 |
Технология Клиент-Сервер 1998'2
|
|
|
Перенос
приложений “клиент/сервер” на Web
Эндрю МакКей
Где вы и куда стремитесь
Сейчас все суетятся по
поводу переноса своих приложений клиент/сервер
на Web. Весьма похвальное решение, но что конкретно
это означает? Почему это делается? Как все это
будет работать? Попробуем разобраться.
Изменяющаяся роль информационных
технологий
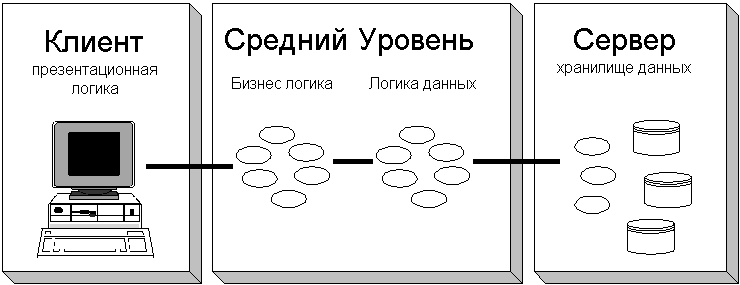
Перенос на Web означает, что
мы переносим архитектуру клиент/сервер
откуда-то. Большинство приложений можно
организовать (с точки зрения архитектуры),
используя четыре уровня: презентационная логика,
коммерческая логика, логика данных и массивы
данных. Реализация клиент/сервер размещает
презентационную и коммерческую логику на
клиенте, а логику и массивы данных - на сервере.
Однако, такая расстановка приводит к некоторым
ограничениям:
• Сложность клиента,
автоматическое обслуживание которого сложно и
дорого.
• Коммерческая логика
не может быть распределена между многими
клиентами.
• Изоляция в целях
разработки логических компонентов разного
направления недостаточно дифференцирована.
• Нет общей абстрактной
логики, которая могла бы приспосабливаться к
неоднородным средам хранения данных.
• Технология
клиент/сервер в стандартном своем варианте не
поддерживает Интернет.
Это - старые проблемы, в
связи с которыми информационные технологии
обратились к решениям с трехуровневой
архитектурой. С появлением Web мы, в конечном
итоге, получили стоимостно-эффективный ответ на
эти вопросы.
Недавнее появление Web
совпадает с изменением стратегической роли
организаций информационных технологий в
успешной деятельности предприятий. Рассмотрим
произошедшие изменения.
Взаимозависимость корпоративной
и информационной стратегий
Информация – это ключ к
конкурентоспособности многих сегодняшних
отраслей. Разумеется, очень важно создать лучшую
мышеловку, но затем ее ведь нужно продать. Чтобы
продать ее, необходимо успеть до вашего
конкурента узнать, кому она нужна вообще.
Технологии должны своевременно предоставлять
подобную информацию. Они становятся мостом между
предприятием и потребителем, а раз так, то и
стратегической частью управления предприятием.
Информационные технологии поменяли свою роль
обслуживания работы предприятия на роль
партнера в изначальной разработке стратегии.
Реакция на изменения
Сегодня лучшей будет
мышеловка, рассчитанная на умнеющую час от часа
мышь. Ключевым моментом в этом случае является
приспособляемость. В организациях тоже
постоянно происходят изменения. Технология,
которую избрала организация, должна суметь
быстро отреагировать на изменения,
подстроившись под определенные требования.
Говоря об изменениях, при
выборе технологии нельзя проигнорировать
удобство коммерческой деятельности с
использованием Интернет. Однако, такое удобство
приводит к появлению другой переменной –
непредсказуемости использования, к которой
приведет развитие новых технологий.
