 |
Технология Клиент-Сервер 2001'3
|
|
|
Кто сегодня самый шустрый?
Владислав Чистяков
Исходный код тестов.
Следующие серии: Вторая серия, Третья серия.
Упрямые факты говорят, что мы с вами (то есть весь
компьютерный мир) находимся на перепутье. Все понимают, что производительность и
качество труда программистов нужно повышать, причем не в ущерб
производительности ПО. Повышать! Но как?
Тут мнения расходятся. Есть много технологий, которые должны
были радикально повысить производительность, но... на практике повышение от них
не так радикально, как хотелось бы. На этой почве происходит бурное развитие
новых языков, RAD-сред и CASE-систем, исполняющих платформ (Java, .Net), а ведь
еще недавно казалось, что все уже изобретено. Причем в бой вступили тяжеловесы и
старожилы этого рынка (Microsoft, Borland, Sun, Oracle, IBM...)! Borland и
Microsoft лидируют на рынке RAD-средств. Sun и Microsoft перетягивают шкуру
неубитого медведя переносимой платформы и языка нового поколения. IBM как всегда
берется за все и вся, желая как лучше, но получается как всегда... корпоративные
решения на мэйнфрэймах. Oracle не знает к кому пристроиться и как всегда все
хочет засунуть в БД (естественно, в свою). А что же мы, программисты? А мы пока
используем старые, местами добрые, технологии, и смотрим, чем закончится битва
гигантов.
Итак, все понимают, что так дальше нельзя, но вот как можно –
никто не знает. Попробуем определить, что плохого в современных технологиях и
что могут предложить нам новые.
Сегодня большая часть софта пишется на трех языках
программирования. Это C++, Delphi и VB 6. Собственно Delphi, и VB 6 языками
являются отчасти. Скорее это симбиоз RAD-сред, компонентных библиотек и
собственно языка. C/C++ используется (в основном) при создании библиотек (в том
числе и компонентных) и коробочного (читай тиражного) ПО, такого как текстовые
процессоры, ОС, и т.п. Delphi и VB 6 делят рынок прикладного ПО, т.е.
используются для создания уникального ПО и малотиражных продуктов. При этом
RAD-возможности и компонентная архитектура позволяют упростить, а значит
ускорить, а значит – удешевить процесс создания ПО.
VB 6
VB берет до тупости простым языком. Отсутствие указателей,
удобные конструкции (типа, select case, позволяющего использовать строки в
case-разделе и for each, радикально упрощающего перебор объектов), защищенность
(не используя внешних функций и глючных компонентов на VB практически невозможно
создать программу, приводящую к таким стандартным для 3GL-языков ошибкам, как
Access Violation (AV)). Но недостатков у этого языка тоже хоть отбавляй.
Невысокая производительность (по крайней мере, такое устойчивое мнение бытует
среди программистов), слабые возможности по использованию системных функций,
нулевая переносимость на другие платформы, недостаточная гибкость, нелюбовь к
проектам большого размера, примитивный отладчик (отладка компонентов и DLL может
производиться только в адресном пространстве самого VB), использование сложного
стандарта ActiveX, который может быть реализован в полной мере только на C++.
Использование VB в паре с VC дает неплохие результаты, но требует высокой
квалификации специалистов и большего, чем при использовании одного VB, времени.
Однако большой рынок коммерческих компонентов для VB (по качеству зачастую
превосходящих компоненты для Delphi) делает из VB прекрасную среду для быстрой
сборки и развития прикладных пакетов.
Delphi
Delphi отличается тем, что кроме сходной с VB среды
предоставляет в руки разработчика сильно модифицированный 3GL-язык. Это дает
возможность обходить большинство ограничений VB, и в тоже время избежать многих
проблем и сложностей, встречающихся при разработке на C++. Однако, как и любое
компромиссное решение, оно приводит к тому, что страдают тонкие детали. Так,
языку необходимо иметь полный набор средств, которым обладает хотя бы C. И
Delphi ими обладает, но до C не дотягивает. C, как ориентированный на создание
системного ПО язык, обладает развитыми средствами работы с указателями, а Delphi
должна соблюдать внешний вид строго типизированного языка. Про C++ вообще речи
не идет. Такие сложные конструкции, как множественное наследование и шаблоны,
отпугивают тех, кому в первую очередь нужна легкость и высокая скорость
разработки. К тому же бытует мнение, что Delphi порождает худший код, чем
популярные C++-компиляторы, такие, как VC, Intel C++ compiler и g++. Это
утверждение иногда опровергается приверженцами Delphi, но общественное мнение
уже устоялось, и изменить его трудно. Последним недостатком Delphi как продукта
является то, что его язык основан не на C, используемом сегодня для создания
библиотек системного уровня, а на Паскале, притом сильно модифицированном и не
стандартизованном. Как не крути, большинство API приходит в виде C/C++-заголовочных
файлов, а основные игроки этого рынка не приняли (и, похоже, уже никогда не
примут) Object Pascal за стандарт. Все это не является недостатком языка, но
сильно мешает применению Delphi в областях, отличных от создания учетного ПО.
Однако наличие более-менее работоспособного набора компонентов для работы с БД,
и особенно большое количество компонентов независимых разработчиков, сделали
Delphi неплохим средством разработки клиентских, а теперь и серверных
компонентов. Однако кое в чем здесь Delphi уступает VB. Язык Delphi
разрабатывался с целью обезопасить и упростить разработку ПО. Но на практике
совместимость с 3GL и корявое сопряжение новых (безопасных) и старых (опасных)
возможностей привело к тому, что количество ошибок при программировании на
Delphi не многим меньше, чем при программировании на C++. Так, программисту
приходится вручную (как и в большинстве 3GL-языков) контролировать время жизни
объектов, неинтуитивность многих операций (например, массивы по умолчанию
предаются не по ссылке, а целиком копируются в стек), громоздкий синтаксис
(необходимость писать излишний код begin/end практически в любом операторе,
раздельная декларация и реализация (как в C++) методов классов) и некоторые
другие особенности приводят к тому, что по простоте и скорости создания кода
Delphi уступает VB. Можно сказать, что Delphi – это гибрид между VB и VC. По
отдельности эти продукты (каждый со своей стороны) проигрывают Delphi, в
совокупности все же превосходят её. Это положение вещей проистекает из того, что
универсальность всегда строится на компромиссе. Delphi проигрывает C++ в
возможностях и удобстве системного программирования, но выигрывает в простоте и
скорости разработки. С другой стороны Delphi выигрывает у VB 6, по параметрам,
по которым она проигрывала VC, но проигрывает тому же VB в простоте
использования. Еще один недостаток (который смело можно назвать шовинистическим)
Delphi заключается в том, что Borland является игроком на Windows-рынке, но (к
сожалению) не является производителем этих ОС (в отличие от Microsoft). И хотя
это может показаться смешным, но этот аргумент очень часто выдвигается
противниками Delphi.
Новые решения
Итак, во второй половине 90-х на рынке появился новый
конкурент – Java. Поначалу казалось, что Java не стоит внимания. Низкая
производительность, вызванная интерпретирующей сущностью. Слабые (если не
сказать больше) позиции Sun на PC-рынке. Отсутствие приличных библиотек и
решений типа RAD-средств и CASE-сред. И может быть еще что-нибудь... Но, время
шло, Java развивалась, обрастала «мясом». Появлялись RAD-среды и CASE-средства.
Потом у Java-ы появилось одно бесспорное преимущество (кроме изначальной
переносимости) – бесплатность! Базовую версию Java Sun позволяет скачать со
своего сайта. Как язык Java оказалась довольно успешна. Она, как и VB 6,
позволила избежать проблем 3GL-языков, и при этом была добротной калькой с C, и
отчасти с C++, что привело к тому, что программисты, не переносившие Паскаль и
VB, но нуждающиеся в средствах быстрой и надежной разработки для создания того
же корпоративного ПО, с удовольствием перепрыгнули на нее. Однако процент
перепрыгнувших оказался невелик. Многие не приняли Java. Но на сторону Sun
встали такие монстры индустрии, как IBM, Oracle и даже сам Microsoft. Такие силы
могут все, что угодно. Шутка ли? Обороты каждой из этих компаний сравнимы, а то
и превосходят бюджет нашей страны! Но Java не была противопоставлена C++. Она
скорее стала конкурентом для VB и Delphi. Появление JavaBeans и, впоследствии,
EJB сделали Java мощной платформой для создания корпоративных приложений.
Единственной проблемой явилось то, что при использовании этих технологий
бесплатность Java кончается, и она становится довольно дорогой технологией. Это
может мало смутить тех, кто до этого пользовался (или собирался пользоваться)
такими дорогими технологиями, как CORBA, но приверженцев Microsoft это резко
останавливало. Microsoft, заинтересованный в продвижении своих ОС, встроил в них
поддержку мощной компонентной архитектуры (COM/DCOM/COM+). И так как ОС покупают
все (правда, в нашей стране иногда ооочень дешево), и покупают чаще всего
Windows, по сути COM является для обывателей бесплатной компонентной
архитектурой, существующей априори.
К чему я веду? Думаю, вы уже догадались! И тут на рынке
появляется Microsoft. Помогая «развивать» Java, Microsoft естественно
схлестнулся с Sun. Microsoft привнесла в Java библиотеку визуальных компонентов,
основанных на быстрых и качественных компонентах Windows (Common Controls), а
также начала изменять язык чтобы сделать Java более высокоуровневым языком (как
VB). Но Sun такое положение вещей не устроило, и Sun подал в суд на Microsoft.
Технически Sun выиграл дело у Microsoft. Microsoft было даже отказано в
продлении лицензии на Java. Однако, Microsoft был бы не Microsoft, если не
попытался бы превратить свой проигрыш в свою же удачу. Sun забыл, что данный
процесс не уничтожит Microsoft, а Microsoft является, как минимум, крупнейшим
игроком на рынке, где должна распространяется (и распространяется, возможно,
пока) Java.
