 |
Технология Клиент-Сервер 1999'2
|
|
|
Архитектура современного SQL-сервера
Логическая архитектура
Архитектура таблиц и индексов
Данные таблиц хранятся в страницах размером 8
Кбайт. Каждая страница имеет заголовок размером
96 байт, содержащий системную информацию, такую,
как ID таблицы, которой принадлежит страница, а
также указатели на следующую и предыдущую
страницы для связанных страниц. В конце странице
хранятся смещения строк. Остальное место
занимают строки данных.
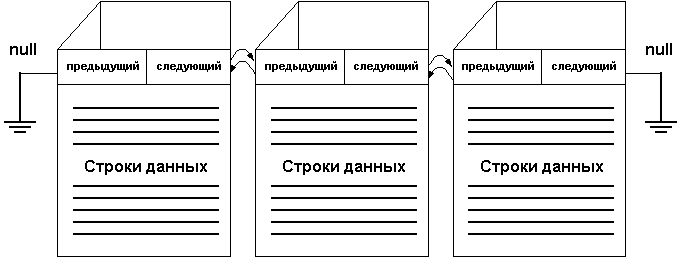
Рис. 1
Для организации данных таблицы SQL Server 7.0
используют один из двух методов:
- Кластерные таблицы – таблицы, содержащие
кластерный индекс.
Строки данных хранятся в последовательности,
соответствующей ключу кластерного индекса.
Страницы данных объединяются в двунаправленный
список. Индекс представляет собой индексную
структуру в виде двоичного дерева (B-tree), что
позволяет быстро находить строки по ключевому
значению кластерного индекса.
- Хипы – таблицы без кластерного индекса.
Строки данных не хранятся в какой-то особенной
последовательности, нет определенной
последовательности и в размещении страниц
данных. Страницы данных не объединены в список.
Кроме того, SQL Server поддерживает до 249
некластерных индексов для каждой таблицы.
Некластерный индекс имеет структуру двоичного
дерева, подобную той, что у кластерного индекса.
Разница состоит в том, что некластерный индекс не
влияет на последовательность строк данных.
Данные в кластерных таблицах размещаются в
соответствии с ключом кластерного индекса.
Определение некластерного индекса для
конкретной таблицы никак не влияет на список
страниц данных в хипе. Страницы данных
продолжают находиться в неупорядоченном
состоянии, пока не определен кластерный индекс.
Страницы, содержащие данные типа text, ntext и image,
управляются как единый список для каждой
таблицы. Все данные text, ntext и image хранятся в
собственном списке страниц.
Для всех списков страниц (как для таблиц, так и
для индексов) в таблице sysindexes содержится
указатель. Каждая таблица имеет список страниц
данных, плюс дополнительные списки страниц для
реализации каждого индекса, определенного для
данной таблицы.
Каждой таблице и индексу соответствует строка
в sysindexes, которая уникально идентифицируется
комбинацией колонки идентификатора объекта (id)
и колонки идентификатора индекса (indid).
Размещением страниц в таблице и индексе
управляет цепочка IAM-страниц. Колонка sysindexes.FirstIAM
указывает на первую IAM-страницу из цепочки
IAM-страниц, которая управляет областью,
предназначенной для таблицы или индекса.
В sysindexes каждая таблица имеет набор строк:
- Для хипа с indid = 0.
Колонка FirstIAM указывает на IAM-цепочку для списка
страниц данных таблицы. Поскольку страницы в списке страниц данных не
объединены, для их поиска сервер использует IAM-страницы.
- Для кластерного индекса с indid = 1.
Колонка root указывает на начало двоичного дерева кластерного
индекса. Сервер использует дерево индекса для поиска страниц данных.
- Для каждого некластерного индекса, созданного
для таблицы.
Значение indid в строках некластерного
индекса может варьировать от 2 до 251. В колонке root
содержится указатель на начало двоичного дерева
некластерного индекса.
- Если в этой таблице есть хотя бы одна колонка
типа text, ntext или image, то в sysindexes
добавляется строка с indid = 255.
Колонка FirstIAM указывает на цепочку IAM-страниц,
управляющую страницами text, ntext или image.
В предыдущих версиях SQL Server, в sysindexes.first
всегда содержался указатель на начало хипа,
начало концевого уровня индекса или начало
цепочки страниц с данными text или image. В SQL
Server 7.0 sysindexes.first используется гораздо меньше.
В предыдущих версиях sysindexes.root в строке с indid =
0 содержался указатель на последнюю страницу
хипа. Теперь sysindexes.root в строке с indid = 0 не
используется.
Хип-структуры
Таблицы, не имеющих имеющие кластерного
индекса, хранят свои данные неупорядочено. Такой
способ хранения называется – хипом. Для хипов в
sysindexes создается по одной строке с indid = 0.
Колонка sysindexes.FirstIAM содержит указатель на первую
страницу в цепочке IAM-страниц. IAM-страницы
помогают управлять областью, предназначенной
для хипа. Для навигации по хипу, SQL Server использует
IAM-страницы. Страницы данных и строки в хипе
расположены хаотически и не объединены друг с
другом. Единственным логическим соединением
между страницами данных являются записи в
IAM-страницах.
Сканирование таблиц (последовательное чтение)
осуществляется следующим образом: читаются
IAM-страниц, на базе информации из IAM-страниц
находятся и читаются экстенты, из экстентов
извлекаются страницы данных, данные из которых
непосредственно обрабатываются. Поскольку IAM
представляет экстенты в той же
последовательности, в которой они содержатся в
файле, последовательное сканирование heap
выполняется от начала файла к его концу.
Сканирование таблицы базирующейся на хипе (не
имеющей кластерного индекса) выполняется
следующим образом:
1. Читается первый IAM первого файла (первой
файловой группы) и сканируются все экстенты
этого IAM.
2. Процесс повторяется с каждым IAM хипа в файле.
3. Действия 1 и 2 повторяются для каждого файла
или файловой группы БД до тех пор, пока не будет
обработан последний IAM для хипа.
Это более эффективно, чем цепочки страниц,
используемые в предыдущих версиях SQL Server, где
цепочка страниц с данными часто размещалась в
файлах БД в случайном порядке. Кроме того, это
значит, что строки теперь не будут возвращаться в
той же последовательности, в какой они были
вставлены.
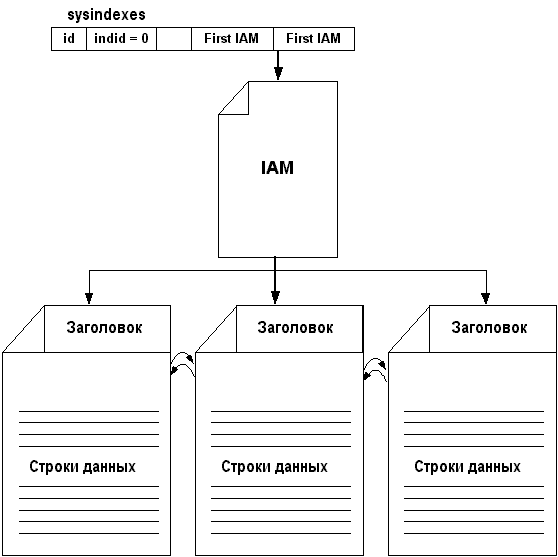
Рис. 2 Структура хранения данных в
таблицах, не имеющих кластерного индекса (хипах).
Кластерные индексы
Для каждого кластерного индекса в sysindexes содержится
одна строка с indid = 1. При наличии кластерного
индекса, страницы в базе данных и строки внутри
них размещаются в ключевой последовательности
кластерного индекса. Все вставки выполняются по
ключевому значению с сохранением
последовательности ключей.
Все типы индексов в MS SQL Server организуются как
двоичное дерево (B-tree). Каждая страница индекса
содержит заголовок страницы, и следующие за ним
строки индекса. Каждая строка индекса содержит
ключевое значение и указатель на другую страницу
или строку данных. Страница индекса в этом случае
называется индексным узлом. Верхний узел
двоичного дерева называется корневым узлом (root
node). Нижние узлы называются концевыми узлами (leaf
node), они связаны вместе двунаправленным списком. В
кластерном индексе страницы данных образуют
концевые узлы. Любой уровень индекса,
расположенный между корневым и концевым узлом,
называется промежуточным уровнем.
Для каждого кластерного индекса в sysindexes содержится
одна строка с indid = 1. При наличии кластерного
индекса, страницы в базе данных и строки внутри
них размещаются в ключевой последовательности
кластерного индекса. Все вставки выполняются по
ключевому значению с сохранением
последовательности ключей.
В случае с кластерным индексом sysindexes.root
указывает на корень кластерного индекса. Для
нахождения диапазона ключевых значений SQL Server
перемещается вниз по индексу, а затем сканирует
страницы данных, используя указатели previous
(предыдущий) и next (следующий) для перехода к
следующей странице.
На Рис. 3 показана структура кластерного индекса.
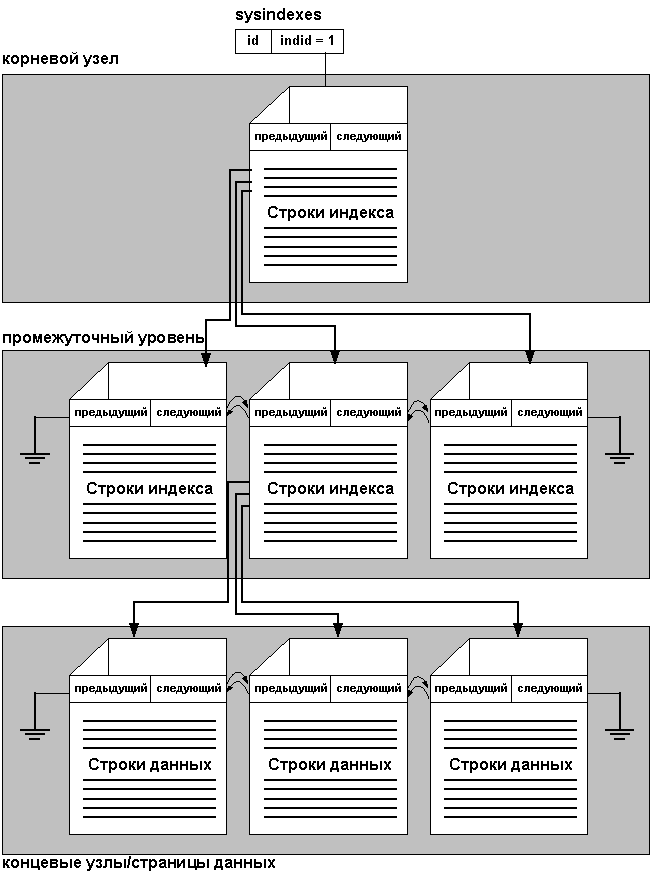
Рис. 3 Структура кластерного индекса.
Некластерный индекс
Некластерный индекс имеет такую же структуру
B-tree, что и кластерный индекс, но есть два
значительных отличия:
- Строки данных не сортированы и не хранятся в
последовательности своих некластерных ключей.
- Концевой уровень некластерного индекса не
содержит страницы данных.
