 |
Технология Клиент-Сервер 2001'3
|
|
|
Объять необъятное… или что умеет Sybase Replication Server ?
Сергей Ляпин, консультант Sybase CIS
Вместо введения
Говоря о практике построения сложных распределенных
информационных систем, мы, как правило, сталкиваемся с двумя ситуациями.
В одном случае: одна задача, один стратегический вендор и
много денег. Это проекты, о которых говорят, как об “успешных”. Однако за этим
успехом часто скрывается отказ от учета многих нюансов ведения бизнеса,
игнорируются предыдущие разработки и вложения, сопровождаясь при этом головной
болью по поводу судьбы проекта.
В другом: родной коллектив и разработки, грамотные идеи и ...
всем известные проблемы интеграции зоопарка технологий.
Современные требования к информационным бизнес-системам,
вызванные, с одной стороны, взрывообразным увеличением объемов и “стоимости”
информации, скоростью деловых транзакций, а с другой стороны необходимостью
“безболезненной” интеграции со вчерашними наработками, поставили принципиально
новые требования к технологиям репликации.
Учесть все их, казалось бы, невозможно. Однако то, что
предлагается в продукте Replication Server, имеющем достаточно долгую историю,
говорит об обратном.
Разработка первой версии Replication Server проводилась три
года при активном участии будущих пользователей. Продукт появился на свет в
ноябре 1993 года и стал законодателем мод в области архитектуры сложных
репликационных комплексов масштаба предприятия.
Таблица 1: Варианты механизмов репликации
| Механизм репликации |
Тип |
Проблемы |
| Распределенные транзакции (II-Phase Commit) |
Синхронная |
Сбои и загрузка сети |
| Создание и загрузка дампов |
Асинхронная |
Процесс долгий и ресурсоемкий |
| Снимки таблиц |
Асинхронная |
Возможная потеря целостности данных |
| Репликация на триггерах |
Асинхронная |
Потеря производительности, сложное администрирование |
Немного истории
Способность эффективно управлять корпоративными
информационными потоками является ключевым достоинством современного бизнеса.
Задавать вопрос "Зачем мне необходимо строить распределенную информационную
систему?" так же глупо, как “Зачем мне выходить в регионы и расширять филиальную
сеть?”. Сейчас чаще всего звучат вопросы о преимуществах и недостатках того или
иного подхода к построению структуры информационных потоков, об эффективности
механизмов репликации и интеграции корпоративных данных. А на них простого и
однозначного ответа, к сожалению, нет.
Еще совсем недавно в практике построения сложных
информационных комплексов использовался подход, основанный на централизованном
размещении всех данных и вычислительных ресурсов. Удаленные филиалы либо
работали без связи центральной базы, либо использовали прямое соединение с
центральным хостом. Такие соединения были достаточно медленными и ненадежными и
поэтому сильно ограничивали возможности и быстродействие удаленных клиентов
информационной системы.
Возросшая пропускная способность и “глобализация” сетей
позволили распределять и интегрировать вычислительные ресурсы и информацию не
только в масштабах предприятия, но даже более того, смежных или связанных
партнерскими отношениями предприятий. Таким образом, репликация как механизм
интеграции информационных источников и потребителей в единое информационное
пространство, стала ключевым элементом современной информационной
инфраструктуры.
Концепция репликации не является чем-то новым...
<...>
Кроме снимков, другим механизмом асинхронной репликации
являются триггеры, отвечающие за вызов специального кода в ответ на изменение
состояния таблицы или поля. Изначально триггеры были введены производителями
серверов БД для поддержки ссылочной целостности данных и реализации
бизнес-логики приложения, однако вскоре все убедились в возможности выполнения
ими репликации изменений исходной базы на удаленных серверах. Хотя репликация на
основе триггеров более гибка, чем посредством снимков, она имеет несколько
недостатков, которые не позволили этой технологии репликации стать
индустриальным стандартом:
<...>
Многие производители СУБД включили в свои продукты стандартные
механизмы репликации посредством триггеров, обеспечив при этом даже поддержку
транзакционности репликации изменений. Несмотря на это, ограничения по
производительности и сложность администрирования побороть не удалось, что не
могло не сказаться на популярности этой технологии.