В ответ Microsoft отказался от включения Java в будущие
версии своих операционных систем. В новой Windows XP поддержка Java не
предусмотрена, что вызвало недовольство Sun. Компания обратилась к читателям
нескольких крупных американских изданий с просьбой потребовать от Microsoft
включить поддержку Java в XP, на что вскоре получила от Microsoft вполне
резонный ответ. Microsoft этого делать не собирается, так как у неё уже есть
свой собственный сходный с Java язык – C#. "Sun сделал всё, что только возможно,
чтобы помешать Microsoft распространять их виртуальную машину Java, – говорится
в заявлении Microsoft. – Они потратили несколько лет на судебный процесс, требуя
от Microsoft прекратить распространение высокопроизводительной виртуальной
машины Java, которая использует все даваемые Windows преимущества".
Так что, по мнению Microsoft, удивляться нечему: "Sun
получила, что хотела – прекращения действия нашей лицезии на Java и
договорённости, что Microsoft откажется от использования виртальной машины Java".
Как бы то ни было, большинство программистов вообще не
воспринимает всерьез ни Java, ни C#. Какие же доводы они приводят? Первый – эти
языки (и сами платформы) значительно уступают «родному» коду в
производительности. Второй – такие языки не универсальны, и с их помощью можно
решать очень ограниченный круг задач.
И впрямь, такие недостатки могут отпугнуть большую часть
программистов. Даже программисты, занимающиеся созданием ПО для бизнеса, хотят
иметь максимально быстрый код и гибкие средства разработки. Хотя бы, чтобы в
случае отсутствия нужной функциональности в библиотеках, иметь возможность
написать такую функциональность самостоятельно. Ну, и какие могут быть аргументы
в защиту новорожденных? Именно этому вопросу и посвящена данная статья. Забегая
вперед скажу, что слухи о недостаточной производительности runtime-подсистем
Java и .Net сильно преувеличены.
Но, обо всем по порядку... Итак и Java и .Net обладают
неплохими компонентными моделями. (Спасибо Borland и COM-у. Borland за Андреса
Хегелберга (основателя Delphi/Object Pascal), перешедшего в Microsoft, а также
за компонентную модель EJB, созданную при немалом участии Borland. COM-у за то,
что .Net по сути является его логическим развитием.) И Java и .Net являются
переносимыми платформами (если в случае с .Net это пока только декларация, то
Java уже перенесена на большое количество аппаратных платформ). И Java и .Net
содержат много новаторских идей, упрощающих и ускоряющих производство ПО. Лозунг
средств разработки нового поколения: простота и скорость разработки как у VB.
При наличии таких преимуществ можно пожертвовать и производительностью конечного
ПО! Но, естественно, в разумных пределах.
В интернете можно найти несколько статей, пытающихся
доказать, что производительность Java не только не ниже C++, но в некоторых
условиях и выше! К сожалению, все они не содержат более менее серьезного
анализа, а пытаются доказать то или иное на базе некоторого алгоритма. И то ли
по чистой случайности, то ли по злому умыслу код этих примеров использует
ограниченный набор возможностей языка/платформы и довольно сложен.
Ограниченность не дает возможности делать выводы о производительности в реальных
условиях, а сложность позволяет реализовать примеры по-разному, приводя к
бесполезности сравнения. К тому же в тестах, обычно, происходит сравнение с
довольно экзотическими компиляторами C/C++, упуская из виду другие средства.
Учитывая все вышесказанное и то, что в ближайшее время многие программисты будут
стоять перед нелегкой проблемой выбора, мы и решились протестировать наиболее
популярные средства разработки.
Как и зачем мы тестировали
Проанализировав ошибки, допущенные нашими предшественниками,
мы пришли к выводу, что нужен не один интегральный тест, а несколько маленьких
независимых тестов. Каждый из них должен (по возможности) представлять собой
узкую, но часто встречающуюся задачу. Главной задачей тестирования было
определение скорости выполнения одного и того же алгоритма, скомпилированного
разными компиляторами. Сначала пример реализовывался на C++, после чего
переписывался на другие языки. При этом стояла задача переписать как можно ближе
к эталону. Некоторые скидки были сделаны для Delphi – из-за особенностей языка
Object Pascal. В основном они заключались в том, что в отличие от остальных
языков Delphi по умолчанию передает все параметры по значению. Причем это
относится и к массивам. Мы попросту не смогли бы выполнить наши тесты на Delphi,
если бы не указывали Delphi, что массивы и другие объемистые параметры должны
передаваться по ссылке. Для одного из тестов нам понадобился массив, содержащий
примерно 100 мегабайт данных, и Delphi, невзирая на размер, пыталась положить
его в стек. При этом суть ошибки была не совсем очевидна. Посудите сами. Тот же
код в других языках работал нормально, диагностические сообщения времени
выполнения зависели от настроек компилятора, а сама ошибка появлялась при вызове
(в коде, сгенерированном Delphi).
Мы старались изолировать тесты, делая их как можно более
независимыми от конкретных библиотек и рантайм-кода, но, к сожалению, это не
всегда возможно. Там, где такие зависимости (по нашему мнению) имели место, мы
дали комментарии. Их можно увидеть в объяснениях к каждому тесту.
Аппаратура
Тестирование производилось на двух компьютерах:
| Процессор |
PIII 800 EB (800 MHz с шиной 133 MHz) |
AMD Atlon 1400 MHz с шиной 266 MHz (DDR) |
| Chipset |
Intel 443 BX |
AMD 761 |
| Память |
384 МБ PC133 (133 MHz) |
512 МБ PC2100 (266 MHz DDR) |
Тесты производились в оперативной памяти, поэтому другие
подсистемы не должны были влиять на скорость работы тестов. Вследствие этого мы
опустили описание дисковой и видео- подсистем. При выполнении тестов другие
тесты и ненужные программы выгружались из памяти. Размер памяти используемой для
некоторых тестов выбирался так, чтобы при выполнении тестов не начинался
свопинг, и чтобы время выполнения теста было отчетливо видно на глаз, т.е. было
в пределах от 5 до 30 секунд. Не всегда это удавалось, так как на некоторых
тестах разрыв был слишком велик.
Тестирование на двух машинах интересно еще и тем, что второй
компьютер – это довольно современная машина, собранная на вызвавшем немалые
споры процессоре AMD. В интернете есть много тестов и споров, но большинство из
них меряет производительность жестких дисков и видеоподсистемы, да еще вдобавок
округляя результат и доводя его полезность до уровня средней температуры по
больнице. Надеюсь, наш тест даст более полезные результаты.
Чтобы повторить наши тесты, нужно скачать с нашего сайта ftp://ftp.k-press.ru/pub/cs/2001/3/PerfTest/PerfTest.zip
(www.k-press.ru/ftpmir/pub/cs/2001/3/PerfTest/PerfTest.zip), содержащий тестовые
проекты. Перед выполнением тестов обязательно нужно скомпилировать проект
TestUtils и зарегистрировать получившийся COM-сервер. В нем есть два метода,
позволяющих замерить и вывести время, затрачиваемое на каждый из тестов (кроме
Java). Для тестов, связанных с массивами и сортировками, необходимо создать
zip-файл с названием q3.zip (вы не ошиблись, так и есть). Естественно,
содержимое архива значения не имеет, главное, чтобы размер был не менее 100 МБ.
Этот файл следует поместить в каталоге, содержащем проекты тестов (т.е. PerfTest).
Если у вас этот каталог называется как-то иначе, измените путь к файлу в коде
тестов. При создании zip-файла нельзя использовать нулевое сжатие (мы
использовали максимальное сжатие). На компьютере, где производятся тесты, нужно
иметь не менее 256 МБ RAM. При тестировании Java использовался JDK1.3.1–b24 (Java
HotSpot Client VM), который можно скачать с сервера java.sun.com. Для запуска
Java-примера необходимо запустить bat-файл run.bat из подкаталога Java. Перед
запуском в нем нужно прописать путь к JDK. По умолчанию используется C:\jdk1.3.1.
Для выполнения остальных примеров достаточно открыть и скомпилировать
соответствующие файлы проектов. Другие используемые продукты: Delphi 6.0, VC 6.0
SP4, VB 6.0 SP4, Intel C++ compiler 5.0, C# 1.0 beta 2 (VS.Net Enterprise
Edition beta 2).
Благодарности
Хочется выразить благодарность всем тем, кто давал советы и
критиковал нашу работу в разных Интернет-форумах. Особо благодарим Алексея
Зоркальцева (известного в форумах www.rsdn.ru
как ZORK), написавшего большую часть Java- теста и давшего немало ценных
советов.
Тесты
Итак перейдем к самим тестам.
Первый тест, который пришел нам в голову – это тест,
позволяющий определить стоимость одного вызова.
Вызов метода объекта (Mehod call)
Описание
При написании теста во главу угла ставилась задача применения
наиболее эффективного способа вызова из доступных в тестируемом средстве. И
здесь не так все просто. Дело в том, что не все средства создают оптимальный код
по умолчанию. Из всех протестированных средств только Delphi и C# используют
быстрые алгоритмы по умолчанию. Причем в C# изменить это условие можно только
при взаимодействии с внешним миром. C++, по крайней мере VC, позволяет задавать
тип вызова в настройках, но не все библиотеки совместимы с такими настройками.
Java и VB вообще не дают управлять этим параметром. И самое забавное, что Java
по умолчанию вообще использует вызов через виртуальную таблицу. Можно конечно
спорить насчет того, что это повышает гибкость, но скорости это точно не
прибавляет. К счастью, в Java есть способ отключить вызов через виртуальную
таблицу. Для этого метод нужно пометить ключевым словом final. Такая пометка
позволяет увеличить скорость вызова примерно вдвое! Ключевое слово final можно
задавать и классу целиком. При этом все методы становятся final, и
соответствующим образом вырастает производительность. Но final нельзя
использовать всюду. Класс, помеченный как final, не может иметь наследников.
По-моему, это неудачное решение. Ведь большинство программистов не использует
это ключевое слово вообще, или использует его очень редко. В любом случае, если
вы пишете, или когда-нибудь будете писать на Java, не пренебрегайте этим
ключевым словом. При наличии большого количества вызовов оно может дать большой
выигрыш в производительности. Но помните, экономить нужно только там, где это
нужно.
