 |
Технология Клиент-Сервер 2004'4
|
|
|
Создание быстрого управляемого кода: что сколько стоит?
Введение
Есть множество способов выполнения вычислений, и некоторые из них куда лучше прочих: проще, чище и удобнее в поддержке. Некоторые ошеломляюще быстры, а некоторые – поразительно медленны.
Не выпускайте в мир медленный громоздкий код. Разве вы сами его не презираете? Код, который останавливает UI на целые секунды? Код, который вешает процессор или засоряет диск?
Не делайте так. Лучше встаньте и повторяйте за мной:
"Я обещаю не выпускать медленный код. Скорость – моя первая забота. Каждый день я буду забоиться о производительности моего кода. Я буду регулярно и методично измерять его скорость и размер. Я буду изучать, создавать и покупать инструменты, нужные для этого. Я за это отвечаю."
(Серьезно) Так вы обещаете? Тем лучше для вас.
Так как же писать наиболее быстрый код изо дня в день? Это вопрос сознательного выбора скромности вместо экстравагантности, делающегося снова и снова, а также мышления, соответствующего обстоятельствам. Любая страница кода состоит из дюжин таких маленьких решений.
Но осуществить правильный выбор из нескольких вариантов не получится, если вы не знаете, что сколько стоит: вы не сможете писать эффективный код, не зная, что сколько стоит.
В старые добрые времена было лучше. Хорошие С-программисты знают. Каждый оператор и операция в С, будь то присваивание, целочисленные вычисления или вычисления с плавающей точкой, разыменование или вызов функции отображается более или менее один к одному на одну примитивную машинную операцию. Действительно, иногда нужно несколько машинных операций, чтобы поместить нужные операнды в нужные регистры, а иногда одна инструкция может вмещать несколько операций С (*dest++ = *src++;), но обычно можно было написать (или прочитать) строку кода на С и знать, где тратится время. И для кода, и для данных компилятор С соответствовал WYWIWYG — "what you write is what you get" (Исключением были и остаются вызовы функций. Если вы не знаете, сколько стоит функция, вы не знаете ничего).
В 90-х, чтобы воспользоваться многими преимуществами абстрактности данных, ООП и повторного использования кода, индустрия создания ПО для РС перешла с С на C++.
C++ – это расширение С, причем новые возможности ничего не стоят, если вы их не используете – так что опыт С-программирования, включая модель стоимости, вполне применим. Если взять работающий код на С и перекомпилировать для C++, время исполнения и занимаемое место не слишком изменятся.
С другой стороны, в C++ появилось немало новых возможностей, имеющих нетривиальную скрытую стоимость – конструкторы, деструкторы, new, delete, одиночное, множественное и виртуальное наследование, приведения, функции-члены, виртуальные функции, перегруженные операторы, указатели на члены, массивы объектов, обработку исключений и их сочетаний. Например, виртуальные функции стоят двух лишних косвенностей на вызов, и добавляют к каждому экземпляру скрытое поле указателя vtable. Например, этот невинно выглядящий код:
{ complex a, b, c, d; ... a = b + c * d; }
|
компилируется примерно в 13 неявных вызовов функций-членов (надеюсь, inlined).
Девять лет назад в статье “C++: Under the Hood” (http://msdn.microsoft.com/archive/default.asp?url=/archive/en-us/dnarvc/html/jangrayhood.asp) я писал:
"Важно понимать, как реализуется язык программирования. Такое знание рассеивает страх и снимает вопросы типа "Что, черт возьми, сейчас делает компилятор?"; придает уверенности при использовании новых возможностей; дает понимание при отладке и изучении других возможностей языка. Оно также дает ощущение относительной стоимости различных подходов при кодировании, необходимое для создания наиболее эффективного кода изо дня в день".
Теперь нужно выработать такой же взгляд на управляемый код. Эта статья исследует время и пространство, затрачиваемое на исполнение управляемого кода, на низком уровне, что позволит принимать более разумные решения в повседневной работе.
И выполнять свои обещания.
Почему управляемый код?
Для подавляющего большинства разработчиков native-кода, управляемый код – это лучшая и более продуктивная платформа для исполнения их ПО. Он устраняет целые категории ошибок – такие, как повреждение кучи или выход индекса за границы массива, что так часто приводит к удручающим ночным бдениям с отладчиком. Он отвечает таким современным требованиям, как CAS (Code Access Security) и XML Web-сервисы, а в сравнении с древними Win32/COM/ATL/MFC/VB, .NET Framework – это свежее решение, позволяющее делать больше меньшими силами.
В чем секрет создания более быстрого управляемого кода?
То, что можно сделать больше меньшими силами, не значит, что можно бросить думать при кодировании. Во-первых, нужно сказать себе: "Я новичок". Вы – новичок. Я – тоже новичок. Мы все – дети в стране управляемого кода. Мы все пока учимся ориентироваться – в том числе и в стоимости.
В том, что касается .NET Framework, мы похожи на детей в кондитерской. "Вау, мне не нужна больше вся эта тоска с strncpy, можно просто складывать строки с помощью '+'! Вау, я могу загрузить мегабайт XML за несколько строк кода!"
Это все очень просто. Очень просто, правда. Так легко тратить мегабайты RAM на разбор XML просто чтобы вытащить из него несколько элементов. В C или C++ это было так болезненно, что вы бы дважды подумали, и, может быть, создали конечный автомат на некотором API вроде SAX. А в .NET Framework вы просто загрузите весь XML разом. И может быть, не один раз. После этого, возможно, ваше приложение уже не покажется быстрым. Возможно, ему придется ворочать всеми этими мегабайтами. Возможно, стоило дважды подумать, во что обойдутся эти простые методы...
С моей точки зрения, имеющаяся документация по .NET Framework, увы, неадекватно детализирует влияние на производительность типов и методов .NET Framework – она даже не указывает, какие методы могут создавать новые объекты. Моделирование производительности – непростая задача, но без этого все равно не обойтись.
Поскольку мы все новички, не знающие, что почем, и поскольку стоимость нечетко документирована, что же нам делать?
Измерять. Секрет в том, чтобы измерять, причем неустанно. Нам всем придется приобрести привычку мерить, что сколько стоит. Если мы будем мерить, что сколько стоит, мы не вызовем по неосторожности классный новый метод, стоящий вдесятеро дороже, чем мы предполагали.
(Кстати, чтобы забраться поглубже в основы BCL (base class library) или самого CLR, попробуйте посмотреть на Shared Source CLI, он же Rotor. Код Rotor – близкий родственник .NET Framework и CLR. Их код не совсем одинаков, но даже несмотря на это, вдумчивое изучение Rotor даст вам новое понимание происходящего под покровом CLR. Однако сперва прочтите лицензию SSCLI!)
Знание
Если вы стремитесь быть водителем такси в Лондоне, вы должны знать город. Таксисты учатся несколько месяцев, запоминая тысячи маленьких лондонских улочек и лучшие маршруты от одного места к другому. Причем они ежедневно выезжают на скутерах, чтобы осмотреться и обновить полученные из книг знания.
Подобно им, если вы хотите быть разработчиком высокопроизводительного управляемого кода, вам необходимо приобрести знание управляемого кода. Вам придется выучить, чего стоит каждая низкоуровневая операция. Вам придется узнать, сколько стоят такие возможности, как делегаты и и безопасность доступа к коду. Вы должны будете выяснить стоимость типов и методов, используемых или создаваемых вами. В результате вы сможете узнать, какие методы могут оказаться чрезмерно дорогими для вашего приложения – и избегать их.
Это знание, увы, нельзя получить из книг. Придется обзавестись собственным скутером и исследовать – то есть запустить csc, ildasm, отладчик VS.NET, CLR Profiler, ваш профилировщик, несколько счетчиков производительности, и посмотреть, сколько стоит ваш код в смысле времени и занимаемого места.
Стоимость управляемого кода
Покончив с вступлением, займемся моделью стоимости управляемого кода. Она позволит посмотреть на метод и сказать, какие выражения в нем самые дорогие.
(Это не относится к транзитивной стоимости вызова ваших методов или методов .NET Framework. Этой теме придется подождать до следующей статьи.)
Выше я говорил, что большая часть модели стоимости С пригодна и для C++. Аналогично, большая часть модели стоимости С/C++ пригодна и для управляемого кода.
Как это может быть? Вы знаете модель CLR. Вы пишете код на одном из нескольких языков. Вы компилируете его в формат, упакованный в сборки. Вы запускаете главную сборку приложения, и она начинает исполнять CIL (Common Intermediate Language). Но не медленнее ли это на порядок, подобно старым интерпретаторам байт-кода?
JIT-компилятор
Нет. CLR использует JIT-компилятор для компиляции MSIL-кода методов в native-код, и затем исполняет этот код. Конечно, есть некоторая задержка на JIT-компиляцию каждого метода при первом вызове, но каждый вызванный метод исполняется в виде native-кода, без издержек на интерпретацию.
В отличие от традиционного offline-процесса компиляции C++, время, затрачиваемое JIT-компилятором – это время пользователя, так что JIT-компилятор не может позволить себе такой роскоши, как полная оптимизация. Но даже при этом список видов оптимизации, выполняемых JIT-компилятором, впечатляет:
- Свертывание констант (constant folding, замена константного выражения результатом этого выражения – прим.ред.).
- Статическое продвижение констант и копий (constant and copy propagation) (заключается в продвижении константных выражений как можно дальше по тексту функции. Если выражение использует только значения переменных, которые в данной точке программы заведомо содержат одно известное при анализе программы значение, такое выражение может быть вычислено на этапе анализа программы. Если в выражении используется переменная, которая в данной точке программы заведомо является копией какой-то другой переменной, в выражение может быть подставлена исходная переменная. – прим. ред.)
