 |
Технология Клиент-Сервер 1999'2
|
|
|
SQL-серверы, современное состояние
В.Чистяков
Сейчас модными являются разговоры о
многоуровневой (как минимум, 3-х уровневой)
архитектуре построения информационных систем. В
общем-то, можно согласиться с перспективностью
этого подхода. Но в пылу борьбы сторонников
нового подхода с «древним пережитком», 2-х
уровневой архитектурой клиент сервер, многие
забывают, что новый подход вообще не
предоставляет способов надежного и
производительного хранения информации. В этом
обзоре мы хотим обратить ваше внимание на
заслуженно завоевавшие доверие и уважения
средства хранения и обработки информации. Как вы
уже наверное догадались, далее речь пойдет о
реляционных системах управления базами данных
(РСУБД) типа клиент-сервер (в простонародье -
SQL-серверах).
SQL-серверы прошли путь от систем, позволяющих
оптимизировать доступ к табличным данным, до
серверов приложений с богатым серверным языком и
средствами межсерверной коммуникации.
Большинство из них обзавелись графическими
средствами администрирования, которые в
диалоговом режиме позволяют простым
пользователям производить сложные и
ответственные операции. И хотя на сегодня
вмешательство современных многоуровневых
технологий опять заставляет SQL-серверы отступить
на позиции хранилищ данных, мощь SQL-серверов
стала настолько очевидным фактором, что
игнорировать их в своих разработках просто
расточительно. Вы можете сказать, что уже есть
объектно-ориентированные системы управления БД,
но, во первых, они не достигают таких же, как
РСУБД, высоких показателей производительности, а
во вторых, они не стандартизированы (нет
стандарта ни на сами системы, ни на язык,
позволяющий ими управлять). К тому же многие
РСУБД и сами постепенно смещаются в сторону
объектной ориентации, сохраняя при этом все
лучшее от РСУБД. Как бы то ни было, а большинство
людей привыкло представлять информацию в
табличном виде, да и математическая база под
реляционную модель подведена более
фундаментально. В общем, практика показала, что
ни одна из известных фирм (за исключением CA) не
перешла полностью на объектно-ориентированную
парадигму.
К середине 1999 года парк SQL-серверов значительно
обновился. Практически все фирмы выпустили новые
версии своих продуктов. В этом обзоре мы
постараемся осветить возможности наиболее
известных серверов, чтобы облегчить вам принятие
решения об использовании того или иного
продукта.
В наши цели не входит выявление лучшего
продукта, хотя обзор минимально необходимых
возможностей и характеристик серверов,
несомненно, будет присутствовать на наших
страницах. От проведения тестов мы отказываемся
еще и потому, что последние скандалы доказали
старую истину: составить объективный тест,
учитывающий возможности всех продуктов и в тоже
время беспристрастный ко всем, практически
невозможно.
Большинство БД в нашей стране содержат таблицы,
число записей в которых обычно не превышают
одного миллиона, а общий объем БД не превышает
нескольких гигабайт. Естественно, в расчет не
берутся БД, содержимое которых получается
автоматически (например – телеметрические
системы), и БД, содержащие большое количество
бинарных объектов (картинок, текстов книг). Зато
количество таблиц растет с неимоверной
скоростью, и на сегодня самая простенькая
система содержит более пяти десятков таблиц, а в
больших иногда насчитывается несколько сотен
таблиц.
Исходя из этого можно сказать, что тесты на
таблице с миллионом записей и тесты на сложных
многотабличных запросах, наряду с чисто
технической информацией, дадут объективную
информацию для разработчика о целесообразности
применения описываемых продуктов в его решениях.
Для наших тестов мы подготовили с помощью ER-Win две
модели. Одну - таблицы TMR, предназначенную для
теста по закачке и обработке миллиона записей (на
Рис. 1 показано её описание).
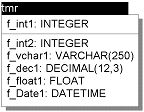
Рис. 1
Диаграмма-описание таблицы TMR
Приводить конкретный скрип нецелесообразно,
так как он значительно зависит от сервера.
Единственное, что можно добавить к описанию этой
диаграммы - эта таблица имеет один уникальный
индекс на первичном ключе (поле f_int1)
целочисленного типа. Мы старались сделать этот
индекс кластерным на тех серверах, которые
поддерживают эту возможность. Для теста
«многотабличных запросов» мы создали вторую
диаграмму (см. Рис. 2.)