Вместо этого концевые узлы содержат индексные
строки. В каждой индексной строке находятся
значение некластерного ключа и один или более
определитель строки (row locator), который указывает
на строку данных (или диапазон строк, если индекс
не уникален).
Некластерный индекс может быть определен для
любой таблицы, как с кластерным индексом, так и
без него. В MS SQL Server 7.0 определитель строки в
строках кластерного индекса может иметь два
вида:
- Если таблица представляет собой хип (кластерного
индекса нет), то определитель строки является указателем на строку. Указатель
создается из ID-файла, номера страницы и номера строки на этой странице.
Указатель в целом еще известен как Row ID.
- Если таблица имеет кластерный индекс,
определитель строки является ключом кластерного
индекса. Если кластерный индекс не уникален, SQL
Server добавляет внутреннее значение, которое
делает уникальными повторяющиеся ключи. Это
значение скрыто от пользователя; оно создается
для того, чтобы сделать ключи уникальными при
использовании некластерного индекса. SQL Server
извлекает строки данных, выполняя поиск по
кластерному индексу и используя ключ
кластерного индекса, хранящийся в концевой
строке некластерного индекса.
Поскольку некластерные индексы хранят ключи
кластерного индекса как определители строк,
важно, чтобы ключи кластерного индекса были как
можно меньше. Если в таблице есть некластерные
индексы, не следует создавать кластерный индекс
на колонках, содержащих большое количество
данных, или использовать для создания
кластерного индекса несколько колонок.
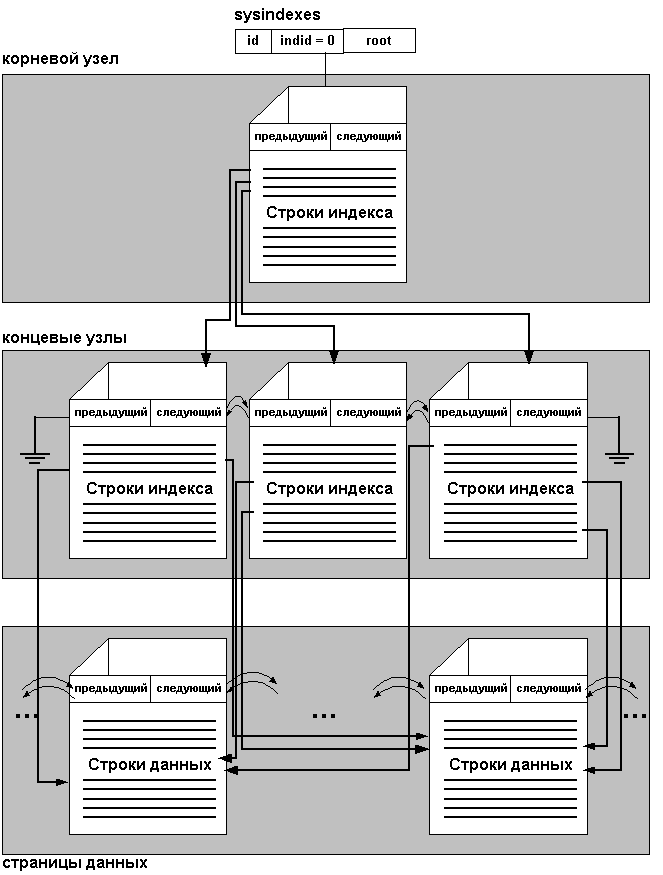
Рис. 4 Структура некластерного индекса.
Статистика распределения
Все индексы имеют статистику распределения,
описывающую избирательность и распределение
ключевых значений в индексе. Избирательность -
это свойство, которое связано с тем, насколько
много строк обычно идентифицируется конкретным
ключевым значением. Уникальный ключ имеет
наивысшую избирательность, а ключевое значение,
идентифицирующее 1000 строк - низкую.
Избирательность и статистика распределения -
величины, используемые в MS SQL Server при обработке
Transact-SQL-запросов для оптимизации навигации по
таблицам. Статистика распределения используется
для прогнозирования того, насколько эффективным
будет индекс при извлечении данных по ключу или
диапазону, указанному в запросе. так же, как
данные типа image, статистика для каждого
индекса не ограничена одной страницей, а
хранится в виде длинной строки битов, занимающей
несколько страниц. Указатель на данные о
распределении содержится в колонке sysindexes.statblob.
Для получения отчета о статистике распределения
для индекса можно использовать выражение DBCC
SHOW_STATISTICS.
Кроме того, статистика распределения может
обрабатываться и для колонок без индекса. Она
может создаваться вручную с помощью выражения
CREATE STATISTICS либо автоматически – оптимизатором
запросов. Число значений статистики для колонок
без индексов ограничивается 249-ю - столько
некластерных индексов может быть у одной
таблицы.
Статистика распределения не должна устаревать.
Она обновляется всегда, когда происходит
значительное число изменений ключей в индексе.
Статистика распределения может обновляться и
вручную, для чего используется выражение UPDATE
STATISTICS. Кроме того, SQL Server 7.0 может определять,
когда статистика распределения устарела, и
обновлять ее автоматически. Для обновления
используется метод, который минимизирует
влияние обновления на работу транзакций.
Типы данных text, ntext и image
Значения типа text, ntext и image не хранятся
как часть строк данных, а образуют отдельный
список страниц. Вместо этого в строку данных
помещается 16-байтный указатель на эти станицы.
Строка, содержащая несколько колонок типа text,
ntext или image, имеет для каждой такой колонки по
одному указателю.
Для хранения данных типа text, ntext и image, каждая
таблица имеет только один список страниц.
Входной точкой для такого списка является строка
в sysindexes, с indid = 255. Колонки, содержащие
данные типа text, ntext и image, хранятся в
страницах последовательно, чередуя данные
разных колонок и строк.
В MS SQL Server 7.0 отдельные страницы text, ntext и image
не ограничены хранением данных только для одной
колонки text, ntext и image. Любая страница из
этого списка может содержать данные относящиеся
как к разным строкам, так и к разным колонкам,
причем даже разных типов.
Пока пользователь работает с данными text, ntext и
image как с единой длинной строкой байтов,
данные в этом формате не сохраняются. Данные
сохраняются в страницах размером 8 Кб, причем не
обязательно, чтобы одна страница следовала за
другой. В SQL Server 7.0 страницы логически
организованы в B-tree-структуру, в то время как
раньше они образовывали цепочку страниц.
Преимущество такой схемы размещения обусловлено
тем, что операции, начинаемые с середины строки
более эффективны. SQL Server 7.0 использует навигацию
по B-tree, в то время как предыдущие версии
использовали менее быстрое сканирование цепочек
страниц. Структура B-tree может слегка изменяться в
зависимости от объема данных (больше или меньше 32
Кб).
Если объем данных меньше 32 Кб, текстовый
указатель указывает на 84-байтную текстовую
корневую структуру. Это образует корневой узел
структуры двоичного дерева. Корневой узел
указывает на блок данных text, ntext или image ().
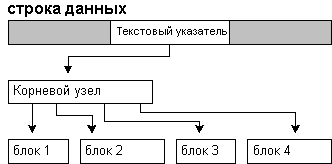
Рис. 5 Структура хранения text, ntext или image
размером менее 32 Кб.
Пока данные колонок text, ntext и image
логически упорядочены в двоичном дереве, и
корневой узел, и отдельные блоки данных
распределены в цепочке страниц text, ntext и image
таблицы. Они так размещаются до тех пор, пока есть
свободное место. Размер каждого блока данных
определяется размером, указанным в приложении.
Маленькие блоки данных комбинируются так, чтобы
заполнить страницу. Если данных меньше, чем 64 Кб,
все они хранятся в корневой структуре.
Например, если приложение сначала записало 1 Кб
данных image, эти данные будут храниться как
первый блок данных image размером 1 Кб для
данной строки. Если после этого приложение
записывает данные image размером 12 Кб, то 7 Кб
комбинируются с первым блоком так, чтобы его
размер стал 8 Кб. Оставшиеся 5 Кб образуют второй
блок данных image (см. ). (Полный размер каждой
страницы text, ntext и image - 8080 байтов данных).

Рис. 6
Поскольку блоки данных text, ntext и image и
корневая структура могут совместно использовать
пространство на одних и тех же страницах text, ntext и
image, SQL Server 7.0 использует меньше места по
сравнению с предыдущими версиями, если размер
данных text, ntext и image мал. Например, если в
колонку text вставляется 20 строк, каждая по 200
байт данных, данные и все корневые структуры
могут поместиться на одной и той же странице
размером 8 Кб.
Если объем данных для одного вхождения в
колонки text, ntext или image превышает 32 Кб, то SQL
Server начинает строить между блоками данных и
корневым узлом промежуточные узлы.
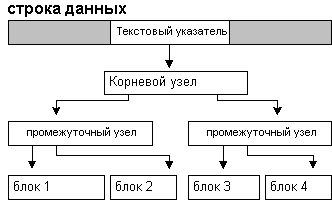
Рис. 7. Структура хранения text, ntext или image
размером более 32 Кб.
Корневая структура и блоки данных в этом случае
размещаются в страницах text, ntext и image так
же, как было описано выше, однако промежуточные
узлы хранятся в страницах, которые не
используются колонками text, ntext и image. Страница,
содержащая промежуточные узлы, содержит их
только для одного значения данных text, ntext или image
в одной строке.
Обработка view
Для SQL-запроса создается единый план
выполнения, даже когда в нем используются view. Для
view планы выполнения не сохраняются, но исходная
информация о нем хранится. Когда SQL-запрос
ссылается на view, анализатор синтаксиса и
оптимизатор анализируют исходную информацию как
для SQL-запроса, так и для view, и преобразуют их в
единичный план выполнения, то есть отдельных
планов для SQL-запросов и view не строится.
Например:
USE Northwind
GO
CREATE VIEW EmployeeName AS
SELECT EmployeeID, LastName, FirstName
FROM Northwind.dbo.Employees
GO
Создав такой view, оба следующих SQL-запроса
выполняют одни и те же действия с базовой
таблицей, и мы получим один и тот же результат:
/* SELECT referencing the EmployeeName view. */
SELECT LastName AS EmployeeLastName,
OrderID, OrderDate
FROM Northwind.dbo.Orders AS Ord
JOIN Northwind.dbo.EmployeeName as EmpN
ON (Ord.EmployeeID = EmpN.EmployeeID)
WHERE OrderDate > '31 May, 1996'
/* SELECT referencing the Employees table directly. */
SELECT LastName AS EmployeeLastName,
OrderID, OrderDate
FROM Northwind.dbo.Orders AS Ord
JOIN Northwind.dbo.Employees as Emp
ON (Ord.EmployeeID = Emp.EmployeeID)
WHERE OrderDate > '31 May, 1996'
В SQL Server Query Analyzer можно построить план для обоих
запросов и увидеть, что реляционная подсистема
создает одинаковые планы выполнения для обоих
SQL-запросов (см. ).