- Исключение повторяющихся подвыражений.
- Вынесение инварианта цикла за его пределы.
- Распределение регистров.
- Inlining методов (встраивание тел методов в точку их вызова).
- Разворачивание циклов (для малых циклов с небольшими телами).
Результат сравним с традиционным native-кодом – по крайней мере, лежит в том же диапазоне.
The result is comparable to traditional native code—at least in the same ballpark.
Что же касается данных, то вы будете использовать смесь ссылочных типов и value-типов. Value-типы, включая целые числа, числа с плавающей точкой, перечисления и структуры, как правило, живут в стеке. Они практически так же малы, как структуры и локальные переменные в C/C++. Как и в случае C/C++, вы, скорее всего, будете избегать передачи больших структур как аргументов методов или возвращаемых значений, поскольку издержки при копировании будут непомерно высоки.
Ссылочные типы и value-типы, подвергшиеся boxig-у, живут в куче. Они доступны по объектным ссылкам, которые являются простыми машинными указателями наподобие объектным указателей в C/C++.
Таким образом, после JIT машинный код может быть быстрым. За несколькими исключениями, которые будут рассмотрены ниже, если у вас есть инстинктивное ощущение насчет стоимости некоторых выражений в native-коде на С, вы не слишком ошибетесь, моделируя стоимость их эквивалентов в управляемом коде.
Стоит также упомянуть NGEN, инструмент, позволяющий заранее скомпилировать CIL в сборки native-кода. Хотя применение NGEN к сборкам и не оказывает существенного влияния (хорошего или плохого) на время исполнения, оно может снизить объем физической памяти (working set), используемой процессом для разделяемых сборок, загружаемых во многих AppDomain-ах и процессах. (ОС может использовать одну копию обработанного NGEN кода на всех клиентах; тогда как код после JIT обычно не разделяется между доменами приложений и процессами. См. также LoaderOptimizationAttribute.MultiDomain.)
Автоматическое управление памятью
Наиболее существенное отличие управляемого кода от native-кода – автоматическое управление памятью. Вы размещаете новые объекты, но сборщик мусора (garbage collector, GC) автоматически удаляет их, когда они становятся недоступными. GC запускается снова и снова, часто незаметно, в общем случае останавливая ваше приложение всего на миллисекунду-другую – изредка дольше.
Есть несколько других статей, обсуждающих влияние GC на производительность, поэтому я не буду останавливаться на этом здесь. Если ваше приложение следует рекомендациям, изложенным в этих статьях, общая стоимость сборки мусора будет несущественной, несколько процентов от времени исполнения, что сравнимо с традиционными C++-объектами new и delete. Сравнительная стоимость создания и последующего автоматического удаления достаточно низка, так что вы можете создавать десятки миллионов маленьких объектов в секунду.
Но размещение объектов не стало бесплатным. Объекты занимают место. Безудержное размещение объектов ведет к учащению циклов сборки мусора.
Хуже того, ненужное сохранение ссылок на бесполезные графы объектов сохраняет их в живых. Иногда мы видим скромные программы с печальными 100+ MB используемой физической памяти, чьи авторы отрицают свою вину, и вместо этого приписывают плохую производительность некой мистической, неидентифицированной (и, следовательно, неизлечимой) проблеме в самом управляемом коде. Это трагично. Но в результате часа возни с CLR Profiler и изменения нескольких строк кода использование кучи сокращается раз в десять, а то и больше. Если у вас возникла проблема с большим количеством физически используемой памяти, первый шаг – посмотреть в зеркало.
Так что не создавайте объектов без надобности. Просто потому, что автоматическое управление памятью устраняет многие сложности, проблемы и баги в размещении и освобождении объектов, поскольку работает быстро и удобно в использовании, мы начинаем использовать больше и больше объектов – как будто они растут на деревьях. Если вы хотите писать действительно быстрый управляемый код, создавайте объекты обдуманно и к месту.
Это применимо и к дизайну API. Можно так разработать дизайн типа и его методов, что они потребуют от клиентов со страшной силой создавать новые объекты. Не делайте так.
Что почем в управляемом коде
Теперь давайте рассмотрим время, затрачиваемое на различные низкоуровневые операции в управляемом коде.
В таблице 1 представлена примерная стоимость различных низкоуровневых операций в наносекундах при исполнении на 1.1 GHz Pentium-III PC под Windows XP и .NET Framework v1.1, собранная с помощью набора простых тестовых циклов.
Тест вызывает каждый тестовый метод, указывает количество производимых итераций, автоматически масштабируясь от 218 до 230 итераций, что необходимо, чтобы выполнять каждый тест по меньшей мере 50 ms. Короче говоря, достаточно долго, чтобы отследить несколько циклов сборки мусора поколения 0 в тесте, усердно размещающем объекты. Таблица содержит усредненные результаты для 10 запусков, а также лучшее (минимальное) время для каждого теста.
Каждый тестовый цикл разворачивается от 4 до 64 раз, что нужно для уменьшения влияния издержек цикла. Я исследовал native-код, генерируемый для каждого теста, чтобы убедиться, что JIT-компилятор не оптимизировал тест насмерть - например, в нескольких случаях я изменял тест, чтобы сохранить промежуточные результаты во время и после тестового цикла. Сходным образом пришлось изменять код нескольких тестов, чтобы предотвратить устранение общих подвыражений.
| Avg |
Min |
Primitive |
| 0.0 |
0.0 |
Control |
| 1.0 |
1.0 |
Int add |
| 1.0 |
1.0 |
Int sub |
| 2.7 |
2.7 |
Int mul |
| 35.9 |
35.7 |
Int div |
| 2.1 |
2.1 |
Int shift |
| 2.1 |
2.1 |
long add |
| 2.1 |
2.1 |
long sub |
| 34.2 |
34.1 |
long mul |
| 50.1 |
50.0 |
long div |
| 5.1 |
5.1 |
long shift |
| 1.3 |
1.3 |
float add |
| 1.4 |
1.4 |
float sub |
| 2.0 |
2.0 |
float mul |
| 27.7 |
27.6 |
float div |
| 1.5 |
1.5 |
double add |
| 1.5 |
1.5 |
double sub |
| 2.1 |
2.0 |
double mul |
| 27.7 |
27.6 |
double div |
| 0.2 |
0.2 |
inlined static call |
| 6.1 |
6.1 |
static call |
| 1.1 |
1.0 |
inlined instance call |
| 6.8 |
6.8 |
instance call |
| 0.2 |
0.2 |
inlined this inst call |
| 6.2 |
6.2 |
this instance call |
| 5.4 |
5.4 |
virtual call |
| 5.4 |
5.4 |
this virtual call |
| 6.6 |
6.5 |
interface call |
| 1.1 |
1.0 |
inst itf instance call |
| 0.2 |
0.2 |
this itf instance call |
| 5.4 |
5.4 |
inst itf virtual call |
| 5.4 |
5.4 |
this itf virtual call |
| 2.6 |
2.6 |
new valtype L1 |
| 4.6 |
4.6 |
new valtype L2 |
| 6.4 |
6.4 |
new valtype L3 |
| 8.0 |
8.0 |
new valtype L4 |
| 23.0 |
22.9 |
new valtype L5 |
| 22.0 |
20.3 |
new reftype L1 |
| 26.1 |
23.9 |
new reftype L2 |
| 30.2 |
27.5 |
new reftype L3 |
| 34.1 |
30.8 |
new reftype L4 |
| 39.1 |
34.4 |
new reftype L5 |
| 22.3 |
20.3 |
new reftype empty ctor L1 |
| 26.5 |
23.9 |
new reftype empty ctor L2 |
| 38.1 |
34.7 |
new reftype empty ctor L3 |
| 34.7 |
30.7 |
new reftype empty ctor L4 |
| 38.5 |
34.3 |
new reftype empty ctor L5 |
| 22.9 |
20.7 |
new reftype ctor L1 |
| 27.8 |
25.4 |
new reftype ctor L2 |
| 32.7 |
29.9 |
new reftype ctor L3 |
| 37.7 |
34.1 |
new reftype ctor L4 |
| 43.2 |
39.1 |
new reftype ctor L5 |
| 28.6 |
26.7 |
new reftype ctor no-inl L1 |
| 38.9 |
36.5 |
new reftype ctor no-inl L2 |
| 50.6 |
47.7 |
new reftype ctor no-inl L3 |
| 61.8 |
58.2 |
new reftype ctor no-inl L4 |
| 72.6 |
68.5 |
new reftype ctor no-inl L5 |
| 0.4 |
0.4 |
cast up 1 |
| 0.3 |
0.3 |
cast down 0 |
| 8.9 |
8.8 |
cast down 1 |
| 9.8 |
9.7 |
cast (up 2) down 1 |
| 8.9 |
8.8 |
cast down 2 |
| 8.7 |
8.6 |
cast down 3 |
| 0.8 |
0.8 |
isinst up 1 |
| 0.8 |
0.8 |
isinst down 0 |
| 6.3 |
6.3 |
isinst down 1 |
| 10.7 |
10.6 |
isinst (up 2) down 1 |
| 6.4 |
6.4 |
isinst down 2 |
| 6.1 |
6.1 |
isinst down 3 |
| 1.0 |
1.0 |
get field |
| 1.2 |
1.2 |
get prop |
| 1.2 |
1.2 |
set field |
| 1.2 |
1.2 |
set prop |
| 0.9 |
0.9 |
get this field |
| 0.9 |
0.9 |
get this prop |
| 1.2 |
1.2 |
set this field |
| 1.2 |
1.2 |
set this prop |
| 6.4 |
6.3 |
get virtual prop |
| 6.4 |
6.3 |
set virtual prop |
| 6.4 |
6.4 |
write barrier |
| 1.9 |
1.9 |
load int array elem |
| 1.9 |
1.9 |
store int array elem |
| 2.5 |
2.5 |
load obj array elem |
| 16.0 |
16.0 |
store obj array elem |
| 29.0 |
21.6 |
box int |
| 3.0 |
3.0 |
unbox int |
| 41.1 |
40.9 |
delegate invoke |
| 2.7 |
2.7 |
sum array 1000 |
| 2.8 |
2.8 |
sum array 10000 |
| 2.9 |
2.8 |
sum array 100000 |
| 5.6 |
5.6 |
sum array 1000000 |
| 3.5 |
3.5 |
sum list 1000 |
| 6.1 |
6.1 |
sum list 10000 |
| 22.0 |
22.0 |
sum list 100000 |
| 21.5 |
21.4 |
sum list 1000000 |
Предупреждение: пожалуйста, не воспринимайте эти данные слишком буквально. В тестировании полно опасностей непредсказуемого второго порядка. Случайные происшествия могут поместить код после JIT, или некоторые критические данные, так, что они займут строки кэша, пересекутся с чем-нибудь еще и т.д. Это слегка напоминает Принцип Неопределенности: различия во времени порядка 1 наносекунды или около того близки к пределам разрешения.
