно
клавишей “Home”);
-
Ctrl+F4 — переход
к последнему найденному документу (можно
клавишей “End”).
Можно также переходить от
одного выделенного слова к другим,
используя клавиши:
-
F6 — переход
к следующему слову внутри найденного
документа;
-
F5 — переход
к предыдущему слову;
-
Ctrl+F5 — переход
к первому выделенному слову;
-
Ctrl+F6 — переход
к последнему выделенному слову.
Редактирование найденных
документов осуществляется путем нажатия
кнопки “Редактировать” (см. рис. 5 “Панель
результатов поиска”).
При этом вызывается текстовый
редактор Microsoft Word.
Для печати и редактирования
полного текста документа или его фрагмента
используются стандартные функции
редактора Word.
Базы данных системы
Единицей хранения информации в
системе является документ, который
формально состоит из двух частей:
-
перечня
реквизитов, которые представляют собой
некоторые формальные справочные данные о
документе (номер, дата, вид документа, и т.п.).
-
и,
соответственно, сам полный текст
документа.
Все документы хранятся в базах
данных. Каждая база данных имеет своё имя и
представляет собой множество документов
одной тематической направленности и одного
перечня и состава реквизитов.
Каждая база данных системы
содержит два основных файла: текстовый и
индексный. Текстовый файл содержит полные
тексты документов и их реквизиты. Индексный
файл содержит вспомогательную служебную
информацию, позволяющую существенно
уменьшить время поиска документов.
В системе может поддерживаться
произвольное количество баз данных
произвольного размера. Ограничением здесь
является доступный объём памяти на жёстком
магнитном диске.
Совокупность баз данных
образует информационный фонд системы,
который из соображений экономии памяти
содержит два фонда:
Тематика баз данных может быть
произвольной. Наиболее часто запрашиваемые
пользователями базы данных в Москве
представлены следующими именами:
-
Федеральное
законодательство России;
-
Ведомственное
законодательство России;
-
Законодательство
Москвы;
-
Законодательство
Московской области;
-
Арбитражное
законодательство и практика;
-
Законодательство
по налогам и бухучёту;
-
Консультации
бухгалтеров экспертами;
-
Типовые
формы правовых и деловых документов.
Разработчик может также
сформировать и поставить базы данных и по
другим тематическим направлениям (кроме
указанных в перечне) по отдельной заявке
заказчика. Как правило, разработчик
поставляет пользователю базы данных только
из рабочего фонда.
Базы данных архивного фонда
могут быть поставлены по дополнительному
соглашению с пользователем.
Периодичность обновления баз
данных у пользователей может быть
недельной, двухнедельной, месячной и реже — по
их желанию.
Примеры поисковых запросов
При поиске документов возможны
различные исходные ситуации. Как правило,
пользователь не помнит точных формальных
характеристик (реквизитов) документов,
таких как: вид документа, номер и дата
документа, название документа и т.п.
В этом случае он представляет
себе лишь тематический смысл своей
информационной потребности, которую ему
легче всего выразить словом, а чаще фразой
или предложением на естественном (неформализованном)
русском языке.
Именно эту возможность
наиболее эффективно обеспечивает система
“ВЕРДИКТЪ” по сравнению с другими
системами, в которых больше развиты
средства поиска по реквизитам.
Приведём пример поиска по
запросу в этом случае.
В поле “Введите
текст вашего запроса” на рис. 1 вводим
текст запроса: “О льготах по налогу на
добавленную стоимость для научно-исследовательских
организаций, финансируемых из госбюджета”.
Запрос можно задать точно в этом виде, то
есть запрос задаётся на естественном
русском языке.
-
Устанавливаем
значение полноты и точности поиска Т = П = 50%,
поскольку заранее не известно, сколько
нужных и ложных документов будет в ответе
системы.
-
Нажимаем
на кнопку “Поиск” (см. рис. 1).
-
Через 5 сек.
система находит три документа и выводит
их на экран (см.рис. 5).
На первом месте в списке
документов стоит наиболее соответствующий
запросу документ. (54%).
Нажимая на кнопку “Просмотреть”
или на клавишу “Enter”, выводим его текст на
экран (см. рис. 6). Поиск закончен, так как
степень соответствия других документов
гораздо ниже, поэтому их можно не смотреть
или, поскольку их немного, то просмотреть из
любопытства.
Для сравнения приведём пример
поиска по этому же запросу в системе “Консультант+”.
Запрос задаётся формализованно
в виде: льгот+налог+добавл+стоимост+научн+организац+финансир+госбюджет.