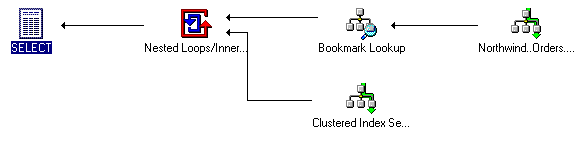
Рис. 8
Рабочие таблицы
Для выполнения логических операций, указанных
в SQL-запросе, реляционная подсистема может
нуждаться в построении рабочей таблицы. Обычно
рабочие таблицы генерируются для определенных
запросов - GROUP BY, ORDER BY или UNION. Например, если
утверждение ORDER BY содержит ссылку на колонки, для
которых нет ни одного индекса, реляционной
подсистеме может понадобиться создать рабочую
таблицу для сортировки result set в требуемой
последовательности.
Рабочие таблицы создаются в tempdb, и при
завершении использования resultset'а автоматически
удаляются.
Физическая архитектура
Физическая архитектура БД
MS SQL Server 7.0 предлагает значительные улучшения в
способах физического хранения данных. Эти
изменения понятны для большинства пользователей
SQL Server, но влияют на установку и
администрирование баз данных SQL Server.
Организация данных в SQL Server 7.0 отличается от
организации данных в предыдущих версиях
продуктаСтраницы и экстенты (extents) Основной
единицей хранения данных в MS SQL Server является
страница. В SQL Server 7.0 размер страницы составляет 8
Кб - то есть в 1 Мб размещается 128 страниц.
Начинается каждая страница с 96-байтного
заголовка, используемого для хранения системной
информации (тип страницы, размер свободного
места на странице, ID объекта, являющегося
собственником страницы, указатели на предыдущую
и последующую страницу этой группы страниц).
В файле БД SQL Server 7.0 существует 6 типов страниц:
| Тип страницы |
Содержимое |
| Данные (Data) |
Строки данных со всеми данными,
кроме text, ntext и image |
| Индекс (Index) |
Вхождения индексов |
| Текст/бинарные данные (Text/Image) |
Данные text, ntext и image |
| Глобальная карта распределения
(Global Allocation Map) |
Информация о занятых экстентах |
| Свободная область страниц |
Информация о свободной области
на страницах |
| Карта распределения индексов |
Информация об интервалах пространства,
занимаемых таблицей или индексом |
Файлы регистрации содержат не страницы, а
последовательность регистрационных записей.
Страницы данных содержат все данные, за
исключением данных text, ntext и image, которые
хранятся в отдельных страницах. Строки данных на
странице размещены последовательно и начинаются
сразу после заголовка. В конце страницы
находится таблица смещения строк. Таблица
смещения строк содержит по одной записи для
каждой строки, и каждая запись указывает,
насколько далеко первый байт строки расположен
от начала страницы. Записи таблицы смещения
строк расположены в порядке, противоположном
расположению строк на странице.
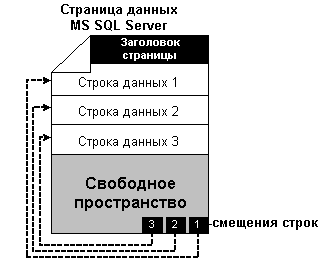
рис.9
В SQL Server'е строки не могут перекрывать несколько
страниц. Максимальный размер строки равен 8060
байтам. Сюда не входят данные, хранящиеся в
колонках типа text, ntext и image.
Экстенты – это базовые единицы, в которых
выделяется место для таблиц и индексов. Экстент -
это 8 последовательно расположенных страниц, или
64 Кб (в 1 Мб помещается 16 экстентов).
Для увеличения эффективности использования
своего адресного пространства, SQL Server не выделяет
целый экстент для таблиц с небольшим объемом
данных. В SQL Server 7.0 может быть два типа экстентов:
- Однородный (Uniform) экстент – экстент, принадлежащий
одному объекту. Все восемь страниц этого экстента могут использоваться только
одним объектом.
- Смешанный экстент – распределяемый между
различными объектами, число которых может
достигать 8.
Новая таблица или индекс занимают страницу из
смешанного экстента. Когда объем таблицы или
индекса увеличивается так, что для размещения
требуется уже 8 страниц, им отводится целый
экстент.
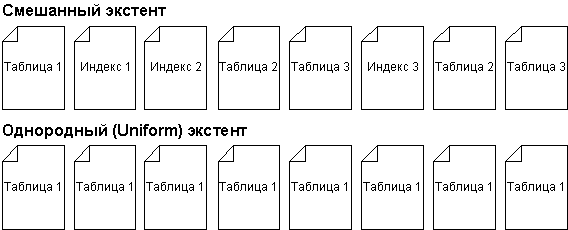
рис.9
Физические файлы и группы файлов БД
MS SQL Server 7.0 отображает БД на несколько файлов
операционной системы. Данные и log-информация
никогда не смешиваются в одном файле, и каждый
файл используется только одной БД. В базе данных
SQL Server 7.0 может быть три типа файлов:
- Основной (Primary) файл данных
Основной файл данных - это стартовая точка БД, в
которой есть указания на все остальные файлы БД.
В каждой БД может быть только один основной файл
данных. Рекомендуемое расширение для первичного
файла данных - .mdf.
- Дополнительный (Secondary) файл данных
Дополнительный файлы данных - это все файлы
данных, кроме основного файла данных. БД может не
иметь дополнительных файлов данных или иметь
множество этих файлов. Рекомендуемое расширение
для дополнительных файлов данных - .ndf.
- Файлы регистрации (log-файлы)
Файлы регистрации содержат всю
регистрационную информацию, которая
используется при восстановлении БД. Каждая БД
должна иметь хотя бы один такой файл, хотя их
может быть и больше. Рекомендуемое расширение -
.ldf.
SQL Server 7.0 не ограничивает использование файлов с
другими расширениями, но .mdf, .ndf и .ldf
рекомендуется использовать для упрощения
идентификации предназначения этих файлов.
Файлы SQL Server 7.0 имеют два имени (с.м. Рис. 9):
- логическое_имя_файла
- это имя файла,
используемое для ссылок в Transact-SQL-запросах.
- OC_имя_файла
- это физическое имя файла, которое
должно отвечать требованиям MS Windows NT или Windows 95/98.

Рис. 10
в SQL Server файлы данных и log-файлы могут
размещаться на файловых системах FAT или NTFS, но не
могут размещаться на сжатых файлах или дисках.
Страницы в файле SQL Server 7.0 последовательно
пронумерованы, начиная с 0. Каждый файл имеет свой
ID. Для уникальной идентификации страницы в БД
нужны номер страницы и ID файла. Следующий пример
демонстрирует нумерацию страниц в БД с основным
файлом данных размером 4 Мб и дополнительным –
размером 1 Мб.
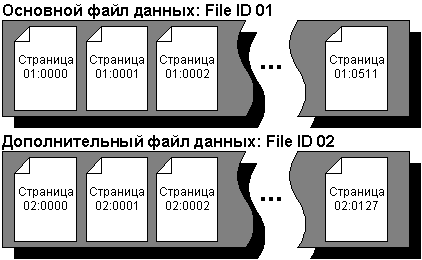
рис.11
Первая страница каждого файла является его
заголовком и содержит информацию о его
атрибутах. Девятая страница в основном файле
данных - это загрузочная страница БД, содержащая
информацию об атрибутах этой БД.
Файлы SQL Server могут автоматически увеличиваться.
При определении файла можно указать шаг
приращения. Каждый раз при заполнении файла, он
увеличивает свой размер на шаг приращения. шаг
приращения может быть задан как абсолютно, так и
в процентах. Если в группе файлов имеется
множество файлов, их размер не будет расти до тех
пор, пока все файлы этой группы не заполнятся.
После этого увеличение размеров файлов будет
происходить по кругу (round-robin algorithm).
Кроме того, можно указать максимальный размер
для каждого файла. Если максимальный размер не
указан, файл может разрастаться до тех пор, пока
не займет все свободное пространство на диске.
Эта возможность упрощает администрирование и
упрощает работу с SQL Server'ом.
Файловые группы БД
Файлы БД могут объединяться в группы в целях
упрощения поиска и администрирования. Некоторые
системы увеличивают быстродействие, управляя
размещением данных и индексов на определенных
дисках. В этом могут помочь файловые группы.
Системный администратор создает файловую группу
для каждого диска, затем присваивает
определенные таблицы, индексы или данные типа text,
ntext или image определенным группам файлов.
Каждый файл может относится только к одной
группе. Таблицы, индексы или данные типа text, ntext или
image могут быть ассоциированы с определенной
файловой группой, в этом случае их страницы будут
размещены в этой файловой группе.
Log-файлы не могут относиться к какой-либо группе
файлов. Регистрационное пространство и
пространство данных управляются отдельно друг
от друга. Существует три типа файловых групп:
Первичная файловая группа содержит первичные
файлы данных и все файлы, не помещенные в другие
группы. Все страницы системных таблиц размещены
в первичной группе файлов.
Пользовательская файловая группа – это любая
файловая группа, образованная с помощью
ключевого слова FILEGROUP в выражении CREATE DATABASE или ALTER
DATABASE.
Default-группа содержит страницы всех таблиц и
индексов, которые при создании не были отнесены
ни к одной группе файлов. Для каждой БД может быть
только одна файловая группа default- . Члены роли db-owner
могут помечать как default одну из файловых групп.
Если default-группа не определена, то default-группой
считается первичная файловая группа.
SQL Server 7.0 эффективно работает и без файловых
групп, поэтому большинству системам
необязательно иметь пользовательские файловые
группы. В этом случае все файлы включены в
первичную файловую группу и SQL Server 7.0 может
эффективно управлять данными БД. Использование
файловых групп – это не единственный метод
распределения I/O между несколькими физическими
устройствами.
Члены роли db-owner могут вместо резервного
копирования и восстановления всей БД
проделывать то же самое с отдельными файлами или
файловыми группами.
Все администрирование может осуществляться
как через T-SQL, так и через Enterprise Manager.
БД SQL Server 7.0 могут быть отключены от сервера и
подключены либо к другому серверу, либо к тому же
самому серверу. Это очень удобно если есть
необходимость в частом переносе БД на другие
компьютеры, ведь отпадает необходимость в
архивации и восстановлении данных.
I/O-архитектура
Основным предназначением баз данных является
хранение данных и их извлечение, поэтому
интенсивная работа с диском является
неотъемлемым атрибутом сервера БД. I/O-операции с
диском потребляют множество ресурсов и их
выполнение занимает относительно много времени.
В ПО реляционных БД большой объем логики связан с
максимальной эффективностью использования
I/O-операций.
MS SQL Server выделяет большой объем виртуальной
памяти для организации кэш-буфера и использует
этот кэш для уменьшения объема физических
I/O-операций. Из файлов БД, находящихся на диске,
данные считываются в кэш-буфер. Таким образом,
большое число операций по логическому чтению
может выполниться без повторного физического
чтения данных. Данные остаются в кэше некоторое
время - пока к ним выполняется обращение, и пока
базе данных не понадобится эта буферная область
для занесения в нее других данных. Данные
записываются на диск только тогда, когда они
изменяются. При этом данные могут меняться много
раз (в этом случае используется логическая
запись) перед их записью на диск.
Данные в SQL Server 7.0 хранятся в страницах размером
8 Кб. Восемь последовательных страниц данных
объединяются в группу (extent) по 64 Кб. Кэш-буфер тоже
делится на страницы размером 8 Кб.