Защита инвестиций в технологию
Любое технологическое
изменение, сделанное сегодня, успешно, только
если оно минимально влияет на существующие
инвестиции. Ни один отдел информационных
технологий больше не хочет слышать такого
страшного слова “устарело”, поскольку это
приведет к повторному обучению персонала уже
другим, более новым технологиям. По мере развития
отрасли, в значительной степени ключевой частью
каждого нового решения является способность к
наследованию информации. Это касается не только
логики и данных приложения, но и обучения
разработке. Информационные отделы каждый раз при
создании нового приложения учитывают уже
имеющиеся наработки. Никто не сможет создать все
с нуля.
Уменьшение затрат и риска
Среди множества современных
производителей информационных технологий нет ни
одного, указывающего затраты, связанные с
разработкой приложений. Цена, которая указана –
это лишь единовременные затраты. То, что смущает
– это последующее распределение и обслуживание
приложений. Установка и обслуживание приложения
на каждой клиентской машине в интранет или
экстранет чрезвычайно дорого, и с ростом
организаций и их глобализации эти затраты
возрастают еще больше.
Кроме того, сегодняшние
организации не хотят участвовать в рискованных
затеях, считая, что что-то новое работает лучше
только первое время. Таким ”чем-то новым” среди
постоянных распределенных платформ является Web,
который продолжает находиться в процессе
становления. Какая из
компонентно-ориентированных модель более
приемлема? Какой язык следует использовать?
Ключом к этому является уменьшение риска – то,
что будет целью всех будущих разработок.
Решение на основе Web-платформы
Сейчас мы знаем, откуда мы
двигаемся и почему, и настало время ответить на
вопрос – куда? К Web - платформе для критических,
ориентированных на пользователя,
распределенных, открытых, настраиваемых,
высокопродуктивных приложений; в конце концов - к
платформе для предприятий, использующих
технологии, увеличивающие их
конкурентоспособность.
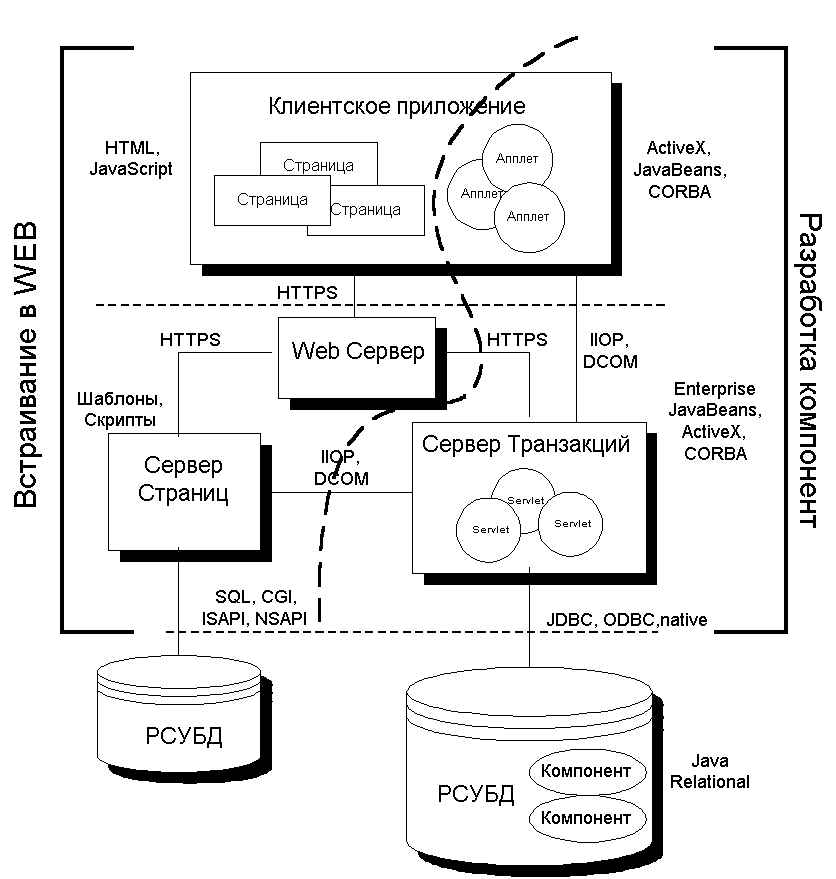
Рис. 2: Архитектура распределения по Web
распределенного приложения для решения
критически важных задач.