Сам метод представляет из себя процедуру, получающую четыре
параметра плюс ссылку на класс. Вот его описание на C++:
void CTest1::Test(int i, double d, short sh, LPTSTR sz)
{
}
Как видите, метод не содержит ни одного оператора. Это
позволяет оценить накладные расходы именно на вызов метода, а не на другие
операции.
Результаты
| |
PIII 800 |
AMD 1400 |
| в секундах |
| C# (.Net) |
2.51 |
2.16 |
| Java3 |
8.90 |
4.20 |
| VC 61 |
13.89 |
0 / 5.78 |
| Intel C++1 |
0.00 |
0 / 6.32 |
| Delphi |
17.58 |
6.50 |
| VB 62 |
493.97 |
204.00 |
Примечания:
-
Intel C++ compiler в режиме максимальной оптимизации (/O3 /QaxK
или /O3 /QaxM) интерпретировал пустые или содержащие мало кода функции как
inline-функции. В результате этого метод Test и его вызовы были полностью
соптимизированы, то есть выброшены из программы и заменены на конечный
результат. Надо признать, что если в VC-варианте реализацию методов оставить в
теле класса (даже без пометки их как inline) VC начинает делать то же самое
(так как таким образом объявленные методы считаются inline по умолчанию). Но
качество оптимизации у VC оказалось несколько лучше, и он смог больше кода
привести к статическим расчетам. В VC есть также и отдельная опция (/Ob2),
заставляющая интерпретировать все (по выбору компилятора) вызовы как inline.
Ее установка тоже приводит к тому, что этот тест полностью оптимизируется в
статическое вычисление. Однако для чистоты эксперимента мы приводим время,
которое требуется для вызова метода. На практике есть смысл включать эту
опцию, поскольку объем кода при этом увеличивается не так радикально, а
производительность может вырасти значительно.
-
VB 6 не может создавать классов в полном понимании ООП.
Вместо этого он создает COM-объекты. Вызов метода COM-объекта медленней, чем
fastcall, применяемый в других языках, но даже это не может оправдать таких
«зверских» накладных расходов. VB-программистам можно посоветовать побыстрее
перейти на VB.Net, а пока этого не произошло, избегать частых вызовов функций
(особенно из отдельных классов) и реализовывать критичные к скорости алгоритмы
на C++ (запаковывая их в методы COM-объектов и DLL-библиотек).
-
Для оптимизации теста в Java к классу был применен
модификатор final. По умолчанию все методы в Java являются виртуальными.
Причем, в отличие от C++ и C#, Java от Sun не пытается вычислить, что метод
можно вызывать без виртуальной таблицы. Это приводит к замедлению работы.
Методы, помеченные как final, становятся не виртуальными. Мне кажется,
идеология C++ (принятая в C# и Delphi) более практична, но это сугубо личное
мнение. К сожалению (несмотря на вкусы), final приводит к некоторым
нежелательным последствиям. Так, метод, помеченный этим модификатором, не
может быть «перебит» в классе-наследнике, а если помечен класс, то от него
вообще нельзя порождать потомков. Конечно, можно забыть про final, но как
показывают наши испытания, если закомментировать final в описании класса
CTest1, скорость вызова метода падает с 4.13 до 14.47, т.е. почти в три раза.
Что же поделаешь – расплата за универсальность. Надо заметить, что остальные
языки этого обзора по умолчанию создают обычные (не виртуальные) методы. Чтобы
сделать метод виртуальным, необходимо пометить его специальным ключевым словом
(обычно virtual). Исключением является VB 6. Он вообще не поддерживает
наследования, и, как следствие, виртуальных методов. Однако, по иронии судьбы,
так как классы VB 6 являются COM-объектами, вызовы все равно делаются через
виртуальную таблицу (необходимую для реализации COM-интерфейса).
Выводы по тесту
Как ни странно, языки, которые (по сложившемуся мнению)
должны были стать аутсайдерами, таковыми не оказались. Правда, у старичка C++
есть одно преимущество – модификатор inline. Он позволяет указать компилятору,
что тело метода нужно подставлять в точку вызова. По умолчанию при рекурсивном
вызове подстановка не осуществляется, но этим можно управлять, задавая
количество подстановок. В умелых руках inline может стать инструментом повышения
производительности, но это не панацея и применять его нужно с умом. Компиляторы
C++ научились самостоятельно принимать решение, какие функции лучше сделать
inline. Это позволяет добиться повышения производительности, даже не обладая
большим опытом. К сожалению, остальные компиляторы не проявили таких же
способностей, хотя в документации по некоторым из них указано, что компиляторы
умеют делать подстановки. А жаль – ведь inline позволяет не только избежать
накладных расходов, связанных с вызовом метода (закладку параметров,
откручивания стека...), но и дает компилятору производить оптимизацию на уровне
метода, в который вложен вызов метода помеченного как inline. Это может дать
значительный выигрыш. Единственный, кто, похоже, был близок к автоматической
подстановке – это C#. Скорость вызова метода в нем была потрясающей. Я
специально сделал тест: цикл, в теле которого выполнялась одна ассемблерная
команда NOP или XOR EAX, EAX (выполнение ассемблерной команды приводит к тому,
что оптимизатор не решается превратить пустой цикл в константное вычисление.).
Так вот, результат был практически таким же, как у C#-теста. Это говорит о том,
что внутри пустого метода не делается ничего лишнего. Но! Но все же C# не смог
оптимизировать весь код целиком, превратив цикл в константное вычисление. Видимо
причина в том, что компилятор C# производит оптимизацию только внутри одного
метода. В документации по C# сказано, что он должен по своему усмотрению делать
методы inline, на практике это оказалось не так. Надеюсь, что следующие версии
компиляторов, участвующих в обзоре, или научатся самостоятельно раскрывать
маленькие функции, или обзаведутся ключевыми словами аналогичными inline-у из
C++. Хотя второй вариант является спорным. Ведь компилятору доступно больше
информации, чем программисту, и при наличии грамотного алгоритма автоматический
вариант может оказаться эффективнее. Косвенным подтверждением тому является
ситуация с модификатором register из C++ (предназначенным для указания
компилятору, что переменная должна быть размещена в одном из рабочих регистров
процессора), которая игнорируется многими компиляторами при включении
максимального уровня оптимизации по скорости.
Хочется предупредить, что по показателям этого теста нельзя
судить об общей производительности компиляторов. Во-первых, отсутствие кода в
методе позволяет некоторым из них применить простые приемы оптимизации, которые
могут быть непригодны в более сложных условиях, а во-вторых, в большинстве
случаев время вызова метода не является критичным. Но ООП тяготеет к разбиению
программы на множество маленьких процедур, и высокий показатель в этом тесте
несомненно является признаком хорошего тона для любого компилятора ООЯ.
Итак безоговорочным победителем этого теста стал C#. На
втором месте Java. Но победа эта, от части, пиррова, так как оба компилятора
пока не умеют заниматься подстановкой тела метода и не делают эффективной
глобальной оптимизации.
Вызов виртуального метода объекта (virtual mehod call)
Описание
Тест вызова виртуальных методов призван оценить насколько
эффективно производится вызов этого типа. Наследование бессмысленно без
виртуальных методов. Вместе они являются средствами, с помощью которых можно
осуществить на практике принцип полиморфизма.
Сам метод представляет из себя процедуру, получающую четыре
параметра плюс ссылку на класс. Все как в прошлом тесте, но метод теперь
виртуальный. Вот его описание на C++:
virtual void __fastcall TestVirtual(int i, double d, short sh, LPTSTR sz);
{
}
//...
class CTest2 : public CTest1
{
public:
virtual void __fastcall TestVirtual(int i, double d, short sh, LPTSTR sz);
};
Чтобы компилятор не мог отвертеться от виртуального вызова (ну, или с целью
максимально усложнить ему эту задачу) был введен дополнительный класс. А вот код
вызова:
CTest2 test2;
CTest1 & test1 = test2;
m_spIUtility->TimerStart();
for(int i = 0; i < iInitVal; i++)
{
test1.TestVirtual(i, 3.123, 1, _T("Some string"));
}
m_spIUtility->TimerEnd(/*sbsInfo*/);
Как видите, создается экземпляр класса CTest2, но сразу же
помещается (приводится) в ссылке на класс CTest1. Это заставляет вызывать метод
TestVirtual через виртуальную таблицу.
Результаты
| |
PIII 800 |
AMD 1400 |
| в секундах |
| VC 61 |
15.10 |
5.8 / 6.49 |
| Intel C++ |
15.08 |
6.50 |
| Delphi |
21.35 |
7.01 |
| C# (.Net) |
15.66 |
7.22 |
| Java3 |
29.15 |
14.48 |
| VB 62 |
- |
204.00 |
-
Первый результат VC – это результат, полученный при
установленной опции, позволяющей компилятору автоматически делать
inline-подстановки функций.
-
У VB 6 нет понятия наследования, а значит, нет и
виртуальных методов. Однако, как уже говорилось, все методы объектов в VB
являются методами COM-интерфейса, а значит пользуются техникой виртуальных
таблиц. Т.е. любой метод в VB является виртуальным. Однако, повторюсь, таких
тормозов это не объясняет.
-
Лидер нашего первого теста оказался в аутсайдерах в этом
тесте. Но не это больше всего огорчает, а огорчает тот факт, что в Java все
методы по умолчанию являются виртуальными. На практике это может привести к
тому, что Java-приложение окажется медленнее, чем приложения на других языках,
и виной тому будет не слабость JIT-компилятора, а просто невнимательность или
незнание программиста. Мне кажется не очень правильным перекладывать вопросы
производительности на программиста. Ему ведь и так достанется. Но многие
Ява-программисты считают по-другому. Так, что вам решать хорошо это или плохо.
:)
Выводы по тесту
В этом тесте старичок C++ вырвался вперед, но надо отметить
Delphi и C#. Они показали очень неплохие результаты. Для Delphi результат был
близок к прогнозируемому. Время увеличилось, но не значительно. На столько, по
нашим расчетам и судя по C++ тесту, и должно было замедлиться выполнение при
вызове виртуального метода. А вот C# показал результаты несколько странные.