Вся I/O-активность SQL Server подразделяется на
физические и логические I/O-операции. Логическое
чтение происходит каждый раз при запросе
сервером БД страницы из кэш-буфера. Если
требуемой страницы в кэш-буфере нет, для
занесения ее в память выполняется физическое
чтение. Если же страница находится в кэше,
физического чтения не происходит, вместо этого
используется страница, уже имеющаяся в памяти.
Логическая запись выполняется, когда в странице
данных, находящейся в памяти, меняются данные.
Физическая запись выполняется при записи
страницы на диск. Страница может находиться в
памяти достаточно долго для того, чтобы перед
выполнением ее физической записи на диск, в ней
несколько раз была произведена логическая
запись.
Одной из основных задач оптимизации
быстродействия SQL Server’а при его установке
является задание размера памяти SQL Server. Целью
этого является задание такого размера
кэш-буфера, чтобы он был достаточно большим для
максимизации соотношения между числом операций
по логическому и физическому чтению, но не таким
большим, чтобы чрезмерный свопинг (swapping) памяти
привел к выполнению физических I/O-операций с
файлом виртуальной памяти (pagefile). По умолчанию SQL
Server 7.0 делает это автоматически.
Обслуживая относительно большой кэш-буфер в
виртуальной памяти, SQL Server может существенно
уменьшить объем необходимого ему физического
чтения с диска. После того, как страницы, на
которые часто происходят ссылки, будут занесены
в кэш-буфер, скорее всего, в дальнейшем они там и
останутся, что предотвратит необходимость в
повторном физическом чтении.
SQL Server 7.0 использует две возможности MS Windows NT,
позволяющие увеличить I/O-быстродействие диска:
Перед тем, как scatter-gather I/O появились в Windows NT 4.0
Service Pack 2, все данные, которые записывались или
читались, должны были находиться в непрерывной
области памяти. Если при чтении пересылается 64 Кб
данных и запрос чтения должен определить адрес
области памяти с непрерывным свободным
пространством размером 64 Кб, то в случае с
scatter-gather I/O для чтения и записи данных наличие
непрерывной свободной области памяти такого
размера необязательно.
Если SQL Server 7.0 читает порции по 64 Кб, ему нет
необходимости выделять область размером 64 Кб и
копировать в нее страницы отдельные данных. Он
может определить восемь областей и выполнить
одну scatter-gather I/O-операцию, задав адреса восьми
буферных страниц. Windows NT размещает восемь страниц
непосредственно в страницах буфера, что
позволяет SQL Server’у не выполнять копирования в
память.
В случае с асинхронными I/O-операциями,
приложение запрашивает у Windows NT чтение или
запись. Windows NT немедленно возвращает управление
приложению. После этого приложение может
выполнять дополнительную работу, а в дальнейшем -
проверить, завершились ли инициированные им
чтение или запись. И наоборот, в случае с
синхронными I/O-операциями система не возвращает
управления приложению до тех пор, пока не
завершится чтение или запись. Использование
асинхронной работы I/O-операций позволяет SQL
Server‘у увеличить объем работы, выполняемый
каждым потоком при обработке пакета запросов
(batch).
SQL Server одновременно поддерживает множество
асинхронных I/O-операций для каждого файла.
Максимальное число I/O-операций для любого файла
задается в опции конфигурации max async io. Если
значение max async io остается 32 (по умолчанию), то
максимальное число асинхронных I/O-операций в
любой момент времени для любого файла будет не
более 32. Значения 32 достаточно практически для
любой среды.
Считывание страниц
Генерируемые системой запросы на чтение
страниц контролируются реляционным механизмом
(relational engine) и в дальнейшем оптимизируются
системой хранения (storage engine). Метод доступа,
используемый для чтения страниц из таблицы,
определяет общий шаблон исполняемого
считывания. Реляционная подсистема определяет
наиболее оптимальный метод доступа -
сканирование таблицы, сканирование по индексу
или чтение по ключу. Затем этот запрос передается
системе хранения, которая оптимизирует операции
по чтению, необходимые для реализации
конкретного метода доступа. Операции чтения
запрашиваются потоком, выполняющим пакет (batch).
Вследствие использования введенных в MS SQL Server 7.0
новых структур данных, повысилась
производительной операции сканирования таблицы.
В предыдущих версиях SQL Server страницы данных
объединялись в двунаправленную цепочку, которая
часто имела достаточно случайное распределение
в файле БД. Для того, чтобы получить указатель
перехода на следующую страницу, SQL Server должен был
считать предыдущую еестраницу, что приводило к
возникновению последовательностей единичных, а
иногда и выполнявшихся в случайном порядке,
операций чтения. Были сильно ограничены
возможности упреждающего чтения (read-ahead). Теперь в
БД SQL Server 7.0, IAM-страницы содержат в себе списки
extent’ов, используемых для таблиц или индексов.
Система хранения может прочитать IAM-страницы для
создания последовательного списка дисковых
адресов, которые должны быть считаны. Это
позволяет SQL Server’у оптимизировать ввод/вывод,
преобразовав его в большие последовательные
операции чтения, упорядоченные в соответствии с
размещением данных на диске. SQL Server 7.0 формирует
множество последовательных действий по
упреждающему чтению для каждого сканируемого
файла. Это позволяет извлекать преимущества из
распределения файлов БД по дисковому массиву.
Кроме того, SQL Server 7.0 читает страницы индексов в
последовательности их размещения на диске, что
увеличивает быстродействие сканирования по
индексу. Быстродействие работы с индексами
увеличивается благодаря использованию pre-fetch hints,
это позволяет применять упреждающее чтение для
работы с некластерными индексами.
Рисунок (Рис. 10) упрощенно демонстрирует набор
концевых страниц, содержащих набор ключей, и
промежуточный индексный узел, указывающий на
страницы концевого уровня.

Рис. 12
Для планирования последовательности операций
упреждающего чтения страниц, содержащих ключи, в
SQL Server 7.0 используется информация из индексных
страниц промежуточного уровня, расположенных
над концевым уровнем. Если запрос сделан для всех
ключей от “ABC” до “DEF”, SQL Server читает страницу
индексов, расположенную над концевыми
страницами, но не читает страницы: 504, затем 505 и
т.д. до 556 (последней страницы), содержащей ключ
заданного диапазона. Вместо этого система
хранения сканирует промежуточную индексную
страницу и создает список концевых страниц,
которые должны быть прочитаны. Затем система
хранения планирует все операции по вводу/выводу
в последовательности, соответствующей порядку
размещения страниц на диске. Кроме того, система
хранения определяет, что страницы 504/505 и 527/528
последовательны, и применяет scatter-gather I/O для
чтения соседних страниц за один раз. Если при
выполнении последовательных операций
необходимо прочитать много страниц, SQL Server
распределяет операции чтения по блокам. Число
запланированных операций по чтению чуть больше,
чем значение max async io в опции конфигурации.
После завершения части операций по чтению, SQL Server
планирует такое же число новых операций по
чтению и так до тех пор, пока все необходимые
операции по чтению не будут распланированы.
Страницы буфера: запись и удаление
В MS SQL Server 7.0 одна и та же система отвечает за:
- Запись измененных буферных страниц на диск.
- Пометку страниц как свободных, если к ним
определенное время не обращаются.
SQL Server 7.0 имеет однонаправленный список,
содержащий адреса свободных буферных страниц.
Любой поток, которому необходима страница
кэш-буфера, может использовать первую страницу
из этого списка.
Кэш-буфер - это структура, находящаяся в памяти.
Каждая страница буфера имеет заголовок, который
содержит счетчик ссылок и индикатор того,
является ли эта страница “грязной” (dirty). это
значит, что содержимое страницы было изменено, но
еще не было записано на диск. Каждый раз, когда
SQL-запрос ссылается на страницу буфера, значение
счетчика увеличивается на один. Периодически
кэш-буфер сканируется от начала до конца. Такое
сканирование происходит очень быстро, поскольку
весь кэш-буфер находится в оперативной памяти и
ввода-вывода не требуется. Во время сканирования
значение счетчика ссылок (находящегося в
заголовке каждой страницы буфера) делится на 4, а
остаток от деления отбрасывается. Когда значение
счетчика достигает 0, проверяется индикатор
dirty-страницы. Если страница “грязная”,
производится планирование ее записи на диск. В SQL
Server используется упреждающая запись log-файла,
поэтому при записи log-страницы с информацией об
этих изменениях на диск, запись модифицированной
страницы данных блокируется. После записи
измененной страницы на диск, или если запись не
требовалась, страница буфера освобождается.
Удаляется информация о связи между страницей
буфера и страницей данных, находящейся в ней, и
этот буфер помещается в список свободных
буферных страниц.
Благодаря этому часто используемые страницы
остаются в памяти, в то время как страницы,
используемые от случая к случаю, из памяти
удаляются. Размер списка свободных буферных
страниц SQL Server определяет самостоятельно с
учетом размера кэш-буфера, он не может задаваться
при конфигурации сервера.
Когда SQL Server работает на Windows NT, работа по
сканированию буфера, записи dirty-страниц и ведению
списка свободных буферов, в основном,
выполняется отдельными рабочими потоками.
Рабочие потоки выполняют сканирование в
интервале времени между планированием
асинхронного чтения и его завершением. Поток
получает адрес следующего раздела пула буфера,
который необходимо просканировать из
центральной структуры данных, затем сканирует
этот раздел асинхронно с выполнением чтения.
Если должна выполняться запись, то оно
планируется и осуществляется асинхронно, не
влияя на готовность потока завершить
необходимое ему чтение.
Существует отдельный lazywriter-поток (поток
ленивой записи), который тоже выполняет
сканирование кэш-буфера. Процесс lazywriter
(“ленивая” запись) периодически находится в
пассивном состоянии (спит). При каждом
пробуждении он проверяет размер списка
свободных буферов. Если этот список меньше
определенного размера (что зависит от размера
кэша), процесс сканирует кэш-буфер для выявления
неиспользуемых страниц и записывает на диск
dirty-страницы, счетчик ссылок которых имеет
значение 0. В Windows NT подавляющая часть работы по
ведению списка свободных буферов и записи
dirty-страниц выполняется отдельными потоками, в
связи с чем на долю потока lazywriter выпадает
незначительный объем работы. MS Windows 95/98 не
поддерживает асинхронную запись, поэтому вся
работа по ведению списка свободных буферов и
записи dirty-страниц достается потоку lazywriter.
checkpoint-процесс тоже периодически сканирует
кэш-буфер с целью обнаружения dirty-страниц, и
записывает на диск любую страницу буфера,
которая по двум контрольным точкам помечена как
dirty-страница. Отличием является то, что
checkpoint-процесс не помещает страницу буфера в
список свободных буферных страниц. Работа checkpoint-
процесса предназначена для минимизации числа
dirty-страниц в памяти, что уменьшает потери при
восстановлении в случае аварии сервера, а не для
обслуживания списка свободных буферов. Обычно
этот процесс находит всего несколько dirty-страниц,
поскольку большинство dirty-страниц записываются
рабочими потоками или потоком lazywriter в период
между двумя checkpoint’ами.