Распределение
Перед появлением технологии
“клиент/сервер” работали на центральной машине,
а пользователи подключались через терминал.
Потом в каждом отделе появились РС и специалисты
по пользовательским приложениям в Lotus и dBase. РС
привлекали тем, что они увеличивали гибкость
локальных пользователей – они предлагали
проверенный пользовательский интерфейс и среды
разработки с более коротким временем обмена.
Распределение корпоративных данных и
безопасность были на втором плане, в правилах
царила анархия. После этого появилась технология
“клиент/сервер”, которая принесла лучшее от
поставщиков информационных технологий и в
совокупности с локальными РС-средами
превратилась в интегрированное решение.
То же самое происходит
снова. У кого из вас есть корпоративный Web-сайт,
который разрабатывался не группой
информационных технологий – скажем, отделом по
маркетингу, или внутренние Web-сайты,
разработанные отдельными отделами? Сколько из
этих сайтов совместно используют корпоративные
данные? Сколько из них защищено? Случай тот же,
отличия только в среде. Информационным
технологиям нужен новый подход, который бы
одновременно учитывал пользовательский
интерфейс, ориентированный на потребителя и
распределенную архитектуру Web со всеми,
присущими информационной среде
характеристиками – доступ к данным,
безопасность, быстродействие, тестирование.
Ответом является трехуровневая архитектура,
показанная на рисунке 1.
В этом сценарии
коммерческая логика и общая, абстрактная логика
данных находятся на среднем уровне, что и
является сутью этой архитектуры. Помните наш
список проблем архитектуры клиент/сервер? Здесь
они решены.
• Клиент является
простым и легко, автоматически, обслуживается во
время работы.
• Коммерческая логика
может совместно использоваться многими
клиентами.
• Лучшая изоляция
различных логических компонентов позволяет
графическим дизайнерам, разработчикам
коммерческой логики и аналитикам баз данных
сконцентрироваться на решении вопросов в своих
областях.
• Общий, логически
абстрактный интерфейс разнородных источников
данных эффективно изолирует определенные
массивы данных от общей программы доступа к
данным.
• Архитектура работает
по интранет, экстранет и Интернет.
Средний уровень работает
как сервер, обычно называемым сервером
приложения.
Открытость
Web - это среда, открытая по
своей природе. Приложения собираются из повторно
используемых компонентов. Эти компоненты
“склеиваются” стандартным языком,
распределяются по уровням (общающимся между
собой по стандартным протоколам), визуализируют
информацию, пользуясь независящим от платформы и
операционной системы стандартным
пользовательским интерфейсом. Теперь это
открытая среда! В целом неплохо. Но все зависит от
того, что мы называем стандартом.
На самом деле существует три
конкурирующих стандарта. Сейчас существует три
модели компонентов: ActiveX, JavaBeans и CORBA. Каждая
модель имеет свой протокол связи: COM и DCOM - для ActiveX
и IIOP – для JavaBeans и CORBA. “Склеивающими” являются
стандартные языки сценариев - HTML и JavaScript, но они
тоже имеют свои ответвления. Динамический HTML, к
примеру, полностью поддерживается не всеми
браузерами, а JavaScript имеет, по меньшей мере, три
конкурирующие модели ответвлений: страницы Active
Server, LiveWire и PowerDynamo.