Сдается, что все-таки компилятор C# в первом тесте соптимизировал пустой метод,
превратив его в inline, но не сумел произвести глобальную оптимизацию. В
результате скорость вызова оказалась высокой, но бесполезный цикл занял
некоторое время. Будем надеяться, что отсутствие глобальной оптимизации не
является особенностью архитектуры, и в будущем мы получим еще большую
оптимизацию от CLR-совместимых языков.
Аутсайдерами стали Java и VB 6. С выпуском VS.Net VB 6 уже
вряд ли придется претендовать на место на рынке, и его можно смело списать со
счетов. Java же является одним из мощных игроков на рынке, и отставание вдвое от
C# и Delphi не прибавляет ей очков. Разница между лидером (VC) и Java оказалась
близка к троекратной. Про VB говорить вообще не приходится.
Наши первые два теста мало показательны, хотя и интересны для
синтетического сравнения. Перейдем к более сложным тестам.
Доступ к членам класса
Описание
Данный тест должен был продемонстрировать, насколько
оптимально компиляторы осуществляют доступ к членам класса. Современные
программы изобилуют обращениями к небольшим функциям, производящим доступ к
полям класса. Скорость выполнения этого теста зависит от того, насколько
оптимально производится вызов метода, и от грамотности обращения к полям. Вот
код вызываемого метода:
void CTest1::Inc()
{
m_i++;
//m_i = m_i + 1;
}
И вызова:
for(int i = 0; i < c_iCount; i++)
{
test1.Inc();
}
Максимально оптимизированный код (конечно, если при
оптимизации цикл не будет приведен к константному вычислению) должен выглядеть
как инкремент некой области памяти, а лучше регистра. Но это оптимальный
(гипотетический) вариант. На практике до инкремента регистра не додумался не
один компилятор, но многие были очень близки к идеалу. Мы также проверили
компиляторы на вшивость, подсунув им вместо операции инкремента обычное
присвоение (код приведен в комментарии). К чести современных компиляторов (по
крайней мере VC 6 и Delphi, над которыми собственно и производился эксперимент),
они правильно распознали наш коварный замысел и превратили сложение переменной с
собой же в инкремент.
Результаты
| |
PIII 800 |
AMD 1400 |
| в секундах |
| C# (.Net) |
3.99 |
3.54 |
| Delphi |
8.79 |
4.34 |
| Java |
7.55 |
4.85 |
| Intel C++ |
8.80 |
5.04 |
| VC 61 |
8.84 |
1.44 / 5.06 |
| VB 6 |
118.69 |
76.53 |
-
Первая цифра в тесте VC была получена с включенной опцией
«inline-подстановки (раскрытия) функций в любом подходящем случае».
Выводы по тесту
Победителем этого теста стал VC в режиме автоматического
подбора функций на роль inline и C#, так сказать, в общем зачете. Надо отметить
и неплохой результат Delphi и Java, обогнавших C++-компиляторы, работавшие в
обычном режиме оптимизации. Не известно, что вытворял компилятор VB 6, но ему,
несомненно, удалось отличиться. :) Столь медленное выполнение столь простой
операции нельзя объяснить ничем.
Quick Sort (быстрая сортировка)
Этот тест определяет быстродействие кода, производящего
большое количество перестановок и сравнений. Все операции производятся с 32-х
битными целочисленными значениями. Большое значение здесь играет оптимальность
работы с массивами, так как runtime-проверки и простая неоптимальность могут
существенно снизить скорость выполнения этого теста. Надо заметить, что C++ не
имеет средств контроля выхода за пределы границ массивов, и при переписывании
кода на него (изначально алгоритм был доступен как код на Java), была сделана
ошибка, приводящая к выходу за пределы массива. Тем не менее, тест был
скомпилирован и прошел без единого замечания от компилятора и runtime-среды.
Ошибка была выявлена, когда код переносился на C#, встраивающий код, делающий
такие проверки. Однако runtime-проверки приводят к заметному замедлению в
работе. Но не будем забегать вперед. Вернемся к тесту...
Современные процессоры довольно мощны и, если не использовать
дико не эффективных алгоритмов, требуют серьезных объемов данных или большого
количества повторений, чтобы время теста можно было заметить на глаз. Для
быстрой сортировки потребовался массив размером ~100 мегабайтов (точнее
100 000 000 байтов). К счастью тестовые машины были оснащены 384 (PIII800) и 512
(AMD1400) MB RAM. Чтобы тест был как можно более приближен к реальным условиям,
нужен был источник данных с максимальной случайностью и уникальностью.
Требовалось также, чтобы данные были одинаковы для всех программ. Таким
источником стал zip-файл размером несколько большим, чем требовалось. Он был
создан при использовании максимального сжатия. Выкладывать такой файл в Интернет
не имеет смысла, поэтому, если у вас возникнет желание повторить наши
эксперименты, то просто создайте такой же файл самостоятельно. Результаты при
этом могут отличаться, но, во-первых, незначительно, а во-вторых, главное – не
сами числа, а сравнение производительности продуктов.
Вот код функции сортировки на C++:
template <class SType>
void __fastcall QuickSort(SType *item, int left, int right)
{
int i, j;
SType center;
SType x;
i = left;
j = right;
center = item[(left + right) 2];
while(i <= j)
{
while (item[i] < center && i < right)
i++;
while (item[j] > center && j > left)
j--;
if (i<=j){
x = item[i];
item[i] = item[j];
item[j] = x;
i++;
j--;
}
}
if(left < j)
QuickSort(item, left, j);
if(right > i)
QuickSort(item, i, right);
}
Как видите, она сделана в виде шаблона. Этого не требовал
тест, но, поскольку реализация шаблонной функции по сложности почти не
отличается от реализации функции с жестко заданными типами, мы реализовали ее
как шаблон. Главным побудительным мотивом стал тот факт, что ни один язык
(естественно, кроме C++) из попавших в этот обзор, пока не поддерживает
Generic-типов (или в терминологии C++ – шаблонов). А ведь это замечательное
средство, позволяющее писать чистые алгоритмы, не спускаясь к бренным типам. :)
Отсутствие Generic-типов в языках приводит к тому, что приходится делать
универсальные процедуры (вроде рассматриваемой нами сортировки) с помощью
средств полиморфизма (виртуальных функций и наследования от базовых типов). И
всегда это приводит к снижению эффективности таких реализаций. Многие считают,
что компиляторы C выдают самый быстрый код. Но это заблуждение. Код, выдаваемый
компилятором C++, примерно аналогичен коду на C. В некоторых случаях это просто
один и тот же компилятор, и было бы странно получить разные результаты на
одинаковом коде. Но предположим, мы хотим создать универсальную процедуру
сортировки.
Вот прототип C-реализации:
void qsort(
void *base,
size_t num,
size_t width,
int (__cdecl *compare )(const void *elem1, const void *elem2 )
);
Реализация довольно простого алгоритма занимает в CRT от MS
довольно много места. Причем там производится дополнительная оптимизация (уход
от рекурсии, короткая сортировка). Но все это не спасает. Аналогичная функция,
написанная на C++ в лоб, но с использованием шаблонов, а не C-выкрутасов,
выигрывает в скорости в 1.5 раза! Выигрыш, конечно, заключается не в чародействе
шаблонов, а в том, что C++-вариант не содержит дорогостоящих вызовов функции
сравнения, которая мало того что получает два указателя через стек, так еще и
сама вызывается по указателю. Конечно, и в C можно сделать неуниверсальную
функцию (для отдельного типа данных), которая будет работать с такой же
скоростью. Но это приведет к сильному увеличению количества кода, а значит,
ошибок и головной боли. Решение на шаблонах вкупе с inline-функциями позволяет
делать максимально быстрые алгоритмы, не жертвуя при этом универсальностью.
Создатели Delphi жестко придерживаются мнения, что их язык
предназначен для решения прикладных задач и его нельзя усложнять «лишними
конструкциями». Примерно так же обстоят дела и с VB (как с 6-й версией, так и с
VB.Net). А вот с C# и Java дела обставят по-другому. Java-консорциум уже принял
решение и в следующей версии в Java появятся шаблоны (возможно, под другим
названием). С C# пока ясности меньше. Ясно только, что в первую версию (которая
должна появиться в начале следующего года) шаблоны не войдут. Но делаются
заявления, что шаблоны (скорее всего под именем generic) будут добавлены в
следующих версиях. И эти заявления подкреплены готовой спецификацией «Design and
Implementation of Generics for the .NET CLR» сделанной Andrew Kennedy и Don Syme
из Microsoft Research, Cambridge, U.K. В ней на 11 страницах даны концепция,
синтаксис гипотетического расширенного C#, изменения в IL и теоретические
выкладки. В общем, похоже, и Java и C# получат в свое распоряжение бесспорно
мошьное и гибкое средство – шаблоны. Мы попытались заменить функцию, написанную
нами специально для типа данных Int32, на универсальную функцию
System.Array.Sort из стандартной библиотеки .Net. При этом время сортировки
составило 14.64 секунд (на AMD1400) против 9.17 секунд нашей реализации. Т.е. из
лидера C# превратился в аутсайдеры. Что же приводит к таким печальным
последствиям? Дело в том, что универсальность в C# достигается за счет
использования средств полиморфизма, а это приводит к лишним вызовам. Если бы
была возможность реализовать generic-тип-массив, пометив функции сравнения и
перестановки элементов как inline, можно было бы достичь той же универсальности
без потерь производительности.
Но вернемся к нашему тесту. Загрузка данных в массив
производится практически одинаково на всех языках, кроме Java, которая не имеет
прямого доступа к Win32 API. На остальных языках загрузка производится с помощью
функции ReadFile. Первые версии C#-теста пользовались встроенными возможностями
CLR, но в виду отсутствия в .Net средств загрузки массивов целых, относительно
медленному процессу поэлементной загрузки данных и просто с целью протестировать
возможности C# и CLR по взаимодействию с «неуправляемым миром», код был
переписан с применением Win32 API-функций. Надо заметить, что это резко подняло
производительность. Хотя если бы в .Net были включены необходимые нам функции,
выигрыш мог бы быть несущественным.