Планирование операций записи строк из log файлов
обычно осуществляется асинхронно потоком logwriter.
Исключением являются случаи, когда:
- Commit заставляет скинуть на диск все относящиеся к
транзакции записи log файла.
- Checkpoint заставляет скинуть на диск все записи log
файла (всех транзакций).
Архитектура памяти
MS SQL Server 7.0 динамически занимает и высвобождает
память по мере необходимости. Теперь
администратор может не определять, сколько
памяти предназначается SQL Server’у, хотя такая
возможность по-прежнему присутствует.
Современные ОС - такие, как Windows NT и Windows 95/98 -
поддерживают виртуальную память. Виртуальная
память - это метод расширения доступной
компьютеру физической памяти. В системах с
виртуальной памятью, операционная система
создает файл подкачки (pagefile или swapfile) и делит
память на части, называемые страницами. Недавно
запрошенные страница хранится в физической
памяти (RAM). Если в течение определенного времени
обращений к этой странице не было, она
переносится из оперативной памяти в файл
подкачки. Если в дальнейшем приложение будет
ссылаться на эту часть памяти, операционная
система снова считывает ее в RAM. В общей сложности
приложению доступна память, которая по размеру
представляет собой сумму оперативной памяти
компьютера и файла подкачки. Если RAM компьютера и
файл подкачки имеют размер по 256 Мб, то приложению
доступна память объемом до 512 Мб (за вычетом
объема памяти, необходимого для работы самой ОС).
Одной из основных задач при проектировании БД
является минимизация работы с диском, поскольку
эти операции являются наиболее ресурсоемкими.
Для хранения страниц, прочитанных из БД, SQL Server
создает в памяти кэш-буфер. В SQL Server большая часть
кода посвящена именно минимизации объема
физического чтения/записи между кэш-буфером и
диском. Чем больше кэш-буфер, тем меньше I/O
операций с БД нужно сделать SQL Server’у. Однако, если
необходимый размер кэш-буфера превышает объем
доступной физической памяти, операционная
система начинает работать с файлом подкачки. В
результате физическое чтение/запись файла БД
приводит к физическому чтению/записи файла
подкачки.
Большой объем физического ввода/вывода - это
неотъемлемая черта СУБД. SQL Server пытается найти
баланс, преследуя две цели:
- Минимизация или устранение I/O-операций с файлом
подкачки для концентрации I/O-ресурсов на чтении и записи файлов БД.
- Минимизация физических I/O-операций с файлами БД
с помощью увеличения кэш-буфера.
Так, как Windows NT и Windows 95/98 отличаются в
использовании виртуальной памяти приложением, SQL
Server управляет памятью в каждой из этих ОС
используя различные алгоритмы.
Пул памяти SQL Server'а
В пуле памяти хранятся почти все структуры
данных, использующие память SQL Server. Основные типы
объектов, размещающиеся в пуле памяти - это:
1. Структуры данных системного уровня.
2. Кэш-буфер - пул буферных страниц, в которые
считываются страницы данных.
3. Процедурный кэш - пул страниц, содержащий
планы выполнения для всех выполняемых в данный
момент Transact-SQL-запросов.
4. Log кэш.
Вся регистрационная информация имеет кэш
буферных страниц, используемый для чтения и
записи log-страниц. Для уменьшения синхронизации
между буферами регистрации и данных,
регистрационная информация кэшируется и
управляется отдельно от кэш-буфера.
5. Контекст подключения пользователя (connection
context).
Информация о каждом подключении содержится в
наборе структур, где записывается текущее
состояние. Эти структуры содержат такие
сведения, как значения параметров запросов и
хранимых процедур, информация о
позиционировании курсора и таблицах, которые
используются в данный момент.
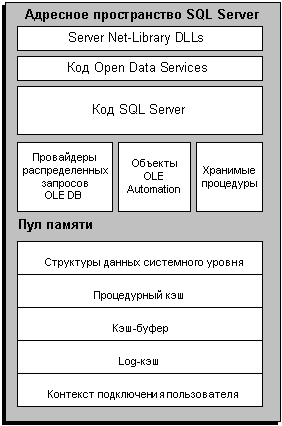
Рис. 13
Размер пула памяти меняется очень динамично,
особенно на компьютерах, на которых работают
другие приложения. По умолчанию SQL Server пытается
сохранить размер виртуальной памяти компьютера
на 5 Мб меньше, чем размер физической памяти.
Единственный способ, которым SQL Server может это
сделать - это изменение размера адресного
пространства.
Виртуальная память в Windows NT
Тестирование показало, что свопинг памяти в
Windows NT минимален, пока распределение памяти
соответствует доступной физической памяти минус
4 Мб. При работе под Windows NT по умолчанию SQL Server
пытается сохранять свободной физическую память
объемом 5 Мб плюс/минус 200 Кб. Такой объем
свободной памяти предохраняет Windows NT от
интенсивного обмена с виртуальной памятью,
одновременно позволяя SQL Server’у иметь
максимально возможный кэш-буфер, не приводящий к
дополнительному свопингу.
Когда другие приложения начинают работать на
компьютере с SQL Server, они также используют память,
что приводит к уменьшению свободной физической
памяти до размеров менее 5 Мб. Тогда SQL Server
высвобождает память. Когда другое приложение
завершает работу и объем доступной памяти
увеличивается, SQL Server занимает высвободившуюся
память.
Если SQL Server работает на компьютере, где часто
запускаются и/или прекращают работать другие
приложения, перераспределение памяти SQL Server’ом
может привести к увеличению времени запуска
других приложений. Кроме того, если SQL Server - не
единственное серверное приложение, работающее
на том же компьютере, системному администратору
необходимо управлять размером памяти,
предназначенной для SQL Server. В этом случае для
контроля объема памяти, отводимой под SQL Server,
можно воспользоваться опциями min server memory и
max server memory.
Виртуальная память в Windows 95/98
При работе под Windows 95/98, используется алгоритм
распределения памяти по требованию (demand-driven
algorithm). По мере увеличения числа Transact-SQL-запросов и
необходимости в кэш-страницах БД, SQL Server
затребует больше виртуальной памяти. Когда
потребности SQL Server’а уменьшаются, например при
уменьшении числа обрабатываемых
Transact-SQL-запросов, SQL Server освобождает память.
Архитектура потоков и заданий
Комплексные приложения зачастую должны
выполнять одновременно множество задач. Потоки -
это возможность операционной системы,
позволяющая логике приложения подразделяться на
несколько одновременно выполняющихся задач.
Когда операционная система исполняет экземпляр
приложения, для управления последним она создает
нечто, называющееся процессом. Процесс имеет
выполняемый поток, который представляет собой
последовательность выполняемых процессором
инструкций. Для простого приложения с одним
набором последовательно выполняемых инструкций,
существует один путь работы, то есть один поток.
Более сложные приложения могут иметь несколько
задач, выполняемых параллельно. Приложение как
же может запускать отдельный процесс для каждой
задачи, но сам запуск процесса - это операция,
требующая интенсивного потребления ресурсов.
Вместо этого приложение может запустить
отдельные потоки, потребляющие относительно
мало ресурсов. Каждый поток может выполняться
независимо от других потоков, связанных с
процессом. Каждый поток хранит уникальные для
него данные, в области памяти, называемой стеком.
Потоки позволяют комплексным приложениям
более эффективно использовать CPU даже на
компьютерах с одним CPU. При наличии одного CPU в
определенный период времени может выполняться
только один поток. Если какой-то из потоков не
использует CPU, выполняя длительную операцию,
например, чтение с диска или запись, то вместо
него CPU может быть задействован другим потоком.
Имея возможность выполнять поток, пока другие
потоки ждут завершения работы первого потока,
приложение максимально использует процессорное
время. Особенно справедливо это для
многопользовательских приложений, интенсивно
работающих с диском, например, для серверов баз
данных.
Компьютеры с несколькими CPU в каждый момент
времени могут выполнять столько же потоков,
сколько у него процессоров.
Волокна (Fibers) Windows NT
Код, управляющий потоками в ОС Windows NT, находится
в ее ядре. Для переключения потоков необходимо
переключение между пользовательским режимом
кода приложения и kernel-режимом менеджера потоков,
что с точки зрения потребления ресурсов является
довольно дорогой операцией. Волокна Windows NT - это
подкомпоненты потоков, которые управляются
кодом, работающим в пользовательском режиме. В
отличие от потоков переключение между волокнами
не нуждается в переключении между
пользовательским режимом и kernel-режимом. Каждый
поток может иметь множество волокон.
Назначение потоков процессорам
По умолчанию MS SQL Server просто запускает поток, а MS
Windows NT присваивает каждый поток определенному CPU.
Windows NT равномерно распределяет потоки между
всеми CPU компьютера. Иногда Windows NT может перенести
поток с интенсивно используемого CPU на менее
используемый. Для исключения одного или
нескольких CPU из процесса работы SQL Server
администратор может воспользоваться
конфигурационной опцией affinity mask. Значение affinity
mask определяет, какие из CPU могут использоваться
для работы потоков SQL Server, например, значение 13
представлено в двоичном коде как 1101. Для
компьютера с четырьмя CPU это значит, что CPU 0, 2 и 3
могут работать с потоками SQL Server’а, а CPU 1 - нет.
Если параметр affinity mask определен, то SQL Server
равномерно распределяет потоки между
разрешенными CPU. Другим результатом действия affinity
mask является то, что Windows NT не переносит потоки с
одного CPU на другой. affinity mask используется
редко. Большинство систем имеют оптимальное
быстродействие при распределении потоков между
всеми имеющимися CPU.
Использование опции lightweight pooling
Стоимость переключения потоков не очень
велика. Большинство систем не видят разницы в
быстродействии, когда значение опции lightweight
pooling 0 или 1. Исключение составляют только
системы, отвечающие следующим требованиям:
- Большие многопроцессорные серверы.
- Все CPU работают с нагрузкой, близкой к максимальной.
- Частое переключение контекста.
При задании опции lightweight pooling значения 1
быстродействие таких систем может несколько
увеличиться.
Архитектура регистрации транзакций
Каждая БД SQL Server имеет регистрационную (log-)
информацию о транзакциях и изменениях,
произведенных транзакциями в базе данных. Этот
список транзакций и изменений имеет три
предназначения:
- Восстановление отдельных транзакций.
Если в приложении встречается выражение ROLLBACK
или SQL Server обнаруживает ошибку, например, разрыв
связи с клиентом, для отмены изменений, внесенных
незавершенной транзакцией, используются
log-записи.
- Восстановление незавершенных транзакций при
начале работы SQL Server.
Если сервер с SQL Server был отключен, БД могла
остаться в таком состоянии, когда часть
изменений из кэш-буфера в файлы данных внесены не
были. Кроме того, изменения могли не записаться в
файлы данных из-за незавершенности некоторых
транзакций. При следующем запуске SQL Server, он
начинает свою работу с восстановления каждой БД.
Записываются действия всех транзакций, которые
были зарегистрированы в log-файле, но не были
записаны в БД. Все незавершенные транзакции
откатываются. После этого выполняется проверка
целостности БД.
- Прокрутка вперед в точку возникновения аварии.