Кажется наиболее
прагматичным выбрать какую-то одну из этих
моделей и работать с ней, что, по меньшей мере,
позволит использовать саму модель и
существующие стандарты. Однако лучшим является
другой подход – можно разрабатывать на
нейтральном уровне вне зависимости от
стандартов моделей, а затем с помощью средства
разработки сгенерировать одну из них. Кроме того,
вы можете ограничить выбор сервера приложения
таким, который поддерживал бы более чем одну
модель компонентов. На самом деле сейчас
неизвестно, кто победит. Для уменьшения риска
неверного выбора модели предоставьте среде
разработки сделать это за вас. Оставьте среду
разработки открытой.
Адаптивность
Адаптивность среды
разработки весьма важна, но адаптивность среды
распределения важна не менее. Преимущества
выбора сервера приложения, поддерживающего
более одной компонентной модели уже упоминалась,
но, кроме того, необходима и адаптивность уровней
клиента и сервера данных.
Наша трехуровневая
архитектура - это Web-решение, поэтому клиент
постоянно имеет браузер. Это означает наличие, по
меньшей мере, одной HTML-страницы, которая работает
как механизм распределения остальной
презентационной логики. Сама презентационная
логика, однако, может варьировать от полностью
HTML- и JavaScript-решения до решения, реализованного
как ActiveX или JavaBeans с единственным окном HTML,
обслуживающим первый компонент для получения
приложения клиентом.
Какая часть презентационной
логики – сценарий, а какая – компонент зависит
от выбора, сделанного пользователями между
функциональностью и полосой пропускания.
Полностью HTML- и JavaScript-решение может работать
только с уровнями, поддерживаемыми языками.
Динамический HTML - это попытка расширить
функциональность, но это по-прежнему набор
маркеров и простых сценариев. Функциональность
лучше всего реализуется компонентами. Однако и
это небесспорно, поскольку сами компоненты
сравнительно больше, и обслуживание компонентов
предъявляет большие запросы к полосе
пропускания. Некоторые сайты не используют Java на
своих Web-страницах именно по этой причине.
Лучшего решения нет. Каждый
информационный отдел решает сам, сколько
неудобств он может заставить терпеть своих
пользователей. Этот выбор основывается не только
на том, что технически доступно в данный момент;
скорее, решающее значение имеют затраты - какую
полосу пропускания может оплатить предприятие.
Имеющаяся полоса пропускания редко бывает
оптимально приемлемой. По этой причине среда
разработки должна быть достаточно гибкой. Эта
гибкость может быть достигнута либо
настраиваемым распределением разрабатываемой
программы, либо использованием сильно
интегрированного набора средств разработки.
Приложения, ориентированные на
потребителя
С дизайном
пользовательского интерфейса при появлении Web
случилось следующее – он действительно
усовершенствовался. Это может показаться
неправдоподобным, в том смысле, что может
привести к путанице в Интернет, однако, сайты,
которые функциональны, интуитивно-понятны и
продуктивны, на самом деле существуют. Причина
проста: в Web нет таких понятий, как принудительное
включение или руководство пользователя. Хороший
Web-сайт сначала должен заинтересовать
пользователей, а затем – удержать их.
Для приложений передачи
информации это усовершенствование заключается в
предоставлении приемлемого качества
пользовательского интерфейса. Они используют
интерфейсы новых, интуитивно-понятных и
графически-ориентированных стандартов, что
придает больше активности пользователям,
подключающимся к ним или людям,
взаимодействующим с ними. Например, вместо того,
чтобы общаться с кем-то по телефону, я могу сам
войти на домашнюю страницу и оставить или
получить информацию. Это справедливо, будь я
потребителем услуги (скажем, если передаю
посылку с курьером) или работником, имеющим
доступ к информации по кадрам.
Архитектура распределения
Итак, как же все это выглядит
вкупе? Давайте рассмотрим каждый из этих пунктов
в условиях трех различных сценариев:
Web-публикация, обработка данных в Web и Web OLTP (OLTP –
оперативная обработка транзакций). Заметьте, что
корпоративное приложение в целом, вероятно,
будет использовать все три сценария (Рис. 2).
