 |
Технология Клиент-Сервер 2003'2
|
|
|
Resource Description Framework – механизм описания ресурсов в Semantic Web
Петр Михеев
Введение
Благодаря принципам, положенным в основу World Wide Web, он развивается
фантастическими темпами. Побочным эффектом такого расширения являются все
возрастающие трудности, связанные с поиском необходимой информации. Последняя не
всегда упорядочена должным образом, причем это касается как самой информации,
так и ее расположения, которое постоянно меняется. Несмотря на наличие множества
всевозможных способов поиска информации, ее извлечения и доставки, отыскать
нужную информацию в Web с каждым днем становится все труднее и труднее.
Современные Web-технологии поиска основаны на полнотекстовом поиске. Все
поисковые запросы обслуживаются на основе индекса, содержащего некоторые
описания вхождений слов (термов) из известных данной поисковой системе
документов. Для сбора сведений о доступных документах, которые потом
используются для построения индекса, применяются так называемые сетевые роботы (crawlers)
– программы, которые, начиная с некоторой Web-страницы, рекурсивно обходят
ресурсы Internet, извлекая ссылки на новые ресурсы из получаемых документов. При
этом возникают различные проблемы – выбора того, что следует индексировать,
обеспечения равноправного индексирования всего информационного пространства, а
также решения, в контексте каких поисковых запросов следует выдавать ту или иную
информацию.
Более того, из-за размеров информационного Web-пространства индексы
получаются огромными, индексируется лишь часть Web-пространства, требуются
вычислительно трудоемкие методы работы с индексами, результаты поиска содержат
много несоответствующей интересам пользователя информации.
С другой стороны, если обрабатываемый документ является размеченным, то
индексируемые слова, отмеченные определенными тегами, значения атрибутов
специальных тегов и т.п., получают семантически значительно более богатое
содержание. В спецификации HTML [8], начиная с версии 2.0, появился элемент
разметки <META>, предназначенный для записи парных элементов
"название-значение", описывающих именованные свойства документов и указывающих
на некоторую информацию о документе в целом. Атрибут NAME этого элемента
определяет название некоторого свойства документа, а CONTENT – соответствующее
ему значение. Использование этого элемента не получило широкого распространения.
Одним из препятствий на пути организации индексации/каталогизации HTML-страниц
на основе элемента META стало некорректное использование этого элемента, когда
META-описания HTML-страницы использовались для привлечения к ней внимания, а не
для представления свойств документа. В результате многие из поисковых систем
отказались от использования META-описания. Другой существенной причиной было
отсутствие простого общепризнанного стандарта, фиксирующего существенные
“поисковые” свойства HTML-документов. Разные системы, сообщества предлагали и
использовали разные имена свойств. Многие из использовавшихся свойств
преследовали иные цели, нежели описание “поисковых” свойств документов. Только
сравнительно недавно были стандартизованы и нашли широкое употребление набор
“поисковых” свойств документов и правила их записи в элементе META и в XML
форме. Это Dublin Core Metadata Set (DC) [1] – международная и междисциплинарная
попытка определить набор элементов описания электронных информационных ресурсов
с целью упрощения их поиска и каталогизации.
Новые поколения поисковых машин научились проводить автоматический или ручной
анализ ссылок, связывающих страницы, а также преобразовывать ключевые слова и
сводную информацию в понятия. Но проблема поиска информации все-таки не была
решена. Так, например, по-прежнему возникают проблемы при интеграции и сравнении
информации, когда невозможно определить, что конкретно содержится в документе.
Специализированные системы, осуществляющие доступ к предметно-ориентированным
ресурсам, обычно содержат дополнительные семантические описания ресурсов и,
таким образом, обеспечивают значительно более высокое качество результатов,
получаемых пользователями, а также предоставляют результаты поиска в удобной для
чтения форме, тогда как результаты поиска в Web-системах представляются как
“сырые” данные. В отличие от многоцелевых, специализированные системы
предназначены для ответов на запросы, относящиеся к некоторой специализированной
области. Они производят поиск по значительно меньшему количеству ресурсов и
применяют более вычислительно-трудоемкие методы каталогизации и поиска.
Основные проблемы World Wide Web связаны, главным образом, с тем, что до сих
пор Web-технологии ориентировались исключительно на поддержку человеческой
деятельности по поиску и навигации в информационном пространстве Web-ресурсов.
"Всемирная паутина" следующего поколения, которую Тим Бернерс-Ли и его коллеги
называют Semantic Web, должна быть рассчитана на машинную обработку информации.
Создание осмысленной "семантической паутины" в соответствии с предложенной W3C
концепцией Semantic Web могло бы решить все перечисленные проблемы поиска и
обмена информацией.
В Semantic Web можно находить и объединять данные из самых различных
источников, а также использовать правила логического вывода для оценки ценности
и качества найденных источников, и онтологии – для преобразования результатов в
пригодную для анализа форму.
Формирование Semantic Web станет возможным только при условии обеспечения
более высокого уровня интероперабельности. Необходимы стандарты не только для
синтаксической формы документов, но и для их семантического наполнения. Самой
значительной среди предпринятых консорциумом W3C инициатив, связанных со
стандартизацией, стали XML и RDF.