SQL Server 7.0 предлагает несколько улучшений в
регистрации транзакций. Характеристики
регистрации транзакций:
- Регистрация транзакций реализуется не в виде таблицы
БД, а как отдельный файл или набор файлов. log-кэш управляется отдельно от
кэш-буфера страниц данных, что ускоряет и делает более надежной работу SQL
Server'а.
- Формат log-записей и страниц не соответствует формату
страниц данных.
- Регистрация транзакций может осуществляться в
нескольких файлах. Эти файлы при необходимости
можно сконфигурировать как саморазрастающиеся.
Таким образом, можно уменьшить возможность
возникновения нехватки места для
регистрационной информации и избежать лишнего
администрирования.
Механизм отсечения неиспользуемых частей
регистрационной информации быстр и минимально
воздействует на скорость обработки транзакций.
Архитектура полнотекстовых запросов
Введенная в MS SQL Server 7.0 поддержка полнотекстовых
запросов предоставляет возможность
расширенного поиска по колонкам, содержащим
символьные строки.
Эта возможность реализуется сервисом MS Search,
который исполняет следующие роли:
Реализует полнотекстовые каталоги и индексы
(для БД). Обрабатывает определения
полнотекстовых каталогов и таблиц, а также
колонок, составляющие индексы в каждом каталоге.
Реализует вызовы для заполнения этих индексов.
Обрабатывает запросы полнотекстового поиска.
Определяет, какие вхождения в индексе
соответствуют критерию выбора текста. Для
каждого вхождения, которое соответствует
критерию выбора, сервису MS SQL Server возвращается
тождество строки (что-то вроде указателя на
строку), плюс порядковый номер этой строки, а SQL
Server использует эту информацию для создания
окончательного результата запроса. Типы
поддерживаемых запросов включают в себя поиск
для:
- слов и фраз;
- слов, сходных с искомым;
- формы словоизменения глаголов и
существительных.
полнотекстовая система (full-text engine) запускается
как сервис Windows NT Server и имеет имя MS Search. Она
устанавливается, когда при инсталляции в
пользовательском режиме (custom installation) выбрана
возможность Full-Text Search. При установке
Desktop-варианта SQL Server’а сервис MS Search не
устанавливается. Полнотекстовые каталоги или
индексы хранятся не в БД SQL Server, а в отдельных
файлах, управляемых сервисом MS Search. При
восстановлении SQL Server файлы полнотекстовых
каталогов не восстанавливаются. Кроме того, их
нельзя резервно копировать и восстанавливать
T-SQL-запросами BACKUP и RESTORE. После выполнения
операций recovery или restore полнотекстовые каталоги
должны быть отдельно синхронизированы. Файлы
полнотекстовых каталогов доступны только
сервису MS Search или системному администратору Windows
NT.
Связь между SQL Server и сервисом MS Search выполняется
через полнотекстовый провайдер (full-text provider).
Полнотекстовые каталоги и индексы и поиск по
всему тексту, предоставляемые сервисом MS Search,
применимы только для таблиц в БД SQL Server. Windows NT
Indexing Service поддерживает такую же функциональность
для файлов операционной системы. Сервис
индексации включает в себя “OLE DB Provider for Indexing
Service”. Приложения SQL Server могут получать доступ к
OLE DB Provider for Indexing Service через распределенные
запросы. Запросы T-SQL могут комбинировать
полнотекстовый поиск по таблицам SQL Server’а с
полнотекстовым поиском в обыкновенных файлах,
используя распределенные запросы через
обращение к OLE Provider for Indexing Service.
Поддержка полнотекстовой индексации
На Рис. 12 представлены компоненты,
осуществляющие поддержку полнотекстовой
индексации. Эти компоненты ответственны за
определение, создание и заполнение
полнотекстовых индексов.
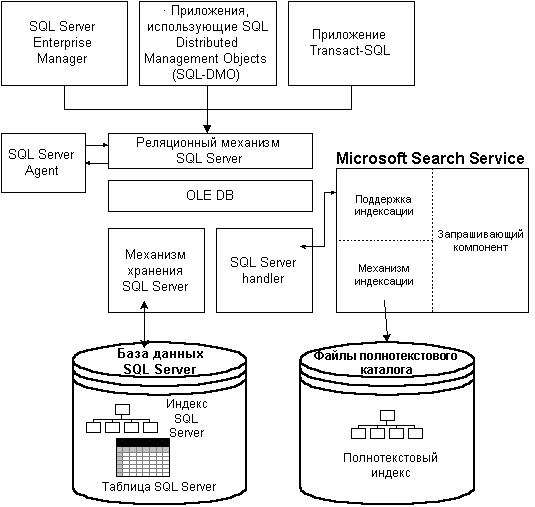
Рис. 14
Для осуществления полнотекстовой индексации
баз данных и таблиц, определения и заполнения
индексов, используются:
- SQL Server Enterprise Manager.
Один из узлов дерева БД в GUI, SQL Server Enterprise Manager
предназначен для управления полнотекстовыми
каталогами БД.
- Приложения, использующие SQL Distributed Management Objects
(SQL-DMO).
В SQL-DMO входят объекты для управления
полнотекстовыми каталогами и индексами.
- Приложения, использующие T-SQL и стандартный API
баз данных.
T-SQL имеет стандартный набор системных хранимых
процедур для управления полнотекстовыми
каталогами и индексами.
Определение и заполнение (populating)
полнотекстовых индексов происходит следующим
образом:
- База данных MS SQL Server делается доступной для
полнотекстовой индексации.
- Указываются полнотекстовые каталоги для БД.
- отдельные таблицы делается доступными для
полнотекстовой индексации и связи с каталогами.
- В каждой таблице к полнотекстовому индексу таблицы
добавляются отдельные колонки. Вся информация о метаданных, используемых в
действиях 1 - 4 хранится в системных таблицах баз данных SQL Server.
- Полнотекстовые индексы для каждой таблицы
активизируются последовательно по схеме таблица-за-таблицей. При активизации
полнотекстового индекса таблицы SQL Server посылает сервису индексации,
входящему в сервис MS Search, начальное значение (start seed value), которое
идентифицирует таблицу, используемую в полнотекстовом индексе.
- Заполнение (population) запрашивается по схеме
каталог-за-каталогом. Запрос на заполнение
каждого каталога посылается сервису индексации.
- Сервис индексации передает соответствующее начальное
значение (start seed value) SQL Server Handler’у (Обработчику SQL Server).
- SQL Server Handler - это драйвер, содержащий логику
извлечения текстовых данных из колонок SQL Server, используемых в
полнотекстовом индексе. Handler извлекает данные из SQL Server и возвращает их
сервису индексации.
- После этого сервис индексации передает идентификатор
индекса и индексируемые строки индексной системе (index engine). Индексная
система устраняет незначащие слова, например, a, and или the. Кроме того, она
определяет границы слова и создает полнотекстовый индекс, охватывающий слова,
переданные из сервиса индексации. Полнотекстовый индекс хранится в файле
полнотекстового каталога.
- По окончании заполнения сервис индексации
подсчитывает новое начальное значение (start seed
value), записывающее ту точку, с которой должно
начинаться следующее заполнение.
Заполнение из действия 6 может принимать
различные формы:
Вхождения индексов строятся для всех строк
всех таблиц, которые охватываются
полнотекстовым каталогом. Обычно полное
заполнение происходит при первом заполнении
каталога.
- Инкрементальное заполнение.
Настраивает индексы только для добавленных,
измененных или удаленных (после последнего
заполнения) строк. Для этого индексированная
таблица должна содержать колонку с типом данных timestamp.
В противном случае может выполняться только
полное заполнение (даже после запроса
инкрементального заполнения).
Если для таблицы, которая не была перед этим
ассоциирована с каталогом, определен новый
полнотекстовый индекс, запрос на
инкрементальное заполнение приведет к созданию
всех вхождений для таблицы.
Запрос на инкрементальное заполнение
реализуется как полное заполнение и в случае
изменения метаданных для данной таблицы после
последнего заполнения, например, изменения
определения какой-либо колонки, индекса или
полнотекстового индекса.
Обычно полнотекстовый каталог бывает
определен, и для него уже выполнено полное
заполнение. После этого для передачи новых
данных, добавленных к индексированным колонкам
SQL Server, выполняется инкрементальное заполнение.
Эти периодические операции по инкрементальному
заполнению обычно определяются как задания (jobs) и
автоматически обрабатываются сервисом SQL ServerAgent.
Поддержка полнотекстовых запросов
Когда MS SQL Server получает T-SQL-запрос с
полнотекстовой конструкцией, он извлекает из
сервиса MS Search (с помощью полнотекстового
провайдера) необходимую информацию.
Полнотекстовые конструкции используют
предикаты CONTAINS или FREETEXT, либо функции CONTAINSTABLE или
FREETEXTTABLE. Полнотекстовые конструкции могут
ссылаться на множество колонок полнотекстового
индекса, если им неизвестно, в какой именно
колонке могут содержаться условия поиска.
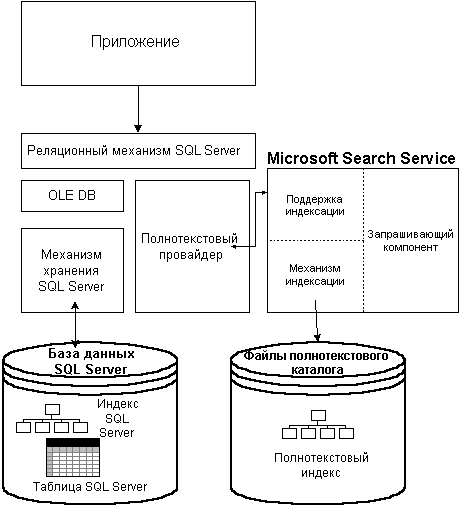
рис.15
Компоненты участвуют в этом процессе следующим
образом:
1. SQL Server получает от приложения T-SQL-запрос с
полнотекстовой конструкцией.
2. Реляционная система SQL Server'а проверяет
достоверность полнотекстовой конструкции,
запрашивая из системных таблиц,
проиндексированы ли эти колонки. Реляционная
система разбивает каждый SQL-запрос на
последовательность rowset-операций и с помощью OLE DB
передает эти операции компонентам нижнего
уровня, обычно - системе хранения. Реляционная
система преобразует любую полнотекстовую
конструкцию в запрос rowset’а из полнотекстового
провайдера, а не из системы хранения. Запрошенный
rowset – это набор ключей, удовлетворяющих условиям
поиска, а также индикатор, показывающий,
насколько данные каждого ключа совпали с
критерием поиска. Команда, посланная с запросом
rowset’а полнотекстовому провайдеру, включает в
себя условия полнотекстового поиска.
3. Полнотекстовый провайдер проверяет
достоверность запроса и преобразует условия
поиска в форму, используемую компонентом
поддержки запроса (сервиса MS Search).
4. Запрос посылается сервису поиска, который
возвращает результат реляционной системе в виде
rowset’а.
5. Реляционная система комбинирует все принятые
от системы хранения и полнотекстового
провайдера rowset’ы и создает конечный resultset,
возвращаемый клиенту.
Обработка запросов
Обработка простого (единичного) SQL-запроса
Обработка единичного SQL-запроса - это
простейший случай выполнения SQL-запросов.