После эксплуатации и анализа недостатков предыдущих
механизмов репликации стало ясно, что пользователям необходим специализированный
механизм репликации, который не ограничен лишь механизмом копирования и доставки
информации с одного места на другое. Он должен поддерживать механизмы
обеспечения целостности такой информации, гарантированности доставки,
безопасности, надежности и производительности, т.е. отвечать всем тем
требованиям, которые предъявляются сегодня к современным информационным
комплексам.
Начиная со своего появления в 1993 году и по сегодняшний
момент, Replication Server является одним из немногих продуктов на рынке,
который не только удовлетворяет всем перечисленным требованиям, но и обладает
другими, не менее важными возможностями.
Среди них:
-
использование как существующих локальных,
так и глобальных сетей, таких как Internet, в процессе выбора оптимального
пути доставки информации;
-
передача транзакций без какого-либо
влияния на работу баз данных – источников информации. При этом каждая сторона,
участвующая в репликации, ничем не ограничена при выборе способа обработки
информации;
-
поддержка многоплатформенных и
гетерогенных двунаправленных конфигураций репликационной системы.
-
централизованное администрирование;
<...>
Пример 1: Один исходный сайт – один или несколько сайтов назначения
(распространение данных)
В самом простом случае Replication Server занимается
распространением информации с одного центрального сайта одному или нескольким
сайтам назначения, где эта информация будет доступна только для чтения. Такой
механизм распределения должен поддерживать транзакции, чтобы сайты назначения
содержали целостные данные.
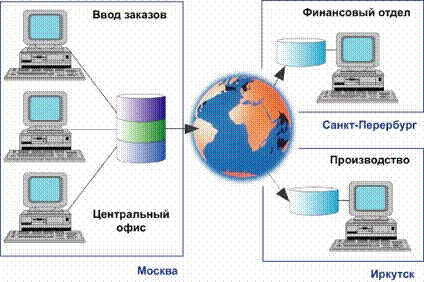
Рисунок 1.
Репликация аналитических данных
Рисунок 1 иллюстрирует подобную ситуацию: Компания использует
центральную OLTP-базу данных в Москве. В Москве отделом продаж в информационную
систему вводятся заказы и подготавливается аналитика по планируемым продажам для
подразделений: для финансового отдела, расположенного в Санкт-Петербурге, и для
производственных корпусов, расположенных в Иркутске.
Для удаленных подразделений неважно, на кого конкретно
оформлен заказ – необходим лишь его номер и заказанные позиции. Поэтому каждая
БД подразделений содержит свое собственное подмножество данных, необходимых для
полноценной работы.
При использовании Replication Server, каждое из подразделений
способно “подписаться” на аналитические данные, распостраняемые центральным
офисом и использовать эту информацию локально в том объеме, в котором это им
необходимо.
Таким образом, производственный комплекс в Иркутске сможет
оперативно формировать производственный план на основе плана продаж,
подготавливаемого в Москве. Бесперебойная работа производства будет обеспечена
даже в случае отсутствия надежного канала связи с центральным офисом. А все
изменения плана продаж будут непосредственно отражаться в текущем
производственном плане.
Подобная репликационная система, построенная на Replication
Server, легко масштабируется: увеличение количества подразделений практически не
влияет на производительность исходного сайта.
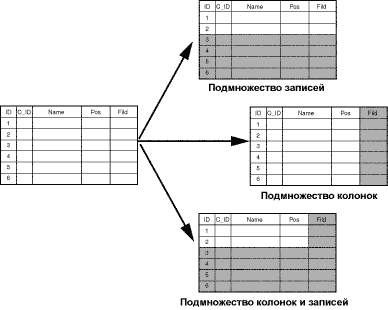
Пример 2: Несколько исходных сайтов - один сайт назначения (консолидация
данных)
Кроме механизма распределения информации из центрального
офиса, Replication Server обеспечивает простой механизм сбора корпоративной
информации со многих источников в центральный офис (консолидацию данных).