Еще одно предупреждение: эти данные относятся только к короткому коду и сценариям, полностью умещающимся в кэше. Если "горячие" части вашего приложения не умещаются в кэше процессора, перед вами может встать другой набор проблем производительности. У нас еще будет время поговорить о кэше в конце статьи.
И еще одно предупреждение: одно из главнейших преимуществ поставки компонентов и приложений в виде CIL заключается в том, что ваша программа может автоматически становится быстрее каждую секунду и каждый год – "каждую секунду" потому, что runtime может (теоретически) перенастраивать JIT-компилированный код по мере исполнения программы; а "каждый год" потому, что каждая новая версия runtime-а может использовать лучшие, более умные и быстрые алгоритмы. Так что если некоторые из этих показателей кажутся вам совсем не оптимальными в .NET 1.1, мужайтесь – они улучшатся в следующих версиях. Из этого следует, что любой native-код, приведенный в этой статье, может измениться в следующих версиях .NET Framework.
С предупреждениями покончено, данные дают приемлемое понимание текущей производительности различных примитивов. Числа осмысленны, и подтверждают мое предположение, что большая часть JIT-компилированного управляемого кода исполняется так же "близко к машине", как и компилированный native-код. Примитивные операции с целыми числами и числами с плавающей точкой выполняются быстро, различные вызовы методов – медленнее, но (поверьте мне) все же сравнимо с родным C/C++-кодом; но все же можно заметить, что некоторые операции, обычно дешевые в native-коде (приведение типов, помещение значений в ячейки массивов и поля, работа с делегатами (аналогом которых в native-коде являются указатели на функции)), подорожали. Почему? Посмотрим...
Арифметические операции
| Avg |
Min |
Примитив |
Avg |
Min |
Примитив |
| 1.0 |
1.0 |
int add |
1.3 |
1.3 |
float add |
| 1.0 |
1.0 |
int sub |
1.4 |
1.4 |
float sub |
| 2.7 |
2.7 |
int mul |
2.0 |
2.0 |
float mul |
| 35.9 |
35.7 |
int div |
27.7 |
27.6 |
float div |
| 2.1 |
2.1 |
int shift |
|
|
|
| 2.1 |
2.1 |
long add |
1.5 |
1.5 |
double add |
| 2.1 |
2.1 |
long sub |
1.5 |
1.5 |
double sub |
| 34.2 |
34.1 |
long mul |
2.1 |
2.0 |
double mul |
| 50.1 |
50.0 |
long div |
27.7 |
27.6 |
double div |
| 5.1 |
5.1 |
long shift |
|
|
|
В прежние времена операции с плавающей точкой были, наверное, на порядок медленнее операций с целыми. Как показано в таблице 2, при использовании современных средств разницы почти нет. Забавно думать, что средний ноутбук сейчас – машина гигафлопного класса (для проблем, умещающихся в кэше).
Посмотрим на строку JIT-компилированного кода из целочисленного теста и теста вычислений с плавающей точкой:
Ассемблерный листинг 1. Int add и float add.
int add a = a + b + c + d + e + f + g + h + i
0000004c 8B 54 24 10 mov edx,dword ptr [esp+10h]
00000050 03 54 24 14 add edx,dword ptr [esp+14h]
00000054 03 54 24 18 add edx,dword ptr [esp+18h]
00000058 03 54 24 1C add edx,dword ptr [esp+1Ch]
0000005c 03 54 24 20 add edx,dword ptr [esp+20h]
00000060 03 D5 add edx,ebp
00000062 03 D6 add edx,esi
00000064 03 D3 add edx,ebx
00000066 03 D7 add edx,edi
00000068 89 54 24 10 mov dword ptr [esp+10h],edx
float add i += a + b + c + d + e + f + g + h
00000016 D9 05 38 61 3E 00 fld dword ptr ds:[003E6138h]
0000001c D8 05 3C 61 3E 00 fadd dword ptr ds:[003E613Ch]
00000022 D8 05 40 61 3E 00 fadd dword ptr ds:[003E6140h]
00000028 D8 05 44 61 3E 00 fadd dword ptr ds:[003E6144h]
0000002e D8 05 48 61 3E 00 fadd dword ptr ds:[003E6148h]
00000034 D8 05 4C 61 3E 00 fadd dword ptr ds:[003E614Ch]
0000003a D8 05 50 61 3E 00 fadd dword ptr ds:[003E6150h]
00000040 D8 05 54 61 3E 00 fadd dword ptr ds:[003E6154h]
00000046 D8 05 58 61 3E 00 fadd dword ptr ds:[003E6158h]
0000004c D9 1D 58 61 3E 00 fstp dword ptr ds:[003E6158h]
|
Видно, что JIT-компилированный код близок к оптимальному. В случае int add компилятор даже поместил в регистры (enregistered) пять локальных переменных. При сложении чисел с плавающей точкой мне пришлось сделать переменные (от а до h) статическими полями класса, чтобы побороть удаление общих подвыражений.
Вызовы методов
В этом разделе мы рассмотрим стоимость и реализацию вызовов методов. Предмет теста – класс Т, реализующий интерфейс I с методами разного сорта. См. листинг 1.
Листинг 1. Method call test methods
interface I
{
void itf1();
...
void itf5();
...
}
public class T : I
{
static bool falsePred = false;
static void dummy(int a, int b, int c, ..., int p) { }
static void inl_s1() { }
...
static void s1()
{
if (falsePred)
dummy(1, 2, 3, ..., 16);
}
...
void inl_i1() { }
...
void i1()
{
if (falsePred)
dummy(1, 2, 3, ..., 16);
}
...
public virtual void v1() { }
...
void itf1() { }
...
virtual void itf5() { }
...
}
|
Посмотрите на таблицу 3. Похоже, в первом приближении, методы либо подставляются по месту (inlined, при этом абстракция ничего не стоит), либо не подставляются (при этом стоимость абстракции более чем в пять раз больше чем целочисленная операция). Не похоже, чтобы была существенная разница в стоимости статического вызова, экземплярного вызова, виртуального вызова и вызова метода интерфейса.
| Avg |
Min |
Примитив |
Вызываемый метод |
| 0.2 |
0.2 |
inlined static call |
inl_s1 |
| 6.1 |
6.1 |
static call |
s1 |
| 1.1 |
1.0 |
inlined instance call |
inl_i1 |
| 6.8 |
6.8 |
instance call |
i1 |
| 0.2 |
0.2 |
inlined this inst call |
inl_i1 |
| 6.2 |
6.2 |
this instance call |
i1 |
| 5.4 |
5.4 |
virtual call |
v1 |
| 5.4 |
5.4 |
this virtual call |
v1 |
| 6.6 |
6.5 |
interface call |
itf1 |
| 1.1 |
1.0 |
inst itf instance call |
itf1 |
| 0.2 |
0.2 |
this itf instance call |
itf1 |
| 5.4 |
5.4 |
inst itf virtual call |
itf5 |
| 5.4 |
5.4 |
this itf virtual call |
itf5 |
Однако эти результаты – это нерепрезентативные лучшие случаи, получающийся из-за того что вызовы производятся в цикле миллионы раз. В этих тестовых случаях виртуальные вызовы и вызовы методов интерфейса мономорфны (ссылка, через которую производится вызов, не изменяется со временем), так что комбинации кэширования и всевозможных механизмов предсказания ветвления, используемые в современных процессорах, приводят к нереалистично высоким результатам. На практике промахи мимо кэша при выполнении любых механизмов диспетчеризации и ошибки предсказания ветвления процессором будут замедлять выполнение вызовов виртуальных методов и методов интерфейсов во много раз.
Рассмотрим время вызова каждого из этих методов.
В первом случае, inlined static call, мы вызываем серию пустых статических методов s1_inl() и т.д. Поскольку компилятор полностью подставляет (inline) все вызовы, все кончается повторением пустого цикла.
Чтобы измерить примерную стоимость вызова статического метода, мы делаем статические методы s1() настолько большими, что их невыгодно встраивать в вызывающий метод.