Результаты
| |
PIII 800 |
AMD 1400 |
| в секундах |
| VC 61 |
16.61 |
8.58/ 8.70 |
| C# (.Net)2 |
16.73 |
9.50 / 9.17 |
| Intel C++ |
17.63 |
9.20 |
| Delphi3 |
16.77 |
13.59 / 9.60 |
| Java |
24.49 |
12.50 |
| VB 6 |
27.01 |
14.07 |
Первый результат VC – это результат, полученный при
установленной опции позволяющей компилятору автоматически делать
inline-подстановки функций.
Тест C# был сделан в двух видах – нормальном и «unsafe». Как вы наверно уже
догадались, первая цифра – это время в нормальном, а вторая в unsafe-режиме. В
нормальном режиме компилятор C# вставляет проверки выхода за границы массива.
Отключить такие проверки невозможно, но C# поддерживает unsafe-режим. В этом
режиме C# превращается в старый добрый C, позволяя пользоваться указателями.
Причем C# имеет конструкцию fixed позволяющую превратить в указатель любой тип
C#. При этом в следующем выражении (в одном или в блоке) можно безопасно
пользоваться указателем. Вам гарантируется, что сборщик мусора не переместит
или освободит память, занятую объектом. После выхода из области действия
конструкции fixed указатель становится не действительным, а памятью снова
начинает управлять сборщик мусора. Именно этим мы и воспользовались чтобы
выяснить на, что способен C#, если программист не боится сложностей и готов на
все. :) Пример сделан таким образом, что можно быстро закомментировать
небезопасный код (см. комментарии в коде) и оставить только безопасную часть
кода.
Вот нормальное объявление метода:
static void QuickSortInt(int[] item, int left, int right)
Первый параметр – это управляемый массив целых. При обращении к его
элементам C# и вставляет те самые проверки. А вот хакерский вариант:
unsafe static void QuickSortInt(int[] aitem, int left, int right)
{
fixed(int * item = aitem)
{
QuickSortInt(item, left, right);
}
}
unsafe static void QuickSortInt(int * item, int left, int right)
...
- Как видите, вместо одного объявления появилось два. Первое, как и раньше,
содержит привычное для C# описание, а второе более стандартно для C.
Конструкция fixed позволяет перевести управляемый массив в неуправляемый
указатель. Чтобы использовать эти хакерские возможности языка, необходимо
пометить использующий их код как unsafe. При этом в опциях проекта нужно
включить поддержку небезопасного режима.
- По неизвестным соображениям при выполнении C#-теста Quick Sort разница в
скорости между Intel и AMD была минимальна, но в следующем тесте тот же прием
дал значительный прирост производительности.
-
В Delphi runtime-проверки выхода за пределы массива и
переполнения можно включать или отключать в свойствах проекта. Первое число в
таблице – результат с отключенными runtime-проверками, а вторая – с
включенными. Если же проверки включить, Delphi начинает делить последнее место
с VB 6, проигрывая всем остальным участникам, выполняя этот тест за 13.59 на
AMD1400. Хочется сделать еще одно замечание. Мы наступили на забавные, но
потенциально очень неприятные грабли. Дело в том, что все современные языки
умеют передавать параметры методов как по значению, так и по ссылке. В Delphi
для этого используется ключевое слово var. Его необходимо указывать перед
параметрами. Все это понятно, но Delphi оказалась единственным компилятором
требующим указания модификатора передачи параметра по ссылке для массивов.
Оказалось, что Delphi с упорством, достойным лучшего применения, запихивает
массив в стек. Думаю, не надо разъяснять, как такая «забота о программисте»
отражается на производительности. Но производительность страдает при
относительно небольших размерах массивов, в нашем же случае один из массивов
имел размер немногим менее ста мегабайт... Получив сообщение об ошибке, мы
попробовали трассировать программу под отладчиком, но не тут то было. Пару раз
Delphi попросту зависло, еще пару выдало загадочное сообщение. Да и сама
ситуация сбивала с толку. Ну, да ладно... Через пару минут тупого
разглядывания кода мы поняли, в чем проблема, и устранили ее. Мы понимаем, что
сами виноваты, но надо было слышать те слова, которыми мы вспоминали в эти
минуты Borland и все компьютеры вместе взятые. :)
Выводы по тесту
VB 6 показал худший результат и на более серьезном тесте.
Однако, отставание уже не так существенно. Так что списывать его со счета еще
рано. Вторым (с конца) оказалась Java. Победителем стал VC 6. Особенно быстро
выполнялся тест, скомпилированный с опцией, заставляющей автоматически делать
inline-подстановки. Остальные участники теста показали примерно одинаковое
время. Здесь хочется отметить C#, который добился такого неплохого результата,
делая при этом runtime-проверки выхода за пределы массива. Ниже приведено
изображение диалога сообщения об ошибке выхода за пределы массива в C#.
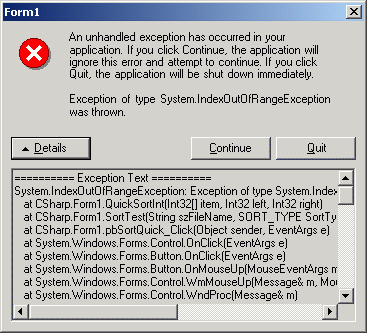
Ошибка была симулирована нами специально, и C# не подкачал.
Удивительно, как C# умудряется показывать такую производительность и делать
runtime-проверки! Да еще и выдает неплохие для release-версии диагностические
сообщения.
А вот Intel C++ показал себя не самым лучшим образом, хотя и
занял второе место. Компилятор от производителя процессора мог бы быть и
пошустрее.
Пузырьковая сортировка
Это самый глупый алгоритм сортировки из известных
человечеству. Главным его преимуществом для нас является способность загрузить
любой процессор на смехотворно малых объемах данных. Это позволяет снизить
влияние времени копирования больших блоков памяти, поднимая требования к
качеству оптимизации.
Вот код этого алгоритма на C++:
template <class SType> void BubbleSort(SType *item, int left, int right)
{
int i, j;
SType x;
for(i = left + 1; i <= right; i++)
for(j = right; j >= i; j--)
if(item[j - 1] > item[j])
{
x = item[j];
item[j] = item[j - 1];
item[j - 1] = x;
}
}
Удивительно, как столь лаконичный алгоритм может быть столь
«тормозным»! :)
Результаты
| |
PIII 800 |
AMD 1400 |
| в секундах |
| Intel C++3 |
7.23 |
4.85 |
| VC 63 |
7.20 |
5.02 |
| C# (.Net)2 |
8.16 |
6.20 / 5.29 |
| Delphi1 |
9.53 |
12.31 / 5.33 |
| VB 61 |
14.48 |
21.76 / 8.46 |
| Java |
20.63 |
10.37 |
-
Цифра, приведенная перед результатами тестов Delphi и VB 6
– это время выполнения этого теста с включенной проверкой выхода за границы
массивов. Она приведена не для того, чтобы как-то унизить эти средства
разработки, а чтобы вы могли оценить качество реализации алгоритма проверки
выхода за границы массива в Java и C# (в остальных языках такие проверки не
реализованы). Заметьте, время Java, языка, который мы считаем
интерпретируемым, оказалось вдвое меньшим, чем у VB 6, и на 20% меньшим, чем у
Delphi, которая без этих проверок показала результат близкий к лучшему. C#
вообще был вне конкуренции в этой области. 6.2 – это результат, достойный
компилятора, не выполняющих никаких runtime-проверок. Но, похоже, это
результат не предел. Господа из Microsoft уже поговаривали о верификации кода.
Правда, эти разговоры были связаны с безопасностью, но кто мешает вместо
выполнения runtime-проверок заняться интеллектуальной деятельностью? Конечно,
из-за того, что не вся информация доступна во время компиляции, нельзя
заменить все runtime-проверки на статический анализ, но можно же вынести
проверки из тел циклов и рекурсивных функций.
-
Как и в прошлом тесте, в этом приводятся результаты работы
теста C# в обычном и «unsafe» режиме. Выигрыш составил примерно 10%. Оптимист
скажет: есть поле для маневра и ручной оптимизации. Пессимист: можно было бы и
пограмотней проверки вставлять. :) Но как бы то ни было, C# занял первое место
в подпольном тесте на лучшую организацию runtime-проверок. Однако в варианте с
runtime-проверками C# проиграл лидеру почти 30%. Так что Microsoft есть над
чем работать. Ведь тест в unsafe-режиме показал, что разрыв (в 10%) есть и без
runtime-проверок.
-
Разрыв между VC и Intel C++ был настолько мал, что на
разных платформах они заняли разные места. Делая скидку на неточность
вычислений можно даже сказать, что они поделили первое место.
Выводы по тесту
Этот тест стал первым, на котором Intel C++ занял первое
место. Причем сделал он это на процессоре от AMD. :) Отрыв от основной массы
оказался не очень велик, но все же. Программистам же можно посоветовать вообще
не использовать таких алгоритмов. Иначе даже суперпроизводительных процессоров и
гипероптимизирующих компиляторов будет недостаточно, чтобы сделать из вашей
любимой программы-черепашки грациозного гепарда.
Подсчет p
(целочисленные вычисления)
Этот тест рассчитывает число p с
заданной точностью (количеством знаков после запятой). Дело, бесспорно, нужное,
хотя, наверное, большинству из читателей за всю жизнь не приходилось
пользоваться числом, более точным чем 3.14. И уж использование числа
3.141592653589793238462643383279502884197169399375 может показаться
сумасшествием (у нас был соблазн опубликовать результат полностью, но мы
удержались). Так вот, наш тест рассчитывает p с
количеством знаков, равным 15000! Зачем это надо? Да просто чтобы как следует
нагрузить процессор. :) При вычислении сосчитанные знаки помещаются в строку.