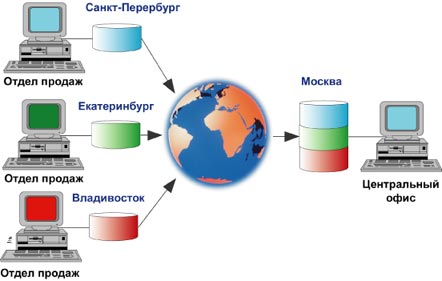
Рисунок 2. Консолидация данных корпорации
В качестве примера такой конфигурации можно рассмотреть
корпорацию с множеством филиалов. В каждом из филиалов есть собственная служба
продаж, которая занимается вводом заказов в локальные базы данных. Для подсчета
и анализа предполагаемого объема продаж в целом по корпорации необходимо собрать
эту информацию филиалов в единой базе данных центрального офиса. Рисунок 3
иллюстрирует такой случай: компания имеет центральный офис в Москве и филиалы в
Санкт-Петербурге, Екатеринбурге и Владивостоке. Центральному офису в Москве
необходимо знать объем продаж в целом по всем филиалам для разработки плана
производства. Replication Server обеспечивает быстрый и эффективный способ сбора
такой информации. Время задержки может ограничиваться несколькими секундами или
минутами. Кроме этого, структуры баз данных в филиалах и центре могут
различаться.
Эффективный механизм консолидации практически невозможно
реализовать с помощью создания и переноса дампов. Время задержки может
составлять несколько дней или месяцев. Также отсутствует механизм агрегирования
таких данных.
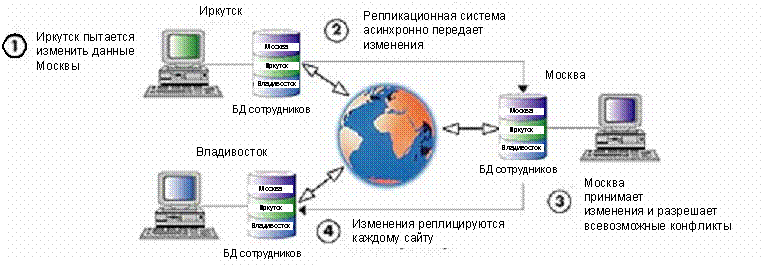
Пример 3: Равноправные сайты без возникновения конфликтов (распределение
данных)
Два предыдущих примера описывали случаи однонаправленной
репликации, когда информация поступает с одного исходного сайта на сайты
назначения (распределение) и с нескольких исходных сайтов на один центральный
сайт назначения (консолидация). Однако реальные ситуации оказываются намного
сложнее.
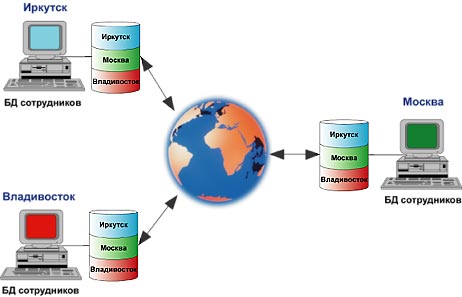
Рисунок 3.
Распределение корпоративных данных
Рассмотрим пример (Рисунок 3): Компания с несколькими
филиалами в России (Москва, Иркутск, Владивосток) хочет иметь объединенную базу
данных по всем сотрудникам. Такая база должна быть доступна в каждом филиале.
Каждый филиал полностью владеет своей частью данных, содержащей информацию о
сотрудниках этого филиала. Эти данные он создает и модифицирует. Кроме своих
данных, такая база содержит копии данных о сотрудниках каждого удаленного
филиала.
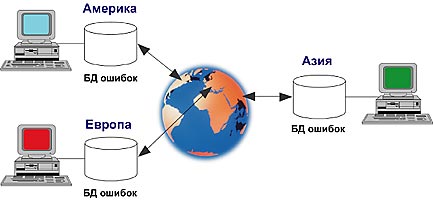
Рисунок 4. Интеграция корпоративных данных
Для реализации подобной схемы необходим механизм
синхронизации всех изменений по всем сайтам. Каждый сайт передает свои изменения
всем удаленным, которые, в свою очередь, передают свои изменения ему. Т.е.