Заметьте, что нам даже приходится использовать явную переменную falsePred (это булево поле, значение которого всегда равно false). Если написать:
static void s1()
{
if (false)
dummy(1, 2, 3, ..., 16);
}
|
JIT-компилятор устранит вызов dummy и подставит целиком (теперь пустое) тело метода, как ранее. Кстати, здесь часть 6.1 ns времени вызова нужно приписать тесту предиката (false) и переходу внутрь статического метода s1. (кстати, лучший способ устранить подстановку – атрибут CompilerServices.MethodImpl(MethodImplOptions.NoInlining)).
Такой же подход использовался для inlined instance call и regular instance call. Однако, поскольку спецификация языка C# гарантирует, что любой вызов ссылки на нулевой объект генерирует NullReferenceException, каждый вызов должен убедиться, что экземпляр не равен нулю. Это делается разыменованием ссылки на экземпляр.
В ассемблерном листинге 2 используется в качестве экземпляра статическая переменная t, поскольку при использовании локальной переменной
компилятор выносит проверку на null за пределы цикла.
Ассемблерный листинг 2. Код, генерируемый для "Instance method call" с проверкой на null.
t.i1()
00000012 8B 0D 30 21 A4 05 mov ecx,dword ptr ds:[05A42130h]
00000018 39 09 cmp dword ptr [ecx],ecx
0000001a E8 C1 DE FF FF call FFFFDEE0
|
Случаи inlined this instance call и this instance call одинаковы, за тем исключением, что экземпляр (instance) – это this; в этом случае проверка на null не нужна.
Ассемблерный код 3. Код, генерируемый для "this instance call"
this.i1()
00000012 8B CE mov ecx,esi
00000014 E8 AF FE FF FF call FFFFFEC8
|
Вызовы виртуальных методов работают практически так же, как и в стандартных C++-реализациях. Адрес каждого добавляемого виртуального метода помещается в новый слот таблицы методов типа. Каждая таблица методов унаследованного типа соответствует таблице базового типа и расширяет ее, а любое переопределение виртуального метода замещает адрес виртуального метода базового типа адресом виртуального метода унаследованного типа в соответствующем слоте таблицы методов унаследованного типа.
Вызов виртуального метода приводит к двум дополнительным операциям чтения. Затраты времени на выполнение этих операций сравнимо с вызовом "экземплярного" метода. Одна операция чтения нужна для получения адреса таблицы методов (который всегда находится в "this + 0"), а другая – для получения адреса метода из таблицы и его вызова (см. ассемблерный листинг 4).
Ассемблерный листинг 4. Код, генерируемый для "Virtual method call".
this.v1()
00000012 8B CE mov ecx,esi
00000014 8B 01 mov eax,dword ptr [ecx]
00000016 FF 50 38 call dword ptr [eax+38h]
|
И, наконец, вызов метода интерфейса. Этому нет прямого эквивалента в C++. Любой тип может реализовать любое количество интерфейсов, и каждому интерфейсу логически соответствует таблица методов. Для диспетчеризации одного метода интерфейса нужно просмотреть таблицу методов, карту интерфейсов, вхождение интерфейса в этой карте, а затем произвести непрямой вызов через соответствующее вхождение в секции интерфейса в таблице методов.
Ассемблерный листинг 5.Вызов метода интерфейса.
i.itf1()
00000012 8B 0D 34 21 A4 05 mov ecx,dword ptr ds:[05A42134h]
00000018 8B 01 mov eax,dword ptr [ecx]
0000001a 8B 40 0C mov eax,dword ptr [eax+0Ch]
0000001d 8B 40 7C mov eax,dword ptr [eax+7Ch]
00000020 FF 10 call dword ptr [eax]
|
Остальное (inst itf instance call, this itf instance call, inst itf virtual call, this itf virtual call) подтверждает мысль о том, что когда метод унаследованного типа реализует метод интерфейса, его по-прежнему можно вызвать через экземплярный вызов метода.
Например, в теста this itf instance call, при вызове реализации метода интерфейса через ссылку на экземпляр (а не интерфейс) метод интерфейса успешно подставляется (inlined) и стоимость падает почти до 0 ns. Реализация метода интерфейса потенциально предрасположена к подстановке (inlineable) даже при вызове ее как метода экземпляра.
Вызов еще не JIT-компилированных методов
Для статических и "экземплярных" вызовов методов (но не для виртуальных и вызовов методов интерфейса) JIT-компилятор сейчас генерирует различные последовательности вызовов метода в зависимости от того, был ли целевой метод подвергнут JIT-компиляции к моменту JIT-компиляции вызывающей стороны.
Если вызываемый метод еще не был скомпилирован, компилятор генерирует код вызова специальной заглушки. Таким образом, первый вызов целевого метода приходит к заглушке, которая запускает JIT-компиляцию метода, генерирующую native-код, и обновляет указатель на адрес нового native-кода.
Если вызываемый метод уже был скомпилирован, адрес его native-кода уже известен, и компилятор производит прямой вызов.
Создание нового объекта
Создание нового объекта состоит из двух фаз: размещения и инициализации.
В случае ссылочных типов объекты размещаются в куче, подвергающейся сборке мусора. В случае value-типов, как находящихся в стеке, так и встроенных в другие ссылочные или value-типы, объект value-типа находится по некоторому постоянному смещению от заключающей его структуры – никакого размещения не требуется.
Для типичных маленьких объектов ссылочных типов размещение в куче очень быстро. После каждой сборки мусора, за исключением закрепленных объектов, живые объекты из поколения 0 продвигаются в поколение 1, что дает распределителю памяти замечательный большой непрерывный кусок памяти для работы. Большинство операций распределения памяти включает только передвижение указателя свободной памяти и проверку, не выходит ли он за границы кучи. Это значительно эффективнее чем метод, традиционно используемый при реализации куч в С/C++ – просмотр списка свободных блоков памяти. GC даже принимает во внимание размер кэша машины, пытаясь удержать объекты поколения 0 в самой быстрой части иерархии память/кэш.
Поскольку наиболее вероятным паттерном размещения памяти в managed-приложениях является размещение большого числа короткоживущих объектов и последующее их уничтожение, мы рассмотрим также (в смысле времени) амортизированную стоимость сборки мусора для этих новых объектов.
Заметьте, что GC не тратит времени на траур по мертвым объектам. Если объект мертв, GC его не видит, не посещает, не уделяет ему и наносекунды внимания. GC волнует только благосостояние живых. (Исключение: финализируемые мертвые объекты – это особый случай. GC отслеживает их и нарочно продвигает мертвые финализируемые объекты в следующее поколение, задерживая финализацию. Это дорого и в худшем случае может продвигать в следующее поколение большие графы мертвых объектов. Таким образом, не нужно делать объекты финализируемыми, если это не вызвано необходимостью, а если уж приходится, подумайте об использовании паттерна Dispose, по возможности вызывающего GC.SuppressFinalizer.) Если этого не требует логика метода Finalize, не удерживайте в финализируемом объекте ссылки на другие объекты.
Конечно, амортизированная стоимость сборки мусора для больших короткоживущих объектов выше, чем для маленьких. Размещение каждого объекта двигает нас ближе к следующему циклу сборки мусора; с большими объектами это происходит гораздо быстрее. Раньше или позже наступит время платить. Циклы GC, особенно сборка поколения 0, очень быстры, но не бесплатны, даже если умерло подавляющее большинство новых объектов: чтобы найти (пометить) живые объекты, сперва нужно приостановить потоки и затем обойти стеки и другие структуры данных, чтобы собрать корневые ссылки на объекты в куче. (Возможно, более существенно влияет на стоимость использования короткоживущих объектов большого размера то, что их небольшое число занимает такой же объем кэша, что и множество объектов малого размера).
После выделения места под объект, остается его инициализировать (сконструировать). CLR гарантирует, что все ссылки на объекты предварительно инициализируются значением null, а все примитивные скалярные типы инициализируются 0, 0.0, false, и т.п. (Следовательно, этого не нужно делать в пользовательских конструкторах. Хотя и можно. Но помните, что JIT-компилятор не обязательно удалит ваши излишества.)
Кроме обнуления полей экземпляров, CLR инициализирует (только в случае ссылочных типов) внутренние поля реализаций объектов: указатель на таблицу методов и заголовок объекта, предваряющий указатель на таблицу методов. Массивы также получают поле Length, а массивы объектов – Length и поле, содержащее тип элемента.
Затем CLR вызывает конструктор объекта, если он есть. Конструктор любого типа, пользовательского или сгенерированного компилятором, сперва вызывает конструктор базового типа, а затем запускает определенную пользователем инициализацию, если таковая имеется.
| Avg |
Min |
Примитив |
Avg |
Min |
Примитив |
Avg |
Min |
Примитив |
| 2.6 |
2.6 |
new valtype L1 |
22.0 |
20.3 |
new reftype L1 |
22.9 |
20.7 |
new rt ctor L1 |
| 4.6 |
4.6 |
new valtype L2 |
26.1 |
23.9 |
new reftype L2 |
27.8 |
25.4 |
new rt ctor L2 |
| 6.4 |
6.4 |
new valtype L3 |
30.2 |
27.5 |
new reftype L3 |
32.7 |
29.9 |
new rt ctor L3 |
| 8.0 |
8.0 |
new valtype L4 |
34.1 |
30.8 |
new reftype L4 |
37.7 |
34.1 |
new rt ctor L4 |
| 23.0 |
22.9 |
new valtype L5 |
39.1 |
34.4 |
new reftype L5 |
43.2 |
39.1 |
new rt ctor L5 |
| |
|
|
22.3 |
20.3 |
new rt empty ctor L1 |
28.6 |
26.7 |
new rt no-inl L1 |
| |
|
|
26.5 |
23.9 |
new rt empty ctor L2 |
38.9 |
36.5 |
new rt no-inl L2 |
| |
|
|
38.1 |
34.7 |
new rt empty ctor L3 |
50.6 |
47.7 |
new rt no-inl L3 |
| |
|
|
34.7 |
30.7 |
new rt empty ctor L4 |
61.8 |
58.2 |
new rt no-inl L4 |
| |
|
|
38.5 |
34.3 |
new rt empty ctor L5 |
72.6 |
68.5 |
new rt no-inl L5 |
Теоретически в сценариях с глубоким наследованием это может дорого обойтись. Если E расширяет D расширяющее C расширяющее B расширяющее A (расширяющее System.Object), то инициализация E в любом случае повлечет за собой пять вызовов методов. На практике все не так плохо, поскольку компилятор удаляет вызовы пустых конструкторов базовых типов.