Почему в строку? А где вы найдете в современных компьютерах тип данных,
способный хранить такое число? Но относительно количества расчетов размер строки
в 15 000 символов просто меркнет, а поэтому влияние проверок выхода за границы
строки можно не принимать во внимание. В результате тест превращается в чисто
целочисленные вычисления. Вот его код на C++:
BOOL pi(LPTSTR szPi, const int digits)
{
LPTSTR szCurDigit = szPi;
if (digits > 54900)
{
::MessageBox(::GetActiveWindow(),
_T("n must be <= 54900"),
_T("Error in pi()"), 0);
return FALSE;
}
int d = 0, e, b, g, r;
int c = (digits / 4 + 1) * 14;
int * a = (int*)alloca(c * sizeof(int));
int f = 10000;
for(int i = 0; i < c; i++)
a[i] = 20000000;
while((b = c -= 14) > 0)
{
d = e = d % f;
while(--b > 0)
{
d = d * b + a[b];
g = (b << 1) - 1;
a[b] = (d % g) * f;
d /= g;
}
r = e + d / f;
if (r < 1000)
{
if(r > 99)
{
*szCurDigit = '0';
szCurDigit++;
}
else if(r > 9)
{
*szCurDigit = '0';
szCurDigit++;
*szCurDigit = '0';
szCurDigit++;
}
else
{
*szCurDigit = '0';
szCurDigit++;
*szCurDigit = '0';
szCurDigit++;
*szCurDigit = '0';
szCurDigit++;
}
//pi.Append(zero[r > 99 ? 0 : r > 9 ? 1 : 2]);
}
itoa(r, szCurDigit, 10);
szCurDigit = szCurDigit + lstrlen(szCurDigit);
//pi.Append(r);
}
*szCurDigit = 0;
return TRUE;
}
На C++ код выглядит не очень красиво, так как мы решили не
использовать специальных строковых классов. Специальной цели в этом не было. В
комментариях приведен код, как он выглядел на Яве и C#.
Результаты
| |
PIII 800 |
AMD 1400 |
| в секундах |
| Delphi |
10.34 |
6.80 |
| Intel C++ |
10.08 |
6.84 |
| C# (.Net) |
10.35 |
6.90 |
| VC 6 |
10.76 |
7.17 |
| Java |
10.99 |
7.56 |
| VB 6 |
20.49 |
8.74 |
Выводы по тесту
Это один из двух тестов, где победила Delphi, но отрыв был
минимальным. Результаты почти всех конкурентов находились около планки в 7
секунд (на AMD1400). Отстали снова VB и Java. Но даже VB отстал не очень сильно.
Отдельно хочется заметить отставание (относительное) VC 6. Ведь на предыдущих
тестах он был лидером. Похоже, что целочисленные вычисления – это та область,
где преуспели практически все.
Tree sort
Tree sort – это одновременно один из самых интересных и самых
неоднозначных тестов. Интересен он тем, что в нем основное время тратится на
создание и уничтожение объектов. Мы специально сделали так, чтобы создаваемые
объекты были разного размера (занимали разный объем памяти). Это приводит к
фрагментации памяти и может повлиять на результат теста. Неоднозначен он в
основном тем, что за выделение и освобождение памяти обычно отвечает не сам
компилятор, а та или иная библиотека. Но об этом в выводах, а пока поговорим о
сути теста. Итак, тест заключается в том, что берется массив, заполненный
произвольными 32-битными числами. Из него последовательно берутся элементы. Они
сравниваются с нулем, и, если элемент меньше нуля, создается объект типа
CTestLessZero, если больше – CTestGreatZero, а если равен нулю, то
CTestEqualZero. Все три объекта унаследованы от класса CBase, содержащего поле
m_i, в которое помещается значение, взятое из массива, и три ссылки, m_pGreat,
m_pLess и m_pEqual (в C++ – указатели), на объект того же типа. Каждый из
наследников содержит дополнительные поля, которые изменяют размер объекта и
приводят к фрагментации памяти. Далее (после создания) объекты передаются в
функцию AddNode, которая помещает их в дерево (тут же и создающееся) в
соответствии со значением их элемента m_i. При этом объекты типа CTestLessZero
(содержащие отрицательные значения) помещаются в ветку m_pLess, объекты типа
CTestGreatZero (содержащие положительные значения) помещаются в ветку m_pGreat,
объекты типа CTestEqualZero (содержащие нулевые значения) помещаются в список
m_pEqual. Для каждого объекта находится его место в дереве, и объект помещается
в соответствующую подветку. Если в дереве уже есть объект с таким же значением
поля m_i, то объект помещается в хвост списка m_pEqual этого объекта. В общем,
после всех этих операций создается большое несбалансированное двоичное дерево.
Чтобы это тест вообще мог выполниться, исходные данные должны быть как можно
более уникальны, и их расположение должно быть как можно более хаотично. Для
этого теста (да и для других тоже, но для этого в особенности) нельзя применять
методы генерации случайных чисел, так как результат теста очень сильно зависит
от исходных данных. Zip-файл и тут оказался самым подходящим источником данных.
Он практически не имеет повторений, и данные в нем совершенно хаотичны. Обратите
внимание, что файл для теста нужно создавать при как минимум нормальной степени
сжатия, а лучше и при максимальной. Иначе есть вероятность вообще не дождаться
выполнения теста. Ниже приведен код. Не пугайтесь, это самый большой листинг в
нашем тесте:
// Описание классов
// Базовый класс, содержащий рабочие данные
class CBase
{
public:
inline CBase(const int i) : m_pGreat(NULL), m_pLess(NULL),
m_pEqual(NULL), m_i(i) {}
inline ~CBase()
{
delete m_pGreat;
delete m_pLess;
delete m_pEqual;
}
// Содержит значение, берущееся из массива.
// По значению этой переменной сравниваются классы-потомки.
int m_i;
// Ссылка на объекты, имеющие большее значение m_i
CBase * m_pGreat;
// Ссылка на объекты, имеющие меньшее значение m_i
CBase * m_pLess;
// Ссылка на объекты, имеющие оналогичное значение m_i
CBase * m_pEqual;
};
class CTestGreatZero : public CBase
{
public:
inline CTestGreatZero(const int i) : CBase(i), m_i1(0), m_i2(0), m_i3(0) {}
protected:
// Нерабочие переменные. Нужны для увеличения «веса».
int m_i1;
int m_i2;
int m_i3;
};
class CTestLessZero : public CTestGreatZero
{
public:
inline CTestLessZero(const int i) : CTestGreatZero(i), m_i4(0), m_i5(0) {}
// Нерабочие переменные. Нужны для увеличения «веса».
int m_i4;
int m_i5;
};
class CTestEqualZero : public CTestLessZero
{
public:
inline CTestEqualZero(const int i) : CTestLessZero(i), m_i6(0), m_d(0) {}
private: // private используется в экспериментальных целях.
// Нерабочие переменные. Нужны для увеличения «веса».
int m_i6;
double m_d;
};
// Функция, добавляющая новый объект в дерево с корнем pRoot.
void AddNode(CBase * pRoot, const CBase * pNew)
{
if(pNew->m_i > pRoot->m_i)
{
if(pRoot->m_pGreat)
AddNode(pRoot->m_pGreat, pNew);
else
pRoot->m_pGreat = (CBase *)pNew;
}
else if(pNew->m_i < pRoot->m_i)
{
if(pRoot->m_pLess)
AddNode(pRoot->m_pLess, pNew);
else
pRoot->m_pLess = (CBase *)pNew;
}
else
{
if(pRoot->m_pEqual)
AddNode(pRoot->m_pEqual, pNew);
else
pRoot->m_pEqual = (CBase *)pNew;
}
}
// Функция, создающая объекты разных типов и вызывающая
// функцию AddNode для добавления их к дереву.
void TreeSort(int *item, int left, int right)
{
// В C++ корневой объект создается в стеке,
// что приводит к автоматическому вызову деструктора.
// На других языках приходится поступать по-разному,
// от ручного удаления, до забвения (в C# и Java).
CTestEqualZero Root(0);
CBase * pNewNode = NULL;
for(int i = left; i <= right; i++)
{
const int iCurrItem = item[i];
if(iCurrItem < 0)
pNewNode = new CTestLessZero(iCurrItem);
else if(iCurrItem == 0)
pNewNode = new CTestEqualZero(iCurrItem);
else
pNewNode = new CTestGreatZero(iCurrItem);
AddNode(&Root, pNewNode);
}
}
Результаты
| |
PIII 800 |
AMD 1400 |
| в секундах |
| Delphi2 |
13.96 |
11.40 |
| VC 61 |
14.75 |
11.85 |
| Intel C++1 |
14.67 |
12.31 |
| Java4 |
22.91 |
16.20 |
| C# (.Net)5 |
33.66 |
23.60 |
| VB 63 |
- |
- |
-
При повторном тесте время составило около 35 секунд (что на
VC 6, что на Intel C++) – это при тестировании на AMD, на PIII 800 повторный
тест занял 39.34 секунды. При этом компиляция производилась с многопоточной
версией MFC, а стало быть, и с блокировками при выделении и освобождении
памяти. После перекомпиляции проекта с однопоточной версией MFC повторное
выполнение не приводило к заметному снижению быстродействия. Замедление при
повторных тестах вызвано неоптимальной работой стандартных (Win 32 API)
функций работы с хипом (HeapAlloce/HeapFree) в W2k. По большому счету, ни VC,
ни Intel C++ к этому отношения не имеют. Но тестовое приложение писалось с
использованием библиотеки MFC, которая в release-версии пользуется функциями
HeapAlloce/HeapFree. Мы попытались создать отдельный хип, заменив методы new и
delete. Но это ничего не дало. Единственное, что повлияло – это пересоздание
(уничтожение и последующее создание) хипа перед каждым тестом. При этом время
выполнение теста было одинаковым. К сожалению, в реальных приложениях такие
фокусы проходят с трудом. Но если скорость выделения памяти (а именно она в
основном влияет на скорость создания объектов в нашем тесте) критична для
вашего приложения, и в вашем приложении используется многопоточная библиотека,
можно обратиться к библиотекам сторонних разработчиков. Например, к библиотеке
выпускаемой компанией MicroQuill (www.microquill.com). Судя по рекламе, они не
только используют более быстрые алгоритмы, но и приводят к хорошему
масштабированию на мультипроцессорных системах. Можно также попытаться создать
свою реализацию (вот только не факт, что она окажется более качественной, чем
аналог от Microsoft), попытаться найти бесплатную реализацию или плюнуть, ведь
подобного экстрима не так-то просто добиться в реальной жизни. Надо отметить,
что производительность тестов C++ может резко подняться, если Microsoft
перепишет функции управления хипом в будущих версиях Windows. Проводя
эксперименты, мы выявили некоторую информацию, которая может показаться вам
интересной. Реальное время создания дерева заняло 10 секунд (в тесте на PIII
800). Т.е. 4 секунды производится освобождение занятой памяти. Освобождение
заняло почти половину (!) времени теста, и это при нефрагментированной памяти.