необходима двунаправленная репликация. И Replication Server обеспечивает такой
механизм репликации без каких либо ограничений.
Подобная схема называется бесконфликтной, потому что все
изменения данных могут происходить только в той части БД, которой владеет сайт.
Локальные копии удаленных данных доступны только для чтения. Сайт Москвы может
изменять информацию о сотрудниках только московского офиса. Владивосток и
Иркутск изменяют только свои данные соответственно.
В результате все сайты получают объединенную базу данных
сотрудников всей компании практически в режиме реального времени.
Пример 4: Равноправные сайты с возможностью возникновения конфликтов
(интеграция данных)
Предыдущий пример подразумевал невозможность модификации
одних и тех же данных разными сайтами. Реализация подобной схемы является
достаточно простой и не требует специальных механизмов разрешения конфликтов.
Однако избежать конфликтов не всегда удается. Во многих ситуациях требуется
возможность модификации одних и тех же данных несколькими сайтами. Пример 5
показывает такой случай.
Транснациональная компания-разработчик ПО имеет специалистов
по технической поддержке своих продуктов в разных филиалах (в Европе, Азии и
Америке). Специалисты оказывают техническую поддержку клиентам в своем регионе.
Все они используют единую базу данных об ошибках, в которой собирается
информация по обращениям клиентов. Единая база данных необходима в частности для
обмена опытом специалистов. Таким образом, каждый специалист в своем регионе
может создать или обновить уже существующую информацию по обращению клиента. Так
как такие изменения одних и тех же данных, возможно, будут производиться
одновременно несколькими сайтами, то репликационная система должна обнаруживать
и разрешать такие ситуации.
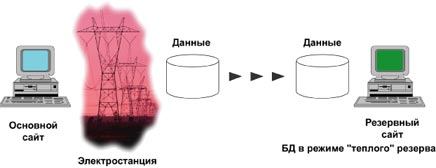
Рисунок 5. База
данных с "теплым" резервированием
Пример 5: Один исходный сайт - один сайт назначения (режим "теплого"
резервирования)
Другой полезной возможностью использования репликационной
системы является дешевый и эффективный способ поддержки резервных копий баз
данных на случай сбоя. Такой механизм резервирования называется "теплым", потому
что не обеспечивает прозрачного механизма переключения на резервный сервер в
случае сбоя и допускает потери транзакций в ходе такого сбоя. Однако такой
механизм является одним из самых дешевых способов резервирования на случай сбоя
или катастрофы.
На рисунке 5 приводится такой пример. Большая
электроэнергетическая компания имеет оперативную базу данных, расположенную
непосредственно на тепловой электростанции, которая контролирует выработку и
передачу электроэнергии конечным потребителям. Приложение, которое контролирует
передачу электроэнергии, является критическим ресурсом такой системы. Поэтому в
этом случае желательно использовать резервирование аппаратуры и программного
обеспечения: диски зеркалируются, сетевые каналы резервируются и т.п. Однако
такая система совсем не защищена против серьезных обстоятельств: катастроф,
пожара или наводнения. Система должна иметь резервный сервер, расположенный на
достаточном расстоянии от основного рабочего. Тогда в случае катастрофы на
электростанции, механизм передачи электроэнергии не будет затронут. Система
может оперативно переключить пути передачи электроэнергии и отключить нарушенные
участки.
В подобной ситуации необходимо принимать во внимание тот
факт, что информация в режиме теплого резервирования синхронизируется всегда с
некоторой задержкой, составляющей несколько секунд. Эта задержка зависит от
интенсивности и объема транзакций на рабочем сервере. Системные администраторы
должны принимать во внимание этот факт. Данную задержку можно всегда
использовать для переключения на резервный сайт, т.к. это тоже требует
некоторого времени.