Ссылаясь на первую колонку таблицы 4, отметим, что можно создать и инициализировать структуру D с четырьмя полями типа int примерно за время, равное 8 целочисленным операциям сложения. Ассемблерный листинг 6 – это сгенерированный для трех разных циклов код, создающий A, C и E (в каждом цикле изменяется каждый новый экземпляр, что не позволяет JIT оптимизировать все насмерть).
Ассемблерный листинг 6. Создание объекта Value-типа.
A a1 = new A()
00000020 C7 45 FC 00 00 00 00 mov dword ptr [ebp-4],0
00000027 FF 45 FC inc dword ptr [ebp-4]
C c1 = new C()
00000024 8D 7D F4 lea edi,[ebp-0Ch]
00000027 33 C0 xor eax,eax
00000029 AB stos dword ptr [edi]
0000002a AB stos dword ptr [edi]
0000002b AB stos dword ptr [edi]
0000002c FF 45 FC inc dword ptr [ebp-4]
E e1 = new E()
00000026 8D 7D EC lea edi,[ebp-14h]
00000029 33 C0 xor eax,eax
0000002b 8D 48 05 lea ecx,[eax+5]
0000002e F3 AB rep stos dword ptr [edi]
00000030 FF 45 FC inc dword ptr [ebp-4]
|
Следующие пять замеров (new reftype L1, ... new reftype L5) относятся к пяти уровням наследования A, ..., E, без пользовательских конструкторов.
public class A { int a; }
public class B : A { int b; }
public class C : B { int c; }
public class D : C { int d; }
public class E : D { int e; }
|
Сравнивая время, затрачиваемое на создание ссылочных и value-типов, можно увидеть, что амортизированная стоимость размещения и освобождения каждого экземпляра на тестовой машине – около 20 ns (20X время сложения int). Размещение, инициализация и удаление 50 миллионов короткоживущих объектов в секунду – это быстро. Для маленьких объектов, состоящих из 5 полей, размещение и сборка составляют всего половину времени создания объекта. См. ассемблерный листинг 7.
Ассемблерный листинг 7. Создание объекта ссылочного типа.
new A()
0000000f B9 D0 72 3E 00 mov ecx,3E72D0h
00000014 E8 9F CC 6C F9 call F96CCCB8
new C()
0000000f B9 B0 73 3E 00 mov ecx,3E73B0h
00000014 E8 A7 CB 6C F9 call F96CCBC0
new E()
0000000f B9 90 74 3E 00 mov ecx,3E7490h
00000014 E8 AF CA 6C F9 call F96CCAC8
|
Последние три набора из пяти представляют вариации сценария создания унаследованного класса.
- New rt empty ctor L1, ..., new rt empty ctor L5: у каждого из типов A, ..., E есть пустой пользовательский конструктор. Все вызовы пустых конструкторов устраняются путем подстановки (inlining), сгенерированный код такой же, как приведенный выше.
- New rt ctor L1, ..., new rt ctor L5: у каждого из типов A, ..., E есть пользовательский конструктор, который устанавливает его переменную экземпляра в 1:
public class A { int a; public A() { a = 1; } }
public class B : A { int b; public B() { b = 1; } }
public class C : B { int c; public C() { c = 1; } }
public class D : C { int d; public D() { d = 1; } }
public class E : D { int e; public E() { e = 1; } }
|
Компилятор встраивает (inlines) тела всех вложенных конструкторов базовых классов в точку вызова оператора new (Ассемблерный листинг 8).
Ассемблерный листинг 8. Inline-подстановка большой иерархии конструкторов базовых классов.
new A()</com>
00000012 B9 A0 77 3E 00 mov ecx,3E77A0h
00000017 E8 C4 C7 6C F9 call F96CC7E0
0000001c C7 40 04 01 00 00 00 mov dword ptr [eax+4],1
new C()</com>
00000012 B9 80 78 3E 00 mov ecx,3E7880h
00000017 E8 14 C6 6C F9 call F96CC630
0000001c C7 40 04 01 00 00 00 mov dword ptr [eax+4],1
00000023 C7 40 08 01 00 00 00 mov dword ptr [eax+8],1
0000002a C7 40 0C 01 00 00 00 mov dword ptr [eax+0Ch],1
new E()</com>
00000012 B9 60 79 3E 00 mov ecx,3E7960h
00000017 E8 84 C3 6C F9 call F96CC3A0
0000001c C7 40 04 01 00 00 00 mov dword ptr [eax+4],1
00000023 C7 40 08 01 00 00 00 mov dword ptr [eax+8],1
0000002a C7 40 0C 01 00 00 00 mov dword ptr [eax+0Ch],1
00000031 C7 40 10 01 00 00 00 mov dword ptr [eax+10h],1
00000038 C7 40 14 01 00 00 00 mov dword ptr [eax+14h],1
|
- New rt no-inl L1, ..., new rt no-inl L5: у каждого из типов A, ..., E есть пользовательский конструктор, специально созданный так, чтобы оказаться чрезмерно дорогим для подстановки его тела по месту. Этот сценарий симулирует стоимость создания сложных объектов с глубокой иерархией наследования и довольно большими конструкторами.
public class A { int a; public A() { a = 1; if (falsePred) dummy(...); } }
public class B : A { int b; public B() { b = 1; if (falsePred) dummy(...); } }
public class C : B { int c; public C() { c = 1; if (falsePred) dummy(...); } }
public class D : C { int d; public D() { d = 1; if (falsePred) dummy(...); } }
public class E : D { int e; public E() { e = 1; if (falsePred) dummy(...); } }
|
Последние 5 замеров в таблице 4 показывают дополнительные расходы на вызов вложенных базовых конструкторов.
Интерлюдия: CLR Profiler Demo
Перейду к краткой демонстрации CLR Profiler. CLR Profiler, раньше называвшийся Allocation Profiler, использует CLR Profiling API для сбора данных о событиях – вызова, возврата и размещения объектов, и событиях сборки мусора по мере работы приложения. (CLR Profiler – это "агрессивный" профилировщик. Это значит, что он, увы, существенно замедляет исследуемое приложение.) После сбора информации о событиях CLR Profiler можно использовать для исследования размещения памяти и поведения GC, включая взаимодействие между иерархическим графом вызовов и паттернами заема памяти.
CLR Profiler достоин изучения потому, что для многих "требующих производительности" managed-приложений знание профиля размещения данных необходимо для снижения физически используемого объема памяти.
CLR Profiler может также показать, в каких методах распределяется больше памяти, чем предполагалось, и может выявить случаи, когда вы неумышленно сохраняете ссылки на бесполезные графы объектов, которые иначе были бы удалены GC. Общей проблемой является создание программного кэша или lookup-таблицы для элементов, которые больше не нужны или легко могут быть созданы заново. Трагично, когда в кэше сохраняются графы объектов после того, как они перестали быть нужными.
На рисунке 1 показана временная диаграмма кучи при исполнении замеров работы теста. Зубчатый образец показывает размещение многих тысяч экземпляров объектов С (пурпурный), D (фиолетовый) и Е (голубой). Каждые несколько миллисекунд тратятся очередные 150 KB RAM в куче новых объектов (поколение 0), а GC быстро пробегает по ней, собирает мусор и продвигает живые объекты в поколение 1. Примечательно, что даже в такой агрессивной (медленной) профилирующей среде, в интервале 100 ms (2.8 с – 2.9 с, рис. 1) выполняется около 8 циклов сборки мусора в поколении 0. Затем, в точке 2.977 сек, создавая пространство для очередного экземпляра E, GC выполняет сборку мусора в поколении 1, после чего "пила" продолжается с более низкого стартового адреса.
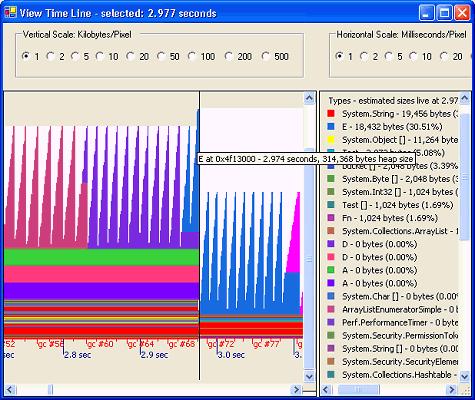
Рисунок 1. CLR Profiler.
Заметьте, что чем больше объект (E больше D, который больше C), тем быстрее заполняется куча поколения 0 и тем чаще выполняются циклы сборки мусора.