При втором проходе результаты были вообще плачевны. Мы не будем их приводить,
так как не уделили этой проблеме должного внимания.
-
Delphi стала победителем и этого теста. Но это не главное,
в конце концов она не намного опередила своих соперников. Главное, что время
теста Delphi почти не увеличилось (!) при повторном проходе! Это говорит, что
функции работы с хипом в Delphi действительно хороши. И это без дополнительных
библиотек и хитростей. Мы провели препарирование победителя и выявили, что в
Delphi полностью переписана работа с хипом. Для больших кусков памяти
используется прямая работа с VirtualAlloc (и т.п.), а для небольших блоков
памяти создана хитрая структура, группирующая блоки одинакового размера и
хранящая их в отдельных буферах. Чтобы серьезно разобраться в том, как в
Delphi сделаны функции работы с хипом, потребовалось бы слишком много времени,
да и задача эта в наши планы не входила. Тем же, кто хочет знать больше, мы
советуем обратиться к исходникам, прилагающимся к Delphi, благо их никто не
скрывает. Правда, они (как и большая, системная часть кода VCL) не
документированы, так что придется ползти на животе.
-
VB 6, как известно, об объектной ориентации вообще слышал
мало. Он не поддерживает наследования, а стало быть, наш тест в полной мере
выполнить не может. Не будем домысливать, но шансы на серьезные позиции в этом
тесте у него не велики.
-
Java отказалась работать с настройками по умолчанию еще при
попытке загрузки 100 МБ массива, выдав сообщение о нехватке памяти (и это, как
вы помните, при 384 МБ RAM на одной машине, и 512 – на другой). Чтобы
заставить ее поверить, что на машине есть еще оперативная память, нам пришлось
применить не шибко стандартную опцию -Xmx256m, тем самым объясняя Java, что на
машине есть минимум 256 MB RAM, которые она может использовать. Но для данного
теста и этого параметра оказалось недостаточно, и пришлось уверить Java в том,
что на машине есть 400 МБ (с помощью опции -Xmx400m), после чего она-таки
уверовала, что памяти достаточно и смогла выполнить тест. Остальные подопытные
не сомневались в количестве оперативной памяти, но расходовали ее более
экономно. Наличие такой опции само по себе не проблема, но то, что ее значение
по умолчанию не завис от объема оперативной памяти – это плохо.
-
В новые языки/платформы типа C# и Java встроены модные ныне
«сборщики мусора». Это программные сущности, призванные радикально ускорить
выделение и освобождение небольших кусков памяти (так присущих ООЯ). Нам
говорят примерно следующее: GC (сокращение от Garbage Collector) вообще не
занимается лишним освобождением памяти. Вернее, он пытается отложить этот
неприятный (для него) момент на как можно более поздний срок. Т.е. пока есть
свободная память, ее будут занимать, занимать и занимать, а когда память
иссякнет, или когда процессор будет менее загружен, начнется процесс сборки
мусора. При этом процессе выявляются и освобождаются неиспользуемые области
памяти. Используемые области памяти при этом могут передвигаться, наподобие
того, как это происходило в Windows 3x. Красота, да и только! Но, что
характерно, чем громче реклама, тем менее стоящая идея (или реализация) за ней
скрывается. Увы, в случае с GC это правило работает стопроцентно. Ни C#, ни
Java не показали достойного результата. Java была лучше в абсолютном
первенстве на чемпионате для калек, показав относительно неплохой результат в
16.2 секунд, но при повторном тесте ее производительность могла изменяться в
пределах от одной до пятидесяти (50!) секунд. C# показал хотя и стабильный, но
самый низкий результат. Правда, C# (а вместе с ним и вся платформа .Net) пока
еще находится в beta-версии, и к release-версии все может измениться. Но пока
C# – явный аутсайдер. Хочется предостеречь читателей от попытки делать далеко
идущие выводи о GC как таковом и их реализациях в Java/.Net. Данный тест далек
от реальных условий и не учитывает некоторых тонкостей (типа различных
стратегий GС в Java).
Выводы по тесту
В этом тесте выиграл не самый быстрый компилятор, а средство
разработки, в котором серьезно подошли к переписыванию функций управления
памятью. Эти средством стала Delphi. Новые языки с их «сборщиками мусора» не
оправдали надежд. Отдельно хочется сказать о насильном навязывании ОО подхода.
Бывают места где он совершенно не нужен. Так, стандартные алгоритмы (каковыми
являются алгоритмы сортировки) мало пригодны для внедрения ОО идей. Главной
проблемой здесь является очень большая «стоимость» выделения памяти. К примеру,
тесты «Quick Sort» и этот тест используют алгоритмы с примерно одинаковыми
скоростными характеристиками, но ввиду того, что в «Tree Sort» происходит
создание объектов (с выделением для них памяти в хипе), скорость выполнения
этого теста на порядки меньше. Так исходный массив для этого теста имел размер
10 000 000, а для «Quick Sort» 100 000 000. При этом сам тест выполнялся
примерно вдвое медленней. И тут появляются претензии к Java. Дело в том, что у
Java отсутствуют сложные типы данных (вроде структур в C/C++) которые могли бы
размещаться в стеке и массивах. В Java все сложные типы всегда передаются по
ссылке. Т.е. если вы попытаетесь создать локальную переменную или массив
сложного типа (а в Java таковым могут быть только классы), то в стек/массив
будет заложен не сам объект, а только указатель на него. Сам же объект будет
создан в глобальном хипе, точнее в GC. Кстати, полностью этим процессом можно
управлять только в C++. Delphi позволяет делать структуры (в ней они называются
записями), но эти структуры не могут иметь методов (т.е. сравнимы со структурами
в C). Классы же в Delphi тоже всегда имеют ссылочный тип. Про VB 6 речь вообще
не идет, все его так называемые объекты на поверку являются COM-объектами. C#
является промежуточным вариантом между C++ и Delphi. В C# классы тоже имеют
ссылочный тип, но имеются структуры, которые размещаются в стеке и передаются по
значению, при этом они могут содержать методы и свойства. Пожалуй, без таких
ухищрений нельзя создать язык, позволяющий порождать действительно быстрый и
высокооптимизированный код, но зачем было так выпендриваться. Не лучше бы было
оставить все как в C++, а GC прикрутить только к динамически создаваемым
классам, избавив тем самым программистов от слежения за временем жизни объектов?
String-тест
Это тест, как следует из его названия, проверяет, насколько
тот или иной язык (среда/платформа) позволяет эффективно работать со строками.
Его суть проста как три копейки. Мы просто написали цикл, в котором
конкатенируются строки. Вот его код:
CString ss;
for(int i = 0; i < 10000000; i++)
{
ss = _T(">>>>>>>>>>>>>>>>>...>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>");
ss += _T("Мама ");
ss += _T("мыла ");
ss += _T("раму");
ss += '\n';
}
C++ не имеет встроенной поддержки работы со строками, но на
нем легко реализуются классы, позволяющие это делать. Мы выбрали для нашего
теста CString – MFC-реализацию такого класса. Почему? Да просто потому, что это
один из наиболее часто употребляемых классов, и к тому же неплохо реализованный.
C++-проект компилировался в ANSI-версии. Выполнение же производилось под
управлением W2k. Большинство программ (в целях совместимости) компилируются
именно в ANSI, и мы посчитали, что это будет справедливо.
Результаты
| |
PIII 800 |
AMD 1400 |
| в секундах |
| C# (.Net) |
7.18 |
3.38 |
| Intel C++ |
14.40 |
3.39 |
| Java |
7.55 |
3.48 |
| VC 6 |
15.40 |
6.08 |
| VB 6 |
22.30 |
10.20 |
| Delphi |
22.28 |
10.97 |
Выводы
В этом тесте победу одержал C#. Ему на пятки наступали Java и
Intel C++. Но Intel C++ продемонстрировал замечательный результат только на (гы-гы)
платформе AMD. На процессоре Intel он показал результат, близкий к VC.
Надо заметить, что для работы со строками в Java и C#
использовались не их встроенные строковые классы, а так называемые классы
stringbuilder-ы. Главное их отличие от обычных строковых классов заключается в
том, что при обработке строк память не перезанимается при каждой операции. При
этом работа осуществляется в буфере большего, чем необходимо размера. При этом
длина строки может быть равной или меньшей, чем размер (capacity) буфера. Такие
строковые классы позволяют резко поднять эффективность, главным образом за счет
сокращения перезаемов памяти. Класс CString тоже является string-builder-ом. В
VB и Delphi не принято использовать дополнительных строковых классов. Вместо
этого работа со строками вмонтирована в язык. Как показывает наш тест, тесная
интеграция с языком им не помогла. Они оба заняли последние места. Несколько
непонятно, почему отстал VC? По всей видимости, причина его проигрыша
заключается в том, что реализация оператора «+=» в MFC оформлена как отдельная
функция, и VC не считает нужным подставлять ее как inline. На эту мысль
наталкивает результаты Intel C++, который использовал тот же исходный код.
Float-Тест
Приложения клиент-сервер, да и большинство офисных
приложений, почти не используют числа с плавающей точкой, а если и используют,
то быстродействие такого кода не критично, но наш тест не был бы полным без
этого пункта.