Все проиллюстрированные репликационные конфигурации могут
быть построены с использованием Replication Server, который обеспечивает
надежный и эффективный механизм реализации подобных систем.
Как это работает?
Давайте разберемся, что входит в состав репликационной
системы, и каким образом работает Sybase Replication Server...
<...>
...Такая технология позволяет построить эффективную и надежную
гетерогенную репликационную систему в кратчайшие сроки, интегрируя все
разнородные источники данных вашей организации в единое информационное
пространство.
Захват транзакций
В репликационной системе, построенной на
базе Replication Server, все изменения исходных данных определяются и
захватываются специальным механизмом, называемым Log Transfer Manager (LTM),
который обычно располагается на том же сервере, где и исходная база данных. Для
Sybase Adaptive Server Enterprise 11-12 подобный менеджер является
непосредственной частью самого сервера. А для других типов серверов необходимо
запускать отдельные процессы – так называемые репликационные агенты. Отдельный
репликационный агент реализует механизм захвата и передачи транзакций для
конкретного сервера БД. Такие агенты существуют практически для любого
популярного сервера БД (Oracle, DB2, Informix, MS SQL Server и т.д.).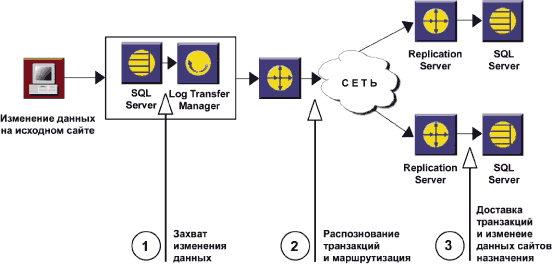
<...>
Модификация данных исходного сайта на сайте назначения
Рассмотрим самый “тяжелый” случай, когда пользователи вносят
изменения в данные на сайте назначения, принадлежащие другому сайту. Ранее на
примере консолидации корпоративной информации, мы показали, что такие случаи
бывают довольно часто. Пользователям требуется изменять одни и те же данные с
многих сайтов одновременно.
Рисунок
10.
Пример распределения изменений
с помощью асинхронной передачи
В системе, построенной на базе Sybase Replication Server
можно вносить изменения в данные исходного сайта двумя способами:
-
Асинхронно, передачей вызовов процедур
между сайтами.
-
Синхронно, через прямые соединения с
исходной базой данных.
Необходимо, чтобы в любое время каждая часть данных
информационной системы принадлежала определенному сайту, контролирующему эти
данные.
Давайте рассмотрим пример на рис. 4. Общая база данных по
сотрудникам компании имеет три копии в каждом регионе. Подразумевается, что
данные о работниках в Москве могут быть модифицированы только Москвой, данные
Иркутска - только Иркутском. Но это не всегда имеет место быть. Допустим,
головной отдел кадров в Москве имеет все права на модификацию данных обо всех
сотрудниках компании.
Тогда такую конфигурацию можно построить, используя
перечисленные выше способы. На рис. 10 приведен пример
распределения изменений с помощью асинхронного вызова удаленных процедур через
Replication Server. Для этого необходимо написать процедуру, которая будет
исполняться на сайте, владеющем своей частью данных. Такая процедура может сама
произвести необходимые изменения, разрешив возникающие конфликты. Но вызов этой
процедуры может происходить удаленно с другого сайта с помощью Replication
Server.
На рис. 11 приведен пример решения
подобной задачи с помощью прямого доступа к удаленному сайту минуя Replication
Server.
Таким образом соблюдается правило, что в любое время каждая
часть данных информационной системы принадлежит определенному сайту,
контролирующему эти данные.
Почему так важно, чтобы каждый сайт был монопольным
владельцем своей части данных? Если одни и те же данные могут быть
модифицированы несколькими сайтами одновременно, то кто же будет ответственен за
"истинное" состояние данных? Разрешать подобные ситуации, конечно же, можно, но
необходимо достаточно потрудиться для этого. Такая система очень сложна для
проектирования и эксплуатации.