Приведения и проверки типов экземпляров
Фундаментом безопасного, надежного и проверяемого управляемого кода является типобезопасность. Если бы можно было привести объект к неверному типу, это вело бы к нарушению целостности CLR.
| Avg |
Min |
Примитив |
Avg |
Min |
Примитив |
| 0.4 |
0.4 |
cast up 1 |
0.8 |
0.8 |
isinst up 1 |
| 0.3 |
0.3 |
cast down 0 |
0.8 |
0.8 |
isinst down 0 |
| 8.9 |
8.8 |
cast down 1 |
6.3 |
6.3 |
isinst down 1 |
| 9.8 |
9.7 |
cast (up 2) down 1 |
10.7 |
10.6 |
isinst (up 2) down 1 |
| 8.9 |
8.8 |
cast down 2 |
6.4 |
6.4 |
isinst down 2 |
| 8.7 |
8.6 |
cast down 3 |
6.1 |
6.1 |
isinst down 3 |
Под cast понимается приведение типов, под isinst – проверка типа объекта, что соответствует оператору "(type)" и "as" соответственно. – прим.ред.
В таблице 5 приведены затраты на эти принудительные проверки типов. Приведение от унаследованного типа к базовому всегда безопасно – и ничего не стоит. Однако приведение от базового типа к унаследованному должно проверяться.
Операция приведения типов преобразует объектную ссылку в ссылку или объект указанного типа, или же генерирует InvalidCastException.
Инструкция CIL isinst используется для реализации ключевого слова C# as:
Если ac – не B или не унаследовано от B, результатом будет null, а не исключение.
Листинг 2 демонстрирует один из циклов с приведением типов, а ассемблерный листинг 9 – сгенерированный код одного из приведений к базовому типу. Для выполнения приведения компилятор делает прямой вызов процедуры-хелпера.
Листинг 2. Цикл для теста приведения типов.
public static void castUp2Down1(int n)
{
A ac = c; B bd = d; C ce = e; D df = f;
B bac = null; C cbd = null; D dce = null; E edf = null;
for (n /= 8; --n >= 0; )
{
bac = (B)ac; cbd = (C)bd; dce = (D)ce; edf = (E)df;
bac = (B)ac; cbd = (C)bd; dce = (D)ce; edf = (E)df;
}
}
|
Ассемблерный листинг 9. Приведение к базовому типу.
bac = (B)ac
0000002e 8B D5 mov edx,ebp
00000030 B9 40 73 3E 00 mov ecx,3E7340h
00000035 E8 32 A7 4E 72 call 724EA76C
|
Свойства
В управляемом коде свойство – это пара методов (get_ и set_), действующих как поле объекта. Метод get_ получает значение свойства, а set_ задает новое значение.
Во всем остальном свойства ведут себя (и стоят) как обычные методы экземпляров или виртуальные методы. Если вы используете свойство для простого получения или задания значения поля экземпляра, оно обычно подставляется по месту, как и любой маленький метод.
В таблице 6 показано время, нужное на считывание или установку значений целочисленных полей и свойств экземпляра. Стоимость считывания или установки значения свойства действительно идентична прямому доступу к нижележащему полю, если свойство не объявлено виртуальным. В последнем случае стоимость примерно соответствует стоимости вызова виртуального метода. Никаких сюрпризов.
| Avg |
Min |
Примитив |
| 1.0 |
1.0 |
get field |
| 1.2 |
1.2 |
get prop |
| 1.2 |
1.2 |
set field |
| 1.2 |
1.2 |
set prop |
| 6.4 |
6.3 |
get virtual prop |
| 6.4 |
6.3 |
set virtual prop |
Барьеры записи (Write Barriers)
Сборщик мусора CLR хорошо использует "гипотезу поколений" – большинство новых объектов умирают молодыми – для снижения затрат на сборку.
Куча логически делится на поколения. Самые новые объекты живут в поколении 0. Эти объекты еще не подвергались сборке мусора. При сборке мусора в поколении 0 GC определяет какие объекты доступны из набора корней GC (и есть ли такие), в которые входят объектные ссылки в машинных регистрах, стеке, ссылки на объекты-статические поля классов и т.д. Транзитивно доступные объекты считаются "живыми" и продвигаются (копируются) в поколение 1.
Поскольку общий размер кучи может составлять сотни мегабайт, а размер кучи для поколения 0 может составлять только 256 КВ, ограничение отслеживаемых GC графов объектов поколением 0 – существенная оптимизация, обеспечивающая быстроту работы GC CLR.
Однако можно помещать ссылки на объекты поколения 0 в полях объектов поколений 1 и 2. Поскольку объекты поколений 1 и 2 не сканируются при сборке нулевого поколения, то, если такая ссылка единственная, GC может ошибочно посчитать объект нулевого поколения мусором. Это недопустимо!
Вместо этого все установки ссылочных полей объектов, размещаемых в куче, защищаются специальным кодом, именуемым "барьером записи" (Write Barrier). Это код, который отслеживает присваивания ссылочным полям объектов более старых поколений ссылок на объекты более новых поколений. Такие "старые" объектные ссылки добавляются к набору корней GC.
Стоимость барьера записи, возникающего при установке значений ссылочных свойств, сравнима со стоимостью простого вызова метода (таблица 7). Это еще одна трата, отсутствующая в C/C++-коде, но это невысокая цена за сверхбыстрые размещение объектов и сборку мусора, а также другие преимущества автоматического управления памятью.
| Avg |
Min |
Примитив |
| 6.4 |
6.4 |
write barrier |
Барьеры записи могут быть дороги в сжатых внутренних циклах. Но в будущем можно ожидать усовершенствования техники компиляции, которое снизит количество применений барьеров записи и общую амортизированную стоимость.
Вы можете подумать, что барьеры записи нужны только при помещении объектных ссылок в поля ссылочных объектов. Однако в методах value-типов хранение полей объектных ссылок (если они есть) тоже защищается барьером записи. Это необходимо, так как сам по себе value-тип может иногда быть встроен в ссылочный тип, находящийся в куче.
Доступ к элементам массивов
Для диагностики и предотвращения ошибок, связанных с выходом за границы массива и повреждением кучи, а также для защиты целостности CLR как такового, при чтении и записи значений элементов массива производится проверка границ, обеспечивающая нахождение индекса в интервале [0, array.Length - 1] включительно, или генерация IndexOutOfRangeException.
Тесты, результаты которых приведены в таблице 8, показывают время чтении/записи элементов массивов типа int[ ] или A[ ].
| Avg |
Min |
Примитив |
| 1.9 |
1.9 |
чтение int |
| 1.9 |
1.9 |
запись int |
| 2.5 |
2.5 |
чтение obj |
| 16.0 |
16.0 |
запись obj |
Проверка границ требует сравнения индекса массива с неявным полем array.Length. В ассемблерном листинге 10 показано, как всего за 2 инструкции проверяется, что значение индекса не меньше 0 и не больше или равно array.Length – иначе производится переход к последовательности строк, генерирующей исключение.
Ассемблерный листинг 10. Чтение элемента массива целых.
sum += a[i]
00000024 3B 4A 04 cmp ecx,dword ptr [edx+4]
00000027 73 19 jae 00000042
00000029 03 7C 8A 08 add edi,dword ptr [edx+ecx*4+8]
...
00000042 33 C9 xor ecx,ecx
00000044 E8 52 78 52 72 call 7252789B
|
Благодаря качественной оптимизации кода JIT-компилятор часто удаляет излишние проверки границ.
Вспоминая предыдущие разделы, можно ожидать, что запись значений элементов массива объектов будет значительно дороже. Чтобы сохранить ссылку на объект в массиве объектных ссылок, runtime должен:
- проверить, что индекс не выходит за границы массива;
- проверить, что объект – экземпляр типа элементов массива;
- создать барьер записи (замечающий все ссылки между поколениями объектов, ведущие от массива к объекту.)
Эта последовательность довольно длинна. Вместо того, чтобы генерировать ее при каждой модификации ячеек массивов объектов, компилятор генерирует код вызова хелпер-функции. Этот вызов плюс упомянутые три действия занимают дополнительное время. В ассемблерном листинге 11 показан пример генерируемого кода.
Ассемблерный листинг 11. Установка значения элемента массива объектов.
objarray[1] = obj
00000027 53 push ebx
00000028 8B CF mov ecx,edi
0000002a BA 01 00 00 00 mov edx,1
0000002f E8 A3 A0 4A 72 call 724AA0D7
|
Boxing и Unboxing
Партнерство между компиляторами .NET и CLR позволяет value-типам, включая типы-примитивы вроде int (System.Int32), вести себя как ссылочным типам – то есть обращаться к ним по объектным ссылкам. Эта возможность – "синтаксический сахар" – позволяет передавать value-типы методам как объекты, хранить их в коллекциях приведенными к object и т.д.
Boxing value-типа – это создание объекта ссылочного типа, содержащего копию соответствующего value-типа. Концептуально это то же самое, что создание класса с неименованным полем экземпляра того же типа, что value-тип.
Unboxing value-типа – это копирование значения из объекта в новый экземпляр value-типа.
Как показывает таблица 9 (в сравнении с таблицей 4, амортизированное время, нужное для boxing-а int, и последующего удаления его GC, сравнимо со временем, нужным для создания экземпляра небольшого класса с одним полем типа int.
| Avg |
Min |
примитив |
| 29.0 |
21.6 |
boxing int |
| 3.0 |
3.0 |
unboxing int |
Для Unboxing-а объекта типа int требуется явное приведение к int. Это порождает код, который производит сравнение типа объекта (представленного его адресом таблицы методов) и адреса таблицы методов упакованного int. Если они равны, значение копируется из объекта, иначе генерируется исключение (см. ассемблерный листинг 12).