Web-публикация
Поговорим об наиболее
частой реализации Web – стандартном Web-сайте. В
данном случае Web-сервер просто обслуживает
презентационное содержание браузера как
статичные HTML-страницы. Несмотря на то, что это не
показано, Web-сервер берет эти страницы
непосредственно из файловой системы, в которой
находится сайт. Кроме того, могут использоваться
презентационные апплеты, ActiveX или JavaBeans,
увеличивающих презентационные возможности, но
такое увеличение возможностей происходило бы
только через страницу или компонент. Соединения
с каким-либо сервером транзакций данных здесь
нет.
Часть архитектуры,
предназначенной для Web-публикации – это просто
приложение-клиент, которое содержит HTML-страницы
и, возможно, апплеты, подключающиеся через HTTP (или
защищенный HTTP) к Web-серверу.
Обработка данных в Web
Обработка данных в Web
увеличивает возможности доступа к данным
стандартного Web-сайта. Существует множество
видов данных и здесь важны различия между ними.
Для своей задачи мы можем разделить данные на две
группы, которые существенно отличаются по
способу доступа к ним. Стандартное OLTP-приложение
отдает большую часть времени получению и
обработке базовых корпоративных данных –
информации, которая определяет бизнес компании,
например потребители и извещения. Эти данные
постоянно считываются и записываются.
Быстродействие является решающим фактором.
Периферийные данные играют
поддерживающую роль и обычно только считываются
– например, файлы помощи, документация,
информация о пользователях и метаданные.
Приложение тратит на доступ к таким данным
немного времени и, в любом случае, они имеют
небольшой объем. Более важно то, что эти данные, в
отличие от базовых, в транзакциях не участвуют.
Такое разграничение важно, поскольку разницей в
работе между простыми данными и OLTP является
наличие транзакций. Базовые данные – это
источник жизненной силы организации и поэтому
нуждаются в поддержке обработки запросов. Но для
периферийных данных поддержка транзакций важна
не в такой мере. Обработка данных Web фокусируется
на периферийных данных, а Web OLTP – на базовых.
Та часть архитектуры, где
реализуется обработка данных Web, расширяет
возможности Web-публикации до включения в неё
серверов страниц и серверов релевантных данных.
Заметьте, что связь между клиентом и средним
уровнем по-прежнему осуществляется Web-сервером
по HTTP, а соединение с сервером данных – с помощью
SQL- или обычному Web-протоколу доступа к данным.
Теперь у нас есть среда, которая может считывать
и записывать данные и может запускать HTML (как
шаблоны) и JavaScript на сервере среднего уровня, но
все еще ограничена парадигмой, ориентированной
на страницы и HTTP.
Web OLTP
Web OLTP - это завершенное
решение. В этом сценарии мы получили внешнюю
часть, то есть мы соединились с помощью Web-сервера
и HTTP с серверами данных.
Мы использовали правильную
коммерческую логику – компоненты управляются
средой сервера среднего уровня. Такие servlet
обеспечивают коммерческую логику и общую,
абстрактную логику данных. Они соединяются с
серверами данных, используя ODBC, JDBC или
собственные протоколы серверов (типа TDS).
Определяющими параметрами здесь являются
быстродействие, способность к транзакциям и
масштабируемость.
Со стороны клиента мы
использовали компоненты клиента, соединяющиеся
напрямую с servlet сервера транзакций. Это – внешняя
часть: апплеты “общаются” с servlet посредством
коммуникационной модели, поддерживающей
компоненты (DCOM, IIOP) или как поток табличных
данных. Заметьте, нет ничего, что могло бы
воспрепятствовать Web-серверу или серверу страниц
соединяться напрямую с сервером транзакций.
Хороший сервер транзакций должен поддерживать
HTTP и HTTPS.?
Copyright © 1994-2016 ООО "К-Пресс"