Это же касается и проектирования маршрутов. Сравнивая
репликационные схемы на рис.12, можно сразу понять,
что поддержка в работоспособном состоянии правой схемы, когда каждый сайт связан
практически друг с другом, является очень сложной задачей. В ее решении может
помочь выбор некоторого приоритета, например, времени изменения информации. Но
какое время использовать в качестве времени изменения (местное, системное или
какое-либо другое) ?
Итак, во избежание ненужных затрат времени и ресурсов,
необходимо придерживаться правила монопольного владения сайтом своей части
данных.
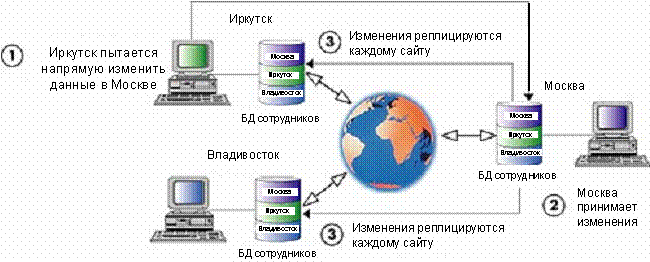
Рисунок 11. Пример распределения изменений с
прямым подключением
к исходному сайту
Высокая готовность данных
Высокая готовность данных подразумевает снижение риска и
уменьшение времени незапланированных простоев информационной системы в
результате сбоев. Продукты класса HA (High Availability) используются в случаях
когда цена таких простоев для бизнеса чрезвычайно высока или требуется
обеспечить непрерывную работу системы в режиме 24x7x365 (Интернет-порталы,
Банковские информационные системы)...
Для построения таких систем можно использовать Replication
Server в режиме Warm-Standby...
<...>
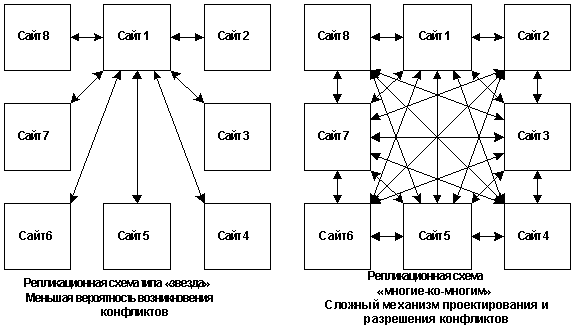
Рисунок 12.
Сравнительные модели репликации изменений
Эксплуатация Replication Server в режиме Warm-Standby
является простой задачей, поскольку все задачи синхронизации данных и
администрирования такой системы максимально автоматизированы.
Используя продукт OpenSwitch совместно с Replication Server в
режиме Warm-Standby, можно построить конфигурацию, при которой процесс сбоя и
переключения на резервный сервер никак не будет отражаться на коннектах
пользователей к системе. OpenSwitch обеспечит автоматическое прозрачное для
пользователей переключение таких коннектов на резервный сервер в случае сбоя.
Информация к размышлению
Современная версия Replication Server - 12.1 обеспечивает все
то, что необходимо современым бизнес-системам: эффективность, надежность и
безопасность управления информацией. Если удаленный сервер недоступен,
Replication Server сможет задействовать альтернативные пути доставки сообщений.
Если вся сеть недоступна, Replication Server будет хранить всю информацию до тех
пор, пока соединение не будет восстановлено. При этом ни одного байта информации
не будет потеряно. После восстановления соединений все транзакции попадут в
место назначения в том виде, и в том порядке, в котором они были инициированы.
Корпоративные серверы смогут функционировать абсолютно независимо друг от друга,
и использовать локальную копию своих данных, даже если связь между ними
отсутствует в настоящий момент.
Поэтому в качестве резюме можно выдвинуть предположение.
Может быть не все так плохо с практическим воплощением идеи об удобном и
эффективном механизме репликации? Думаю, многие пользователи Sybase Replication
Server согласятся с этим.
с автором можно связаться по E-mail: lvs@sybase.ru
Прочитать статью полностью вы можете в печатной версии журнала
Copyright © 1994-2016 ООО "К-Пресс"