Ассемблерный листинг 12.Boxing и unboxing int.
box object o = 0
0000001a B9 08 07 B9 79 mov ecx,79B90708h
0000001f E8 E4 A5 6C F9 call F96CA608
00000024 8B D0 mov edx,eax
00000026 C7 42 04 00 00 00 00 mov dword ptr [edx+4],0
unbox sum += (int)o
00000041 81 3E 08 07 B9 79 cmp dword ptr [esi],79B90708h
00000047 74 0C je 00000055
00000049 8B D6 mov edx,esi
0000004b B9 08 07 B9 79 mov ecx,79B90708h
00000050 E8 A9 BB 4E 72 call 724EBBFE
00000055 8D 46 04 lea eax,[esi+4]
00000058 3B 08 cmp ecx,dword ptr [eax]
0000005a 03 38 add edi,dword ptr [eax]
|
Делегаты
В С указатель на функцию – это примитивный тип данных, который буквально хранит адрес функции.
В C++ добавлены указатели на функции-члены. Указатель на функцию-член (pointer to member function, PMF) представляет отложенный вызов функции-члена. Адрес невиртуальной функции-члена может быть простым адресом кода, но адрес виртуальной функции-члена должен заключать в себе конкретный вызов виртуальной функции-члена – разыменование такого PMF является вызовом виртуальной функции.
Чтобы разыменовать PMF в C++, нужно предоставить экземпляр:
A* pa = new A;
void (A::*pmf)() = &A::af;
(pa->*pmf)();
|
В прошлом, в команде разработчиков компилятора Visual C++, мы спрашивали себя, что за зверь это выражение pa->*pmf (оператор без вызова функции)? Мы назвали его связанным указателем на функцию-член, но латентный вызов функции-члена подходит не хуже.
Возвращаясь к управляемому коду, объект-делегат именно таков и есть – латентный вызов метода. Объект-делегат представляет как вызываемый метод, так и экземпляр класса, у которого нужно вызвать этот метод – или, в случае делегата статического метода, просто вызываемый статический метод.
(Как сказано в документации: объявление делегата определяет ссылочный тип, который может быть использован для инкапсуляции метода с особой сигнатурой. Экземпляр делегата инкапсулирует статический или экземплярный метод. Делегаты несколько похожи на указатели на функции в C++, но делегаты защищены и типобезопасны.)
Делегаты в C# наследуются от MulticastDelegate. Этот тип предоставляет семантику, включающую возможность построить список вызовов, состоящий из пар (object,method), вызываемых при обращении к делегату.
Делегаты также предоставляют возможность асинхронного вызова метода. После определения типа-делегата и создания его экземпляра, инициализированного латентным вызовом метода, можно вызвать его синхронно (синтаксис вызова метода) или асинхронно, через BeginInvoke. Если вызван BeginInvoke, runtime ставит вызов в очередь и немедленно возвращает управление вызывающей стороне. Целевой метод вызывается позже, в потоке из пула.
Вся эта семантика недешево стоит. Сравните таблицы 10 и 3 – вызов делегата примерно в восемь раз медленнее вызова метода. Возможно, в будущем стоимость вызова делегата уменьшится (в бета-версиях .NET Framework 2.0 скорость вызова делегатов значительно увеличена. – прим. ред.).
| Avg |
Min |
Примитив |
| 41.1 |
40.9 |
вызов делегата |
Промахи мимо кэша, Page Faults и архитектура компьютера
В "старые добрые времена", примерно в 1983, процессоры были медленными (около 0.5 миллиона инструкций/с), RAM – относительно быстрой, но маленькой (время доступа ~300 ns, 256 KB DRAM), а диски – большими и медленными (время доступа ~25 ms при объеме в 10 MB). Процессоры были скалярными CISC, большинство операций с плавающей точкой выполнялось программно, а кэша вовсе не было.
За двадцать с лишним лет существования закона Мура, примерно к 2003, процессоры стали быстрыми (производящими до 3 операций за цикл на частоте 3 GHz), RAM (относительно) – очень медленной (время доступа ~100 ns, 512 MB of DRAM), а диски просто невероятно медленными и огромными (время доступа ~10 ms при объеме в 100 GB). Процессоры теперь – суперскалярные многопоточные отслеживающие состояние кэша RISC (выполняющие декодированные CISC0инструкции) с несколькими уровнями кэша – например, некий сервер-ориентированный процессор может иметь 32 KB кэша данных 1 уровня (возможно, с латентностью в 2 цикла), 512 KB кэша данных 2 уровня и 2 MB кэша данных 3 уровня (с латентностью в десяток циклов) – и все это на чипе.
В добрые старые времена вы могли (и иногда даже делали) посчитать байты в написанном коде и число циклов, за которое выполнится этот код. Чтение и запись данных занимали примерно столько же циклов, сколько сложение. Современные процессоры используют предсказание ветвлений, спекуляцию, исполнение с изменением последовательности многих функций, чтобы отыскать параллелизм уровня инструкций и, таким образом, продвигаться вперед одновременно на нескольких фронтах.
Сейчас самый быстрый PC может выполнять до ~9000 операций в микросекунду, но в ту же микросекунду может записывать или считывать в DRAM значения приблизительно 10 строк кэша. Среди компьютерных архитекторов это известно как удар о стену памяти (hitting the memory wall). Кэш прячет латентность памяти, но до определенных пределов. Если код или данные не умещаются в кэше, наши сверхзвуковые 9000 операций в микросекунду деградируют до трехколесных 10 загрузок в микросекунду.
А (не дайте этому случиться с вами) если память, физически используемая вашей программой (working set), превысит доступную физическую память, и программа начнет работать с файлом подкачки, то за каждые 10000 микросекунд, затрачиваемые на доступ к диску, мы теряем 90 миллионов операций, которые могли бы приблизить пользователя к нужному результату. Это так ужасно, что я искренне надеюсь, что, начиная с этого дня, вы будете измерять память, физически используемую вашими программами, и использовать CLR Profiler для устранения ненужных заемов памяти и сохраненных по небрежности графов объектов.
Но что общего у этих рассуждений со знанием стоимости примитивов управляемого кода? Все.
Вспоминая таблицу 1, общий список времени исполнения примитивов управляемого кода, измеренного на 1.1 GHz P-III, обратите внимание, что время исполнения любого примитива, даже амортизированная стоимость размещения, инициализации и утилизации объекта с пятью полями и пятью уровнями явных вызовов конструкторов, меньше, чем одно обращение к DRAM. Любой промах мимо кэша процессора приводит к большим затратам времени, чем практически любая одиночная операция с управляемым кодом.
Время для простой демонстрации: что быстрее – суммировать массив целых или суммировать эквивалентный ему связанный лист целых?
Подумайте минутку. Для небольших элементов, таких, как целые (int), затраты памяти на элемент массива составляют четверть от того, что нужно при использовании связанного списка. (каждый узел связанного списка содержит два слова служебных данных (связанных с представлением объекта) и два слова – в полях (указатель на следующий узел и собственно int). Это приводит к ухудшению использования кэша. Счет один-ноль в пользу массива.
Но обход массива может привести к проверкам выхода за границы массива для каждого элемента. Вы только что видели, что такие проверки отнимают время. Возможно, это сдвинет чашу весов в пользу связанного списка?
Ассемблерный листинг 13.Суммирование массива целых vs. суммирования связанного списка целых.
sum int array: sum += a[i]
00000024 3B 4A 04 cmp ecx,dword ptr [edx+4]
00000027 73 19 jae 00000042
00000029 03 7C 8A 08 add edi,dword ptr [edx+ecx*4+8]
for (int i = 0
0000002d 41 inc ecx
0000002e 3B CE cmp ecx,esi
00000030 7C F2 jl 00000024
sum int linked list: sum += l.item
0000002a 03 70 08 add esi,dword ptr [eax+8]
0000002d 8B 40 04 mov eax,dword ptr [eax+4]
sum += l.item
00000030 03 70 08 add esi,dword ptr [eax+8]
00000033 8B 40 04 mov eax,dword ptr [eax+4]
sum += l.item
00000036 03 70 08 add esi,dword ptr [eax+8]
00000039 8B 40 04 mov eax,dword ptr [eax+4]
sum += l.item
0000003c 03 70 08 add esi,dword ptr [eax+8]
0000003f 8B 40 04 mov eax,dword ptr [eax+4]
for (m /= 4
{
00000042 49 dec ecx
00000043 85 C9 test ecx,ecx
00000045 79 E3 jns 0000002A
|
Согласно ассемблерному коду 13, вместо цикла на m итераций, я создал цикл, в каждой итерации которого происходит 4 суммирования, тем самым уменьшив число итераций в четыре раза, и даже исключил традиционную проверку на null. В цикле для каждого элемента массива содержится шесть инструкций, а для каждого элемента связанного списка всего 11/4 = 2.75 инструкций. Как вы думаете, что быстрее?
Условия теста: сперва создается массив из миллиона целых и простой традиционный связанный список из миллиона целых (1 миллиона элементов списка). Затем измеряется, сколько времени (на элемент) занимает суммирование первых 1 000, 10 000, 100 000 и 1 000 000 элементов. Каждый цикл повторяется много раз, чтобы узнать, кто быстрее и в каких случаях.
Так что быстрее? После предположений, посмотрите на ответ: последние восемь строк в таблице 1.
Интересно! Время существенно увеличивается, когда объем данных становится больше эффективного объема кэша. Версия с массивом всегда быстрее версии со связанным списком, несмотря на то, что исполняет вдвое больше инструкций. А для 100 000 элементов версия с массивом в семь раз быстрее!
Почему это так? Во-первых, меньше элементов связанного списка умещается в любом уровне кэша. Все эти заголовки объектов и ссылки занимают место. Во-вторых, в случае связанного списка, пока текущий элемент списка находится в кэше, процессор не может начать выборку следующей ссылки на узел.