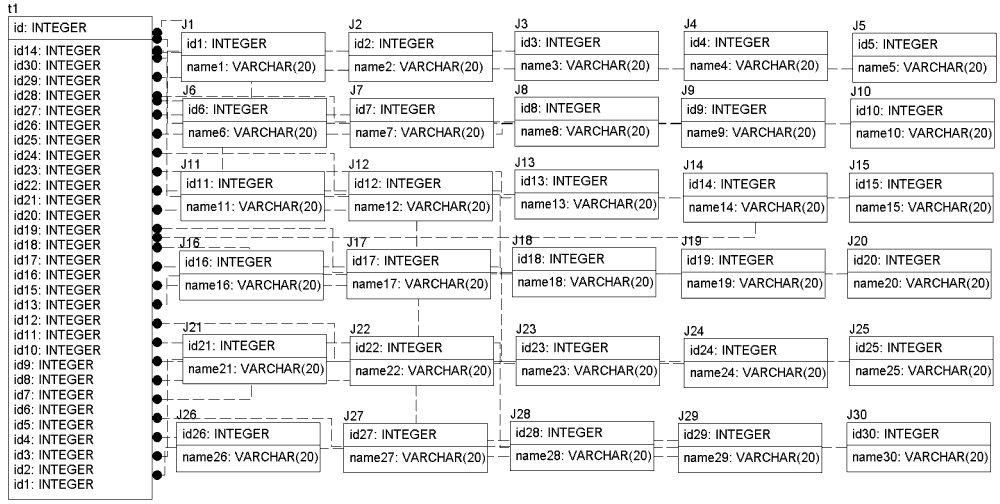
Рис. 2
Диаграмма-описание таблиц для 30-и табличных
запросом
Все поля с именами idx таблицы t1 являются
внешними (foreign) ключами к соответствующей по
номеру таблице Jx (id1 для J1, id2 для J2, … id30 для J30).
Таким образом получается схема «звезда», в
которой есть одна главная таблица «t1» и 30 таблиц,
связанных с первой реляционной зависимостью.
Производя по этим таблицам запросы можно увидеть
скорость действия оптимизатора. Подчеркну -
именно скорость, а не грамотность построения
плана. Знание скорости оптимизатора необходимо
для оценки пригодности того или иного сервера в
системах, вырабатывающих большое количество
динамических SQL-запросов со сложной структурой
запроса и большим количестве таблиц в запросе.
Эти данные могут быть не важны для тех, кто
создает системы для сбора информации в режиме
online и делает только заранее запланированные
запросы (Такое положение складывается из-за того,
что практически все серверы умеют
предкомпилировать запросы или хранимые
процедуры.). Но для систем, производящих сложный
анализ, содержащих универсальные генераторы
отчетов или автоматически генерирующих запросы,
эта характеристика может оказаться решающей.
Сама скорость ничего не значит без получения
правильного плана выполнения запроса. Мы
постараемся привести планы для всех серверов,
хотя понимаем, что разобраться в них без
специальной подготовки и знания конкретного
сервера будет не просто. Чтобы исключить влияние
количества записей в таблицах, мы провели
испытания с разным количеством записей.
Не стоит списывать сервер только потому, что он
имеет менее производительный оптимизатор.
Обычно серверы с менее производительным
оптимизатором значительно более дешевы, менее
притязательны к оборудованию и просты в
администрировании. Исходя из этого их можно
применять в связке с более производительными и,
как следствие, более дорогими серверами. При этом
в отделах ставятся более дешевые серверы,
предназначенные для сбора первичной информации,
а в центральном офисе ставятся дорогие
производительные серверы на многопроцессорных
машинах, в их обязанности входит обработка и
анализ информации.
Если вам не интересны «объемы и количества», то,
возможно, вам окажется интересным рассказ об
архитектурных особенностях и средствах
администрирования представленных в обзоре
серверов. К сожалению, не все фирмы открывают
информацию о конкретных алгоритмах, применяемых
в их продуктах, но то, что мы смогли найти, будет
представлено в этом и последующих номерах.
В обзорах будет обсуждаться проблема создания
и использования хранимых процедур, внешних
процедур и внешних функций. Уточню эти термины.
хранимой процедурой (stored procedure) – мы будем
называть процедуры, написанные на встроенном
языке (обычно - расширение SQL). Такие процедуры
хранятся и обрабатываются непосредственно на
SQL-сервере.
внешние процедуры – процедуры или функции,
написанные на языках программирования общего
пользования. Такие процедуры обычно
подключаются к серверу путем их декларации с
помощью специальных операторов или при помощи
специальных хранимых процедур. внешние
процедуры могут вызываться из хранимых процедур,
как отдельный вызов или в составе SQL-скриптов
(пакетов). Они не могут использоваться как
функции внутри SQL-запросов.
внешние функции - функции, написанные на языках
программирования общего пользования. Главным их
отличием от внешних процедур заключается в том,
что они могут использоваться как функции внутри
SQL-запросов.
В этом номере представлены обзоры по:
InterBase
(IB-Database) 5.5
Centura (Gupta) SQLBase
7.0.1
Microsoft SQL Server 7.0
В следующих номерах будут опубликованы обзоры
по Sybase Adaptive Server Enterprise 11.9, Informix Dynamic Server XX и Oracle 8i.
Copyright © 1994-2016 ООО "К-Пресс"