После долгих, но безуспешных попыток найти подходящий
алгоритм (напомню, что нам нужен простой алгоритм, сильно загружающий процессор
на необходимое нам время и при этом по минимуму зависящий от других видов
вычислений), мы с отчаяния изобрели гениальный алгоритм, который сейчас
патентуется, чтобы продать Intel. :) Вот эта белиберда:
double f0 = 0;
double f1 = 123.456789;
double f2 = 98765.12345678998765432;
double f3 = 12345678943.98;
for(int i = 0; i < iInitVal; i++)
{
f0 = (f1 (double)i) - f2 + (f3 * (double)i);
}
m_spIUtility->TimerEnd(/*sbsInfo*/);
CString ss;
ss.Format("Result is %f", f0);
MessageBox(ss);
Введение в расчеты переменной цикла сбило большинство
компиляторов и позволило избежать приведения расчетов к константному вычислению.
Для того, чтобы компиляторы не вздумали вообще выкинуть наш цикл, iInitVal был
сделан параметром функции, а значение переменной f0 выводилось во всплывающем
окне. Не пытайтесь искать зачатки разума в этом анархизме. Это всего лишь первый
пришедший в голову бред.
Результаты
| |
PIII 800 |
AMD 1400 |
| в секундах |
| Intel C++ |
0.50 |
0.29 |
| C# (.Net) |
39.28 |
12.24 |
| Delphi |
39.35 |
12.24 |
| VC 6 |
39.08 |
12.26 |
| Java |
39.05 |
12.98 |
| VB 6 |
46.54 |
15.13 |
Выводы
Ну, что же? В этом тесте выиграл Intel C++, но назвать его
результат выигрышем язык не поворачивается. Он не выиграл, а просто «сделал»
всех, с оглушительным результатом. Т.е. он был единственным компилятором,
который действительно занимался оптимизацией кода, а не тупым переводом
конструкций C++ в ассемблерные команды. Ниже приведен листинг asm/source,
созданный VC 6:
; 522 : double f0 = 0;
; 523 : double f1 = 123.456789;
; 524 : double f2 = 98765.12345678998765432;
; 525 : double f3 = 12345678943.98;
; 526 : for(int i = 0; i < iInitVal; i++)
mov ecx, DWORD PTR _iInitVal$[ebp]
xor eax, eax
test ecx, ecx
mov DWORD PTR _f0$[esp+24], 0
mov DWORD PTR _f0$[esp+28], 0
mov DWORD PTR _i$[esp+24], eax
jle SHORT $L80063
$L80061:
; 527 : {
; 528 : f0 = (f1 / (double)i) - f2 + (f3 * (double)i);
fild DWORD PTR _i$[esp+24]
inc eax
cmp eax, ecx
mov DWORD PTR _i$[esp+24], eax
fstp QWORD PTR -8+[esp+24]
fld QWORD PTR __real@8@4005f6e9e03f70585800
fdiv QWORD PTR -8+[esp+24]
fsub QWORD PTR __real@8@400fc0e68fcd6e9db800
fld QWORD PTR -8+[esp+24]
fmul QWORD PTR __real@8@4020b7f70717feb85000
faddp ST(1), ST(0)
fstp QWORD PTR _f0$[esp+24]
jl SHORT $L80061
$L80063:
; 529 : }
А ниже приведен листинг, созданный нашим победителем:
; LOE ebp esi edi
$B14$2: ; Preds $B14$1
;;; double f0 = 0;
fld QWORD PTR $2$14_2il0floatpacket$3 ;522.9
;;; double f1 = 123.456789;
;;; double f2 = 98765.12345678998765432;
;;; double f3 = 12345678943.98;
;;; for(int i = 0; i < iInitVal; i++)
xor edx, edx ;526.10
test ebp, ebp ;526.2
fstp TBYTE PTR [esp+32] ;522.9
jg $B14$3 ; Prob 98% ;526.2
jmp $B14$10 ; Prob 100% ;526.2
; LOE edx ebp esi edi
$B14$3: ; Preds $B14$2
cmp ebp, 6 ;526.2
jl $B14$7 ; Prob 0% ;526.2
; LOE edx ebp esi edi
$B14$4: ; Preds $B14$3
lea eax, DWORD PTR [ebp-6] ;526.21
ALIGN 4
; LOE eax edx ebp esi edi
$B14$5: ; Preds $B14$4 $B14$5
add edx, 5 ;526.31
cmp edx, eax ;526.2
jle $B14$5 ; Prob 97% ;526.2
; LOE eax edx ebp esi edi
$B14$7: ; Preds $B14$5 $B14$3
fld QWORD PTR $2$14_2il0floatpacket$5 ;523.9
fld QWORD PTR $2$14_2il0floatpacket$7 ;524.9
;;; {
;;; f0 = (f1 / (double)i) - f2 + (f3 * (double)i);
fchs ;528.27
fst QWORD PTR [esp+24] ;528.27
fld QWORD PTR [esp+24] ;528.27
fld QWORD PTR $2$14_2il0floatpacket$9 ;525.9
ALIGN 4
; LOE edx ebp esi edi mm0 mm1 mm4 mm5
$B14$8: ; Preds $B14$7 $B14$8
fstp st(2) ;
mov DWORD PTR [esp+24], edx ;528.22
inc edx ;526.31
cmp edx, ebp ;526.2
fild DWORD PTR [esp+24] ;528.22
fstp QWORD PTR [esp+24] ;528.22
fld QWORD PTR [esp+24] ;528.22
fld st(0) ;528.22
fdivr st, st(4) ;528.22
fadd st, st(2) ;528.27
fxch st(1) ;528.46
fmul st, st(3) ;528.46
faddp st(1), st ;528.46
fstp QWORD PTR [esp+24] ;528.3
fld QWORD PTR [esp+24] ;528.3
fxch st(2) ;526.2
jl $B14$8 ; Prob 80% ;526.2
; LOE edx ebp esi edi mm0 mm1 mm4 mm5
$B14$9: ; Preds $B14$8
fstp st(3) ;
fstp st(0) ;
fstp st(1) ;
fstp TBYTE PTR [esp+32] ;
; LOE esi edi
$B14$10: ; Preds $B14$9 $B14$2
;;; }
Даже ничего не понимая в ассемблере и командах сопроцессора,
можно отметить, что Intel C++ проделал значительно большую работу. И результат
оправдал его мучения. Однако, на более осмысленном коде такого отрыва может не
оказаться. Как бы то ни было, Intel C++ победил в этом тесте и может быть
рекомендован для приложений, интенсивно использующих вычисления с плавающей
точкой, таких как 3D-приложения, игры, научные расчеты...
Резюме
Итак, практически все языки/компиляторы показали неплохую
производительность. Назвать абсолютного лидера тяжело. В абсолютном зачете
победу, скорее всего, одержал Intel C++, так как он почти всегда был около
лидера, а в тесте «Float Test» ушел в такой отрыв, что получил гигантскую фору.
Так же прекрасно выглядели VC 6, Delphi 6 и C#. VC был первым по количеству
тестов, в котором он оказался первым (извините за каламбур). Но только при
компиляции с включенной опцией inline-подстановки функций по выбору компилятора.
А что же наши неофиты? Да, в общем-то, неплохо. Java показала
себя не самым быстрым средством, но на двух тестах (расчете p и «String Test»)
она была на йоту от лидерства.
C# стал победителем в тесте работы со строками и (если
сравнивать результаты без inline-подстановок) в тестах «Доступ к членам» и
«Доступ к методам». Почти во всех остальных тестах он был в числе призеров или
показывал небольшое отставание от них. Единственный тест, где C# проиграл (и по
крупному) – это «Tree Sort», где он занял последнее место. Как уже говорилось
ранее, положение вещей может измениться к выходу финальной версии C# и VC.Net.
Надеемся что эти изменения не только будут, но и будут в хорошую сторону.
Можно с уверенностью сказать, что C#/VC.Net и Java – это
языки/среды, на которых можно создавать высокопроизводительные приложения.
Особенно это касается C#. Интересно, что p-код (из которого состоят выполняемые
файлы) обоих сред не только не является недостатком, но и наоборот является
преимуществом. Дело в том, что оптимизация производится в момент компиляции,
причем под конкретный процессор. Это значит, что все среды, создающие машинный
код, могут производить оптимизацию только под один известный им процессор (В VC
использовалась оптимизация под Pentium Pro, в Intel C++ под PIII, Delphi не
сообщила о своих планах по этому поводу). P-код ориентированные платформы (VC.Net
и Java) производят компиляцию в машинный код перед запуском или во время
исполнения программы (.Net-приложения могут быть прекомпилированы в момент
инсталяции или вручную с помощью утилиты ngen (что, собственно, мы и делали). Но
не следует забывать, что в .Net p-код никогда не выполняется в режиме
интерпретации, т.е. даже без применения ngen будет производится компиляция, но
при каждом запуске исполняемого модуля.). Естественно, в этот момент уже
известен процессор и другие характеристики системы, на которой должен будет
выполняться компилируемый код. Теоретически это должно давать p-код
ориентированным платформам фору, за счет использования более производительных
инструкций. Но как показывают наши тесты, пока это только теория. По всей
видимости дело в том, что большинство кода попросту не использует новые высоко
производительные команды процессоров, а во вторых они пока не избавились от
«детских болезней» присущих всем новым продуктам. Однако потенциал велик. C#
отчетливо доказал, что язык нового поколения способен создавать код не только
сравнимый по скорости с лучшими образцами старого мира, но и превосходящий их! А
так как Microsoft и Sun готовы вкладывать поистине невообразимые деньги в
развитие своих детищ, то у этих языков/платформ большое будущее. Так что,
похоже, появившиеся в СМИ заявления о том, что Microsoft планирует заморозить
развитие Win32 API, языка C++ и COM, и перевести всё и вся на новую технологию .Net,
являются правдой. Но как показало наше тестирование, для нас с вами это не
представляет угрозы.
Copyright © 1994-2016 ООО "К-Пресс"