Система “Консультант+” ищет примерно 90 сек.,
а затем выдаёт сообщение, что документ не
найден.
Система “ВЕРДИКТЪ” позволяет
производить поиск также и по реквизитам,
если они уже известны пользователю и ему
требуется просмотреть их тексты и уточнить
некоторые детали. Такая ситуация
встречается гораздо реже, когда
пользователь часто работает с этими
документами.
Например, известны номер и дата
документа. Для поиска в этом случае
необходимо:
-
В поле “Введите
текст вашего запроса” вводим имена
реквизитов и их значения, то есть запрос в
виде: номер документа 1–16/2095 от 28.12.94. (здесь
номер документа — имя реквизита,
дата вводится как формализованное число,
которое принято использовать в
документах).
-
Устанавливаем
точность поиска Т=Т макс и нажимаем
кнопку “Поиск”.
При этом будет найден документ с
названием: “Письмо Роскомзема от 28.12.94. №
1–16/2095 “О сроках уплаты земельного налога””.
Аналогично производится поиск
по другим реквизитам, при этом в поле
запроса необходимо указать имя реквизита и
его значение.
Также производится поиск по
названию документа, поскольку оно выделено
в системе как самостоятельный реквизит. В
поле запроса указывается имя реквизита, то
есть слово “Название”, и далее возможные
слова или фразы текста названия.
Основные объёмно-временные
характеристики системы
Система имеет следующие
основные характеристики по максимальному
размеру документа и запроса, объёму баз
данных и времени поиска.
1.
Максимальный размер документа-до 5 Мб (то
есть до 5 000 000 букв (или цифр), что
составляет примерно 2 500 страниц формата
А4).
2.
Максимальная длина текста запроса-до 0,5 Кб (то
есть до 512 букв или примерно до 64 слов).
3.
Максимальный объём баз данных-практически
не ограничен и определяется суммарным
объёмом нормативных документов и доступным
объёмом памяти на жёстком магнитном диске (винчестере).
4.
Время (быстродействие) поиска составляет
3–10 секунд для объёма баз данных около 400 Мб
и зависит от длины запроса и требований
пользователя к полноте и точности поиска.
Выводы
1.
Система “ВЕРДИКТЪ” представляет собой
новое поколение правовых информационных
систем и обеспечивает возможность
интеллектуального поиска по запросам на
естественном русском языке. Это
существенно уменьшает вероятность ошибок
пользователя при задании им запросов для
поиска документов по их тексту.
2.
Вероятность нахождения системой требуемых
документов гораздо выше, чем в традиционных
системах.
3.
Вероятность выдачи системой ложных
документов гораздо ниже, чем в традиционных
системах.
4.
Время поиска (машинное + ручное) в системе “ВЕРДИКТЪ”
существенно меньше (в 20 и более раз), чем в
традиционных системах.
5.
Использование естественного языка
запросов существенно снижает требования к
“компьютерной” и “математической”
подготовке пользователя, так как система не
требует пользования логическими запросами
и полного совпадения слова запроса со
словами документов.
Следовательно, система
становится более “дружественной”,
поскольку психологически является более
доступной для пользователей любого уровня
иерархии в руководстве предприятием. Она
также проста в освоении и эксплуатации.
Литература.
-
1.
Сэлтон Г. Автоматическая обработка,
хранение и поиск информации — М.,:Сов.
радио, 1973 г.
-
2.
Налимов В.В. Вероятностная модель языка. О
соотношении естественных и искусственных
языков. — М.,:Наука, 1979 г.
-
3.
Петрусь А.В. Эффективность документальных
ИПС с позиций теории статистических
решений”-М.,: НТИ, серия 2, № 4, 1987 г.
-
4.
Интеллектуальная естественно-языковая
правовая система “ВЕРДИКТЪ”. Руководство
пользователя.— Научно-производственная
фирма “КОНТЭКС”, Москва, 1999 г.
-
5.
A.V.Petrus “Graph-analists of the relevancy criteria in documentary
information retrieval systems”—Automatic Documentation and mathematical
linguistics, vol 17, ¹ 4, рр. 13–28, 1984 у. Allerton press Inc., New
York.
Петрусь А.В. — генеральный
директор,
к.т.н., доцент,
Петрусь А.А. — программист,
Стыскин И.Е. — программист
Научно-производственная
фирма “КОНТЭКС”:
Телефон:
(095) 963–49–71
Тел./факс:
(095) 964–86–28
Copyright © 1994-2016 ООО "К-Пресс"