Проиллюстрировать основной процесс могут шаги,
используемые при обработке единичного выражения
SELECT, которое ссылается только на таблицы
локальной БД (без view или удаленных таблиц).
Оптимизация выражений SELECT
Выражение SELECT не предлагает унифицированных
шагов, которые должен выполнить сервер БД для
извлечения затребованных данных. Это значит, что
для определения наиболее эффективного способа
получения данных сервер БД должен
проанализировать выражение. Такой анализ
называется оптимизацией выражения SELECT, а
компонент, который выполняет это, называется
оптимизатором запросов.
Выражение SELECT определяет:
- Формат resultset'а. Обычно он определяется в списке
колонок, несмотря на то, что другие утверждения - такие, как ORDER BY и GROUP
BY - тоже влияют на конечную форму resultset'а.
- Таблицы, содержащие исходные данные. Они определяются
в утверждении FROM.
- То, как таблицы логически соотносятся с задачей
выражения SELECT. Это определяется в характеристиках связей (join
specifications).
- Условия, которым удовлетворяют строки исходных
таблиц в выражении SELECT определяются в
утверждениях WHERE и HAVING.
План выполнения запроса представляет собой
определение:
- Последовательности, в которой выполняется
доступ к исходным таблицам.
Обычно существует много различных
последовательностей, которым может следовать
сервер БД для построения resultset'а. Например, если
выражение SELECT ссылается на три таблицы, сервер БД
мог бы сначала обратиться к таблице TableA,
использовать данные из TableA для получения
соответствующих строк из TableB, а затем
использовать данные из TableB для извлечения
данных из TableC. Либо сервер БД может
обратиться к этим таблицам в обратном порядке, в
порядке (TableB, TableA и TableC) и в порядке (TableC,
TableA, TableB).
- Методов, используемых для извлечения данных из
таблиц.
методов, которые используются для получения
доступа к данным из нескольких таблиц, тоже
существует несколько. Если нужно только
несколько строк с определенными ключевыми
значениями, сервер БД может использовать индекс.
Если же нужны все строки таблицы, сервер БД может
проигнорировать индекс и выполнить сканирование
таблицы. Если же нужны все строки таблицы, но
существует индекс, ключевые колонки которого
находятся в соответствии с утверждением ORDER BY,
выполнение сканирования индекса вместо
сканирования таблицы может сделать ненужной
сортировку полученого resultset'а. Если таблица
слишком мала, сканирование таблицы может
оказаться более эффективным методом доступа к
таблице.
Процесс выбора одного плана выполнения из
нескольких возможных планов называется
оптимизацией. Оптимизатор запросов – это один из
наиболее важных компонентов системы SQL Server-БД.
Разумеется, сам процесс анализа запроса и выбора
плана требует потребления ресурсов, но это
окупается сторицей, когда оптимизатор
определяет наиболее эффективный план
выполнения. Представим две строительные
компании, одна из которых перед началом
строительства тщательно проектирует здание и
планирует расходы, а другая, не делая этого, сразу
приступает к строительству. Понятно, что
строительство первой завершит именно та
компания, которая перед его началом определилась
с тем, что именно и как она будет это строить.
Оптимизатор MS SQL Server 7.0 - это оптимизатор,
базирующийся на стоимости (cost-based optimizer). Для
обработки конкретного запроса требуются
определенные затраты ресурсов системы. Кроме
того, в расчет принимается время ожидания
пользователя. Оптимизатор выбирает план,
выполнение которого (по его мнению) минимизирует
время ожидания пользователя при приемлемом
потреблении ресурсов.
Обработка выражения SELECT
Основные действия, которые выполняет SQL Server при
обработке единичного выражения SELECT:
- Парсер (синтаксический анализатор) сканирует
выражение SELECT и разделяет его на логические элементы: ключевые слова
(keywords), выражения (expressions), операторы (operators) и идентификаторы
(identifiers).
- Строится дерево запроса, иногда называемое sequence
tree, в котором описываются логические действия, необходимые для
преобразования исходных данных в формат recordset'а.
- После этого оптимизатор анализирует все способы,
какими может быть получен доступ к исходным таблицам, и выбирает
последовательность действий, возвращающих результат быстрее и потребляющих
меньше ресурсов. Окончательная оптимизированная версия дерева запроса
называется планом выполнения.
- Реляционная подсистема начинает осуществлять план
выполнения. При выполнении шагов, которым нужны данные из таблиц, реляционная
подсистема обращается к к подсистеме хранения посредством OLE DB.
- Реляционная подсистема преобразует данные,
возвращенные ей подсистемой хранения, в формат,
определенный запросом, а затем возвращает resultset
клиенту.
Обработка других выражений
Основные действия, описанные для выражения SELECT,
справедливы и для других выражений - UPDATE, DELETE и
INSERT. Выражения UPDATE и DELETE ответственны за удаление
или изменение строк, но процесс поиска этих строк
тот же, что и при поиске строк, необходимых для
создания resultset'а в случае с выражением SELECT.
Выражения INSERT, UPDATE и DELETE могут содержать
встроенные выражения SELECT.
Выполнение хранимых процедур и триггеров
В MS SQL Server 7.0 изменен способ выполнения хранимых
процедур и триггеров. Кроме того, в SQL Server 7.0
изменен способ управления планами выполнения
всех типов запросов, что позволяет большинству
пакетов запросов работать с таким
быстродействием, которое в более ранних версиях
SQL Server’а было возможно только для хранимых
процедур. SQL Server 7.0 сохраняет только исходный код
для хранимых процедур и триггеров. При первом
выполнении хранимой процедуры или триггера этот
исходный текст компилируется в план выполнения.
Если эта хранимая процедура или триггер
выполняются еще раз (до того, как их план
выполнения был удален из памяти), реляционная
подсистема определяет, что этот план имеется в
памяти и использует его повторно. Если же плана
выполнения в памяти уже нет, он создается вновь.
Этот же подход SQL Server использует и для всех
остальных SQL-запросов. Основным преимуществом
хранимых процедур и триггеров является то, что их
SQL-запросы всегда одинаковы, благодаря чему
реляционная подсистема легко находит планы их
выполнения в памяти.
Быстродействие хранимых процедур значительно
улучшилось по сравнению с предыдущими версиями
SQL Server. Предыдущие версии SQL Server не пытались
повторно использовать план выполнения для
пакетов, в которых не было хранимых процедур или
триггеров. Единственным способом повторного
использования плана выполнения было кодирование
SQL-запросов в хранимых процедурах.
План выполнения для хранимых процедур и
триггеров строился отдельно от плана выполнения
пакетов, вызывающих хранимые процедуры или
запускающих триггеры. Это даже приводило к тому,
что один и тот же запрос выполнялся с разной
производительностью в хранимых процедурах и в
простых пакетах. В новой версии это исправлено.
Естественно, увеличение степени повторного
использования планов выполнения запроса привело
к росту производительности.
Кэширование и повторное использование планов
выполнения
SQL Server 7.0 имеет пул памяти, который используется
для хранения планов выполнения и буферов данных.
Процентное соотношение между размером пула для
каждого из предназначений динамически
изменяется в зависимости от текущего состояния
системы. Та часть памяти, которая используется
для хранения планов выполнения, называется
процедурным кэшем.
План выполнения в SQL Server 7.0 имеет два основных
компонента (см. Рис. 16):
- План запросов (Query plan)
Большая часть плана выполнения - это структура
данных только-для-чтения с возможностью
повторного использования, которая может
использоваться любым числом пользователей. Она
называется планом запросов. в плане запроса
контекст пользователя не сохраняется. В памяти
не бывает более двух копий плана запросов, одна
копия - для всех последовательных, а вторая - для
всех параллельных планов.
- Контекст выполнения (Execution context)
Для каждого пользователя, в данный момент
выполняющего запрос, создается структура,
которая содержит специфичную для этого
пользователя информацию, например, значения
параметров. Эта структура данных называется
контекстом выполнения. Структуры данных
контекста выполнения могут повторно
использоваться. Если какой-то пользователь
выполняет запрос и одна из структур не
используется, она повторно инициализируется с
контекстом для нового пользователя.
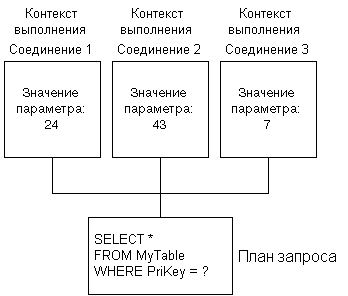
Рис. 16
Когда в SQL Server 7.0 выполняется некоторый
SQL-запрос, реляционный механизм сначала
просматривает процедурный кэш для определения
наличия в нем плана выполнения для такого же
SQL-запроса. SQL Server 7.0 имеет эффективный алгоритм
поиска существующего плана выполнения. SQL Server 7.0
повторно использует любой найденный план
выполнения, спасая от накладных расходов,
связанных с перекомпиляцией SQL-запроса. Если
плана выполнения нет, SQL Server 7.0 генерирует новый
план для данного запроса.
Алгоритму для сопоставления нового SQL-запроса с
существующим в кэш, но неиспользуемым планом
выполнения необходимо, чтобы все объекты, на
которые происходит ссылка, были полностью
определены. Например, первое из этих выражений
несопоставимо с существующим планом, а второе -
сопоставимо:
SELECT * FROM Employees
SELECT * FROM Northwind.dbo.Employees
“Старение” планов выполнения
После генерации план выполнения остается в
процедурном кэше. SQL Server 7.0 удаляет старый
неиспользуемый план только при необходимости в
свободном месте. Каждый план запроса и контекст
выполнения имеет фактор стоимости, который
показывает, насколько “дорого” обойдется
компиляция конкретной структуры. Эти структуры
данных также содержат поле age (возраст). Каждый
раз, когда на объект ссылается какое-нибудь
пользовательское соединение, значение поля age
увеличивается на фактор стоимости компиляции.
Например, если план запроса имеет фактор
стоимости 8 и ссылки на него осуществлялись
дважды, его поле age будет иметь значение 16.
Периодически, при сканировании списка объектов в
процедурном кэше, поток lazywriter уменьшает значение
поля age на 1 для каждого объекта. Значение age в
нашем примере уменьшится до 0 после 16
сканирований процедурного кэша - если никакой
пользователь не будет ссылаться на этот план.
Поток lazywriter удаляет объект при совпадении трех
событий:
- Менеджеру памяти нужно свободное место, но вся память
используется.
- Значение поля age для данного объекта равно 0.
- В данный момент на объект ссылки по подключению
нет.
Поскольку при ссылке на объект значение его
поля age увеличивается, для часто используемых
объектов значения 0 в поле age не будет, и,
следовательно, объект не будет удален. Вместо
этого будет удален объект, который используется
реже, однако это произойдет только в случае
необходимости свободной памяти для других
объектов.
Перекомпиляция планов выполнения
Определенные изменения в базе данных могут
привести к тому, что план выполнения станет
неэффективным либо вообще некорректным. SQL Server
определяет изменения, которые могут
отрицательно повлиять на план выполнения, после
чего помечает план как некорректный. Следующее
выполнение запроса должно пересоздать план.