Основные концепции Semantic Web
В основе Semantic Web лежат три ключевые технологии:
-
спецификация XML, позволяющая определить синтаксис и
структуру документов;
-
система онтологий, позволяющая определять термины и
отношения между ними;
-
механизм описания ресурсов (Resource Definition Framework,
RDF), обеспечивающий модель кодирования для значений, определенных в
онтологии.
Semantic Web использует также другие технологии и концепции, в частности,
универсальные идентификаторы ресурсов, цифровые подписи, системы логического
вывода и обычные протоколы Internet (см. рисунок 1).
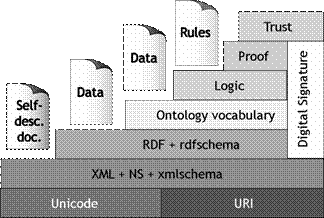
Рисунок 1. Архитектура
Semantic Web, разрабатываемая и продвигаемая W3C.
XML обеспечивает синтаксическую интероперабельность. Однако задачу
обеспечения семантической интероперабельности с помощью XML решить невозможно.
Основное ограничение XML состоит в том, что он лишь описывает грамматику.
Выделить семантическую единицу в конкретной предметной области попросту нельзя,
поскольку XML ориентирован на структуру документа и не предполагает общей
интерпретации данных, содержащихся в документе.
Одно из наиболее важных требований к формату обмена состоит в том, что данные
должны быть понятными. Если синтаксическая интероперабельность неразрывна с
синтаксическим разбором данных, то семантическая связана с установлением
соответствия между терминами, используемыми в данных, что требует анализа
содержимого.
Онтологии в состоянии сыграть критически важную роль в
организации и обработке знаний в Web, их совместном использовании и обмене
данными между приложениями. Онтология в общем виде определяется как система,
состоящая из набора понятий и набора утверждений об этих понятиях, на основе
которых можно строить классы, объекты, отношения и т.д. Онтология определяет
общее соглашение о семантике конкретной области и способствует установлению
корректных связей между значениями элементов области, тем самым, создавая
условия для их совместного использования.
Онтологии используются для поддержки автоматизированного обмена данными и для
интеграции приложений, механизмы поиска также применяют онтологии для выборки
страниц с синтаксически различными, но семантически одинаковыми словами.
Онтология, как правило, содержит иерархию концепций предметной области и
описывает важные свойства каждой концепции с помощью механизма «атрибут —
значение». Связи между концепциями могут быть описаны с помощью дополнительных
логических утверждений.
Создатели "семантической паутины" предлагают в среде RDF описывать онтологии
в формате XML.
Resource Description Framework
RDF [2] представляет собой методику, предложенную W3C в качестве стандартной
основы для определения и обработки метаданных (т.е. данных о данных)
Web-ресурсов. Существенное влияние на разработку этого формата оказали концепции
Dublin Core [1] и Warwick Framework [3]. Основной задачей при разработке RDF
была необходимость определения механизма описания ресурсов, который не делал бы
никаких предположений относительно специфики предметной области, но был бы
удобным для описания и обработки сведений о любой области. Согласно архитектуре
World Wide Web, которую разрабатывает и продвигает W3C, RDF представляет собой
“связующее звено” между XML-документами и высокоуровневыми средствами,
обеспечивающими поиск и навигацию на основе логических утверждений (рисунок 1).
В основе методики RDF лежит аппарат утверждений. Описание ресурса в RDF – это
совокупность утверждений о свойствах ресурса. Каждое утверждение представляет
собой именованное отношение между описываемым ресурсом и значением свойства.
Значение может быть как литеральным значением, так и другим ресурсом.
Именованное отношение представляет собой имя, сопоставленное свойству ресурсов.
Примечательной стороной RDF является то, что он позволяет делать утверждения не
только о ресурсах, но и о самих утверждениях.
Можно говорить, что ресурс описывается с помощью той или иной совокупности
терминов (понятий) – словаря терминов. Семантика, смысл самих терминов и
словарей терминов, фиксируется с помощью некоторых глобальных универсальных имен
– URI (Uniform Resource Identifier) [5]. Словарь терминов, называемый RDF-схемой
[4], определяет, какие термины могут быть использованы в RDF-утверждениях о
свойствах ресурсов, представляет иерархию понятий (терминов) предметной области,
описывает важные характеристики каждого понятия.
RDF является XML-приложением, разработку которого продолжает вести консорциум
W3. Сейчас в RDF для записи метаданных применяется синтаксис XML. Но это не
означает, что RDF-описания и впредь будут записываться только в XML-форме.
Разработчики ориентируются на использование разных форм записи RDF-моделей. В
настоящее время имеются предложения альтернативных форм записи RDF, например, в
виде наборов троек. В статье мы будем использовать синтаксис XML.
Первое RDF-описание
Как уже было сказано, в основе методики RDF лежит аппарат утверждений.
Описание ресурса в RDF – это совокупность утверждений о свойствах ресурса.
Ресурсами могут быть целые Web-страницы, части Web-страниц и даже целый сайт.
Ресурсом может быть что-то совершенно не связанное с Web, например, книга...
Прочитать статью полностью вы можете в печатной версии журнала
Copyright © 1994-2016 ООО "К-Пресс"