В случае 100 000 элементов процессор проводит (в среднем) приблизительно (22-3.5)/22 = 84% времени в бездействии, ожидая пока строка кэша некоторого узла списка будет считана из DRAM. Это звучит плохо, но вещи могут быть намного хуже. Поскольку элементы связанного списка малы, в строке кэша помещается много элементов. Мы обходим список в порядке заполнения, и, поскольку GC сохраняет этот порядок даже при удалении мертвых объектов из кучи, похоже, что при выборке одного узла из строки кэша, следующие несколько узлов также оказываются в кэше. Если бы узлы были больше, или их адреса располагались в случайном порядке, то каждое посещение узла могло бы быть промахом мимо кэша. Добавление 16 байт к каждому узлу списка удваивает время, затрачиваемое на обход элемента, доводя его до 43 ns, добавление 32 байт – до 67 ns, а 64 байт – еще раз удваивает его, доводя до 146 ns, вероятно, средней латентности DRAM на тестовой машине.
Какой урок нужно вынести из этого? Избегать связанных списков на 100 000 элементов? Нет. Урок в том, что эффект кэша может превзойти любые рассуждения об преимуществах эффективности управляемого на низком уровне против native-кода. Если вы пишете критичный к производительности управляемый код, особенно – работающий с большими структурами данных, помните об эффектах кэширования, продумывайте паттерны доступа к структурам данных и боритесь за меньший размер данных и высокую локальность ссылок.
Кстати, есть тенденция, что стена памяти, соотношение времени доступа к DRAM и времени операции CPU, в будущем только увеличится.
Вот некоторые правила дизайна, учитывающего кэширование:
- Экспериментируйте с вашими сценариями (и измеряйте), поскольку эффекты второго порядка труднопредсказуемы и правила не стоят бумаги, на которой они печатаются.
- Некоторые структуры данных, например, массивы, используют неявную близость (implicit adjacency) для представления связей между данными. Другие, например, связанные списки, используют для представления связей явные указатели (ссылки). Неявная близость, в общем, предпочтительна – "неявность" экономит место по сравнению с указателями; близость дает стабильную локальность ссылки, и может позволить процессору начать работу вместо погони за следующим указателем.
- Некоторые паттерны использования благоприятствуют применению гибридных структур – списков небольших массивов, массивов массивов или В-деревьев.
- Возможно, некоторые алгоритмы, использующие доступ к диску и разработанные во времена, когда доступ к диску стоил всего 50,000 инструкций CPU, должны быть сейчас переработаны, поскольку сейчас даже использование DRAM занимает тысячи операций CPU.
- Поскольку GC CLR сохраняет относительный порядок объектов, объекты, размещенные вместе по времени (и в одном потоке) имеют тенденцию оставаться близко расположенными в пространстве. Можно попробовать использовать этот феномен для осмысленного группирования данных в общих строках кэша.
- Вы можете захотеть разбить данные на "горячие" части, которые часто используются и умещаются в кэше, и "холодные", используемые время от времени и удаляемые из кэша.
Самостоятельные эксперименты с замерами времени
Для измерения времени в этой статье я использовал Win32-счетчик производительности QueryPerformanceCounter (и QueryPerformanceFrequency).
Из-за ограничений по времени и месту здесь не рассматриваются блокировки, обработка исключений или система безопасности доступа к коду.
Кстати, ассемблерные листинги, приведенные в этой статье, получены с помощью Disassembly Window в VS.NET 2003. Здесь есть хитрость. Если запустить приложение в отладчике VS.NET, даже как оптимизированный исполняемый файл в Release-режиме, оно будет исполняться в отладочном режиме, в котором оптимизация, например, подстановка, отключена. Я нашел единственный путь получить оптимизированный native-код, создаваемый JIT-компилятором – запустить приложение вне отладчика, а затем подключиться к нему с помощью Debug.Processes.Attach.
Модель стоимости места?
Размышления о низком уровне (некоторые из них специфичны для C# (TypeAttributes.SequentialLayout) и х86:
- Размер value-типа в общем случае – это общий размер его полей, с 4-байтными или меньшими полями, выровненными по их естественным границам.
- Для реализации объединений можно использовать атрибуты [StructLayout(LayoutKind.Explicit)] и [FieldOffset(n)].
- Размер ссылочного типа – 8 байт плюс общий размер его полей, округленный до границы следующих 4 байт, с с 4-байтными или меньшими полями, выровненными по их естественным границам.
ПРИМЕЧАНИЕ
Примечание редакции:
Автор предлагает работать с функциями вручную, хотя гораздо удобнее обернуть их в класс-обертку. Вот код подобной обертки, взятый из http://rsdn.ru/Forum/Message.aspx?mid=249579&only=1:
using System;
using System.Runtime.InteropServices;
namespace Utils
{
/// <summary>
/// Эта структура позволяет подсчитать скорость выполнения кода одним из
/// наиболее точных способов. Фактически вычисления производятся в тактах
/// процессора, а потом переводятся в секунды (десятичная часть
/// является долями секунды).
/// </summary>
public struct PerfCounter
{
Int64 _start;
/// <summary>
/// Начинает подсчет времени выполнения.
/// </summary>
public void Start()
{
_start = 0;
QueryPerformanceCounter(ref _start);
}
/// <summary>
/// Завершает подсчет времени исполнения и возвращает время в секундах.
/// </summary>
/// <returns>Время в секундах, потраченное на выполнение участка
/// кода. Десятичная часть отражает доли секунды.</returns>
public float Finish()
{
Int64 finish = 0;
QueryPerformanceCounter(ref finish);
Int64 freq = 0;
QueryPerformanceFrequency(ref freq);
return (((float)(finish - _start) /(float)freq));
}
[DllImport("Kernel32.dll")]
static extern bool QueryPerformanceCounter(ref Int64 performanceCount);
[DllImport("Kernel32.dll")]
static extern bool QueryPerformanceFrequency(ref Int64 frequency);
}
}
Использовать этот класс можно следующим образом:
// Где-нибудь объявляем переменную...
PerfCounter timer = new PerfCounter();
timer.Start(); // Начало замера
// тестируемый код...
// Выводим результат в консоль.
Console.WriteLine("Время выполнения в секундах: {0:### ### ##0.0000}"
timer.Finish());
Одну переменную можно использовать многократно.
|
- В C# объявления перечислений могут определять произвольный интегральный базовый тип (кроме char) – так что можно определять 8-, 16-, 32- и 64-битные перечисления.
- Как и в С/C++ часто можно сэкономить несколько десятков процентов места, занимаемого большим объектом, правильно задавая размер интегральных полей.
- Можно проанализировать размер объектов ссылочного типов с помощью CLR Profiler.
- Большие объекты (десятки килобайт и более) содержатся в отдельной куче больших объектов для предотвращения дорогого копирования.
- Финализируемые объекты до сборки существуют лишнее поколение – используйте их экономно и обдумайте использование паттерна Dispose.
Общие размышления:
- Каждый AppDomain сейчас является причиной существенных издержек. Многие структуры рантайма и .NET Framework не разделяются между доменами приложений.
- Внутри процесса JIT-компилированный код, как правило, не разделяются между доменами приложений. Некоторые варианты работы рантайма позволяют изменить такое поведение. См. документацию по CorBindToRuntimeEx и флагу STARTUP_LOADER_OPTIMIZATION_MULTI_DOMAIN.
- В любом случае JIT-компилированный код не используется совместно несколькими процессами. Если у вас есть компонент, загружаемый во многие процессы, подумайте о предварительной компиляции его с помощью NGEN для совместного использования native-кода.
Reflection
Как говорится, "Если вы спрашиваете, сколько стоит Reflection, значит, вам оно не по карману." Если вы дочитали до этого места, вы знаете, как важно спрашивать, что сколько стоит, и измерять эту стоимость.
Reflection – полезная и мощная возможность, но по сравнению с JIT-компилированным кодом она не является ни быстрой, ни компактной. Вас предупредили. Меряйте сами.
Заключение
Теперь вы знаете (более-менее) чего стоит управляемый код на низком уровне. Теперь у вас есть базовое понимание, необходимое для принятия более умных решений при создании более быстрого управляемого кода.
Мы видели, что JIT-компилированный управляемый код может так же "нажать на газ до упора", как native-код.
Есть случаи, когда производительность не имеет значения, и случаи, когда она – наиболее важное свойство продукта. Корень всего зла – излишняя оптимизация. Но в не меньшей степени – невнимание к эффективности. Вы – профессионал, художник, мастер. Вам нужно быть уверенными в том, сколько что стоит. Если вы этого не знаете – постоянно измеряйте.
Что касается команды CLR, мы продолжаем работать над тем, чтобы сделать платформу, существенно более продуктивную, нежели native-код, и при этом такую же быструю, как native-код. Можете ожидать, что все будет становиться лучше и лучше. Оставайтесь с нами.
Ссылки
- David Stutz et al, Shared Source CLI Essentials. O'Reilly and Assoc., 2003. ISBN 059600351X.
- Jan Gray, C++: Under the Hood.
- Gregor Noriskin, Writing High-Performance Managed Applications : A Primer, MSDN.
- Rico Mariani, Garbage Collector Basics and Performance Hints, MSDN.
- Emmanuel Schanzer, Performance Tips and Tricks in .NET Applications, MSDN.
- Emmanuel Schanzer, Performance Considerations for Run-Time Technologies in the .NET Framework, MSDN.
- vadump (Platform SDK Tools), MSDN.
- .NET Show, [Managed] Code Optimization, Sept. 10, 2002, MSDN.
Copyright © 1994-2016 ООО "К-Пресс"