Перечислим условия, которые необходимы для
признания плана некорректным:
- Любое структурное изменение, которое делается для
таблицы или view, на которые ссылается запрос (ALTER TABLE и ALTER VIEW);
- Новая статистика распределения, которая генерируется
как явно (выражением UPDATE STATISTICS), так и автоматически;
- Удаление индекса, используемого планом выполнения;
- Явный вызов sp_recompile;
- Большое число изменений, произведенных выражениями
INSERT или DELETE в таблицах, на которые ссылается запрос;
- Для таблиц с триггерами, если число строк в
таблицах inserted или deleted значительно
увеличилось.
Параметры и повторное использование планов
выполнения
Использование параметров, включая маркеры
параметров в ADO-, OLE DB- и ODBC-приложениях, может
увеличить повторную используемость планов
выполнения.
Единственной разницей в следующих выражениях
SELECT являются значения WHERE:
SELECT * FROM Northwind.dbo.Products WHERE CategoryID = 1
SELECT * FROM Northwind.dbo.Products WHERE CategoryID = 4
Разница между планами выполнения для этих двух
запросов заключается в значении, указанном в
операции сравнения с колонкой CategoryID. Было бы
неплохо, если бы MS SQL Server 7.0 определял, что
выражения сгенерировали, по существу, одинаковые
планы, и смог бы повторно использовать один и тот
же план.
Отделение констант от SQL-запроса помогает
реляционной подсистеме определять
повторяющиеся планы. Существует два способа
использования параметров:
- В Transact-SQL использование sp_executesql:
DECLARE @MyIntParm INT
SET @MyIntParm = 1
EXEC sp_executesql
N’SELECT * FROM Northwind.dbo.Products WHERE CategoryID = @Parm’, N’@Parm INT’, @MyIntParm
Этот метод применим для Transact-SQL-сценариев,
хранимых процедур или триггеров, которые
динамически генерируют SQL-запросы.
- В ADO, OLE DB и ODBC используются маркеры параметров.
Маркеры параметров - это символы “?”, которые
замещают константу в SQL-запросе и привязываются к
программной переменной. Например, в
ODBC-приложении:
В SQL-запросе для связывания переменной типа integer
с первым маркером параметра следует
использовать SQLBindParameter. Далее следует поместить
значение в переменную, и выполнить запрос,
пометив параметр маркером “?”:
SQLExecDirect(hstmt,
"SELECT * FROM Northwind.dbo.Products WHERE CategoryID = ?",
SQL_NTS);
И OLE DB Provider и ODBC пользуются для передачи
параметров sp_executesql.
Автоматическая параметризация
В MS SQL Server 7.0 использование маркеров параметров
или самих параметров в Transact-SQL-запросах расширяет
возможности реляционной подсистемы по
нахождению соответствий между новыми
SQL-запросами и существующими планами выполнения.
Но если SQL-запрос выполняется без параметров, SQL
Server 7.0 не разводит руками, а самостоятельно
пытается задать параметры для запроса. Это
увеличивает возможность нахождения
соответствий с существующими планами
выполнения.
Рассмотрим выражение:
SELECT * FROM Northwind.dbo.Products WHERE CategoryID = 1
Значение 1 в конце выражения может быть
определено как параметр. Реляционная подсистема
строит план выполнения этого запроса, как если бы
вместо значения 1 был определен параметр.
Благодаря наличию автоматической
параметризации SQL Server 7.0 определяет, что два
следующих выражения генерируют практически один
и тот же план выполнения и для второго выражения
повторно использует тот план, который был создан
для первого выражения:
SELECT * FROM Northwind.dbo.Products WHERE CategoryID = 1
SELECT * FROM Northwind.dbo.Products WHERE CategoryID = 4
При работе со сложными SQL-запросами,
реляционная подсистема может испытать трудности
при определении возможности применения
автоматической параметризации для выражения .
Для увеличения возможностей реляционной
подсистемы в смысле определения соответствия
между сложными SQL-запросами и существующими
неиспользуемыми планами выполнения, следует
явно задавать параметры с помощью sp_executesql или
маркеры параметров.
Прекомпиляция (Preparing) SQL-запросов
Наконец-то MS SQL Server 7.0 стал предоставлять полную
поддержку компиляции SQL-запросов. Если
приложению нужно, чтобы SQL-запрос выполнялся
несколько раз, используя API БД, оно может:
откомпилировать запрос и выполнять
откомпилированный запрос несколько раз, изменяя
параметры, но не перекомпилируя сам запрос.
Компиляция запросов и их выполнение
управляются функциями и методами API. Это не
является частью языка Transact-SQL. Модель
компиляции/выполнения SQL-запросов
поддерживается OLE DB-провайдером для SQL Server и ODBC
драйвером. Через вызов prepare (соответствующего API) SQL
Server’у передается запрос. SQL Server обрабатывает
его, создает план выполнения и возвращает handle
данного плана. При вызове Execute (запрос на
выполнение) провайдер или драйвер посылает
серверу запрос на выполнение плана, связанного с
handle'ом и значение параметров (если таковые
имелись в запросе).
Вопреки распространенному мнению, что перед
использованием запрос всегда нужно
компилировать (навязываемое большинством
учебников и книгами по SQL), можно смело
утверждать, что чрезмерное злоупотребление
моделью компиляция/выполннение может серьезно
уменьшить быстродействие. Если выражение
выполняется только один раз (или изменяется
перед вызовом), для непосредственного выполнения
требуется один сетевой обмен с сервером. А для
компиляции и последующего выполнения необходимо
два вызова по сети. На практике такой подход
может замедлит работу приложения вдвое.
Компиляция выражения наиболее эффективна при
использовании маркера параметров. Например,
представим приложение, у которого изредка
запрашивают информацию о продукции из БД Northwind.
Есть два способа, которыми приложение может это
сделать. Во-первых, приложение может выполнить
отдельный запрос для каждого продукта:
SELECT * FROM Northwind.dbo.Products
WHERE ProductID = 63
Альтернативой этому может быть следующее.
Приложение:
1. Готовит выражение, содержащее маркер
параметра (?):
SELECT * FROM Northwind.dbo.Products
WHERE ProductID = ?
2. Устанавливает в программе связь между
переменной и маркером.
3. Каждый раз при необходимости получения
информации о продукте, присваивает переменной
ключевое значение и выполняет выражение.
Второй метод наиболее эффективен, когда
выражение выполняется более трех или четырех
раз.
Дело в том, что в SQL Server 7.0 относительное
преимущество модели откомпилировать/выполнить
перед непосредственным выполнением уменьшается
в связи с автоматическим повторным
использованием плана выполнения. SQL Server 7.0 имеет
достаточно эффективные алгоритмы для нахождения
соответствия между конкретным SQL-запросом и
имеющимся в памяти планом выполнения, созданным
при предыдущих выполнениях такого же SQL-запроса.
Если приложение выполняет SQL-запрос с маркерами
параметров много раз, для выполнения второго и
всех последующих выражений SQL Server 7.0 просто
воспользуется планом выполнения, оставшимся
после первого выражения (в случае, если этот план
будет в процедурном кэш). Так что выигрыш будет
только в отсутствие парсинга (разбора выражения).
Модель откомпилировать/выполнить по-прежнему
предоставляет такие преимущества как:
- Поиск плана выполнения посредством идентификации
метода обработки чуть эффективнее алгоритмов, используемых для нахождения
соответствия между SQL-запросом и существующими планами выполнения;
- Приложение не теряет управления при создании и
повторном использовании плана выполнения;
- Модель откомпилировать/выполнить совместима с
другими базами данных, включая предыдущие версии
SQL Server.
Компиляция и выполнение в предыдущих версиях
SQL Server
Предыдущие версии SQL Server напрямую не
поддерживали модель откомпилировать/выполнить.
Однако, ODBC-драйвер поддерживал эту модель
посредством использования хранимых процедур:
- Когда приложение запрашивало компиляцию SQL-запроса,
ODBC-драйвер автоматически создавал на базе переданного ему SQL-запроса
временную хранимую процедуру (добавляя к запросу в выражение CREATE
PROCEDURE);
- При запросе выполнения ODBC-драйвер выполнял
сгенерированную им хранимую процедуру и
возвращал результат. SQL Server 4.21а и более ранние
версии не поддерживали временно хранящихся
процедур, поэтому генерировавшиеся драйвером
хранимые процедуры размещались в текущей базе
данных.
Межcерверные запросы, или архитектура
распределенных запросов
MS SQL Server 7.0 поддерживает два метода ссылки на
гетерогенные источники данных OLE DB в
Transact-SQL-запросах через:
- Имена подключенных серверов.
Хранимые системные процедуры sp_addlinkedsrv и sp_addlinkedserverlogin
используются для того, чтобы назначить источнику
данных OLE DB имя сервера. На объекты, находящиеся
на таких подключенных серверах, ссылки в
Transact-SQL-запросах могут делаться с использованием
имен, состоящих из 4-х частей. Например, если имя
DeptSQLSrvr задано для удаленного (другого) сервера MS
SQL Server 7.0, то следующее выражение ссылается на
таблицу этого сервера:
SELECT * from DeptSQLSrvr.Northwind.dbo.Employees
Где: Northwind – БД на удаленном сервере, dbo – имя
пользователя-создателя таблицы, Employees – таблица
на удаленном сервере.
Кроме того, чтобы открыть rowset из OLE DB-источника
данных, имя подключенного сервера может быть
определено в выражении OPENQUERY. На этот rowset можно
ссылаться как на таблицу в Transact-SQL-запросах.
Для редко возникающих ссылок на источник
данных используется функция OPENROWSET с информацией,
необходимой для соединения с подключенным
сервером. На этот rowset можно ссылаться так же, как
на таблицу в Transact-SQL-запросах:
SELECT *
FROM OPENROWSET ('Microsoft.Jet.OLEDB.4.0',
'c:\MSOffice\Access\Samples\Northwind.mdb';'Admin';';
Employees)
Для связи между реляционным механизмом (relational
engine) и механизмом хранения (storage engine) SQL Server 7.0
использует OLE DB. Реляционная подсистема
разбивает каждое Transact-SQL-запрос на
последовательность операций с простыми OLE DB-
rowset’ами, открываемыми системой хранения на базе
таблиц БД. Кроме всего прочего, это означает, что
реляционная подсистема может открывать простые
наборы строк OLE DB из любого источника данных OLE DB.
рис. 17
Для открытия rowset’ов на подключенных серверах,
получения строк и управления транзакциями,
реляционная подсистема пользуется OLE DB API.
Для доступа к любому OLE DB-источнику данных
необходимо наличие на той же машине, что и SQL Server,
соответствующего OLE DB-провайдера . Набор
Transact-SQL-операций, которые могут использоваться
для работы с конкретным источником данных OLE DB,
зависит от возможностей OLE DB-провайдера.
Когда это возможно, SQL Server передает такие
реляционные операции, как join, restriction, projection, sort и
group by источнику данных OLE DB. SQL Server по умолчанию не
производит сканирования базовой таблицы и не
выполняет реляционных операций самостоятельно.
Copyright © 1994-2016 ООО "К-Пресс"
