Языковой инструментарий: новая жизнь языков предметной области (Domain Specific Languages)
Автор: Мартин Фаулер Перевод: А.Максимова
Опубликовано: 26.02.2006
Новые идеи в области разработки программного обеспечения, как правило, представляют собой лишь вариации на тему старых. В этой статье я расскажу об одной из таких идей, а именно о создании приложений, которые я называю "языковым инструментарием": Intentional Software, Meta Programming System, которую разрабатывает компания JetBrains и Software Factories, которые делают в Microsoft. Все эти приложения используют давно известный подход к разработке программного обеспечения - назовем его "языкоориентированным программированием". Благодаря использованию в них инструментария современных сред разработки (IDE), этот вид программирования становится гораздо более жизнеспособным. Как бы там ни сложилось в будущем, я уверен, что этот вид приложений на настоящий момент является самым интересным явлением на горизонте нашей индустрии. И уж достаточно интересным для того, чтобы написать это эссе и попробовать изложить хотя бы в общих чертах их суть и возможную выгоду от их использования.
Давным-давно существует такой стиль программирования, при котором программные приложения пытаются описывать с помощью языков, специфичных для соответствующей предметной области. В Unix это "малые языки", которые генерируют программный код посредством lex и yacc; в Lisp такие языки разрабатывают внутри самого Lisp, чаще всего используя его макросы. Однако такой стиль программирования пока не нашел широкого применения и популярен только среди его ярых сторонников, к немалому их огорчению.
Последние несколько лет можно было наблюдать за попытками создать новый вид программных систем, которые как раз и призваны поддерживать "языкоориентированный" стиль программирования. Самая ранняя (и наиболее известная) из них – это Intentional Programming, концепция которого была разработана Чарльзом Симони (Charles Simonyi) еще в Microsoft. Но в этой области работают и другие исследователи, и вот как раз их деятельность вызвала новую волну интереса к данной области.
Теперь я хотел бы определиться с терминологией, которую буду использовать далее по тексту. Как всегда в новой области программирования, устоявшейся терминологии просто нет, поэтому не думайте, что эти слова можно встретить еще где-то за рамками моих работ. Здесь я дам лишь краткое описание новых терминов, но буду объяснять их более подробно дальше, по ходу статьи, так что ничего страшного, если вы не сразу поймете, что я имею в виду.
В этой статье всего два новых базовых термина: "языкоориентированное программирование" (Language Oriented Programming) и "языковой инструментарий" (Language Workbench). Языкоориентированное программирование – это общее название для стиля разработки программного обеспечения, который строится вокруг использования ряда языков, специфичных для данной предметной области. Языковой инструментарий – это общий термин для всех видов приложений, разработанных для поддержки языкоориентированного программирования. Иными словами, языковой инструментарий дает возможность заниматься каким-то одним видом языкоориентированного программирования. Возможно, вам незнаком термин "язык предметной области" (Domain Specific Language), чаще передаваемый аббревиатурой DSL. Это урезанная форма языка программирования, созданная специально для решения определенного вида проблем. В некоторых сообществах программистов под DSL принято понимать только языки, создаваемые для решения конкретной задачи, но я предпочитаю использовать термин DSL для описания языков, которые могут использоваться для решения некоторого ограниченного класса проблем.
Хотелось бы кратко описать ситуацию, сложившуюся в настоящий момент в сфере языкоориентированного программирования, показать на примере, что это такое, а также рассказать о всевозможных течениях, которые существуют в этой области, а также спорах и аргументах "за" и "против". Конечно, если вы уже наслышаны о языкоориентированном программировании, вам захочется пропустить эту часть. Однако я уже убедился, что много (можно даже сказать, абсолютное большинство) программистов не так уж хорошо в этом ориентируются. Давайте же разберемся сначала с общей концепцией, а потом перейдем к тому, что такое языковой инструментарий, и как существующие его разновидности могут изменить отношение к языкоориентированному программированию в целом.
Пока я писал, выяснилось, что для одной статьи материала слишком много. Пришлось выделить некоторые части в отдельные небольшие статейки. Далее в тексте я буду указывать, когда стоит прерваться и переключиться на дополнительную статью. Ссылки на них вы найдете в тексте статьи. Обратите особое внимание на "Пример использования MPS" (http://martinfowler.com//articles/mpsAgree.html) – там я показываю, как создать DSL с помощью одного из существующих языковых инструментариев. Мне кажется, это лучший способ почувствовать, что будут представлять собой подобные приложения в будущем. Впрочем, сначала вам нужно обратиться к общему описанию, иначе от конкретных примеров будет мало толку.
Простейший пример языкоориентированного программирования
Начну с самого простого примера языкоориентированного программирования и типичной ситуации, когда оно может понадобиться. Представьте, что нужна система, которая считывает файлы и создает на их основе некие объекты. В каждой строке файла хранятся данные для создания одного объекта. Эти объекты могут принадлежать разным классам, соответствующий класс обозначается четырехзначным кодом в начале строки. Далее в строке идут данные для полей класса, причем поля у разных классов могут быть разными. Поля определяются скорее своей позицией, нежели разделителями. Так, идентификатор клиента может располагаться между 4-ым и 8-ым символом записи.
Точки здесь обозначают какие-то ненужные и неинтересные данные. Закомментированная строка сверху показывает расположение символов. Первые четыре символа обозначают тип данных – SVCL – Service Call, USGE - Usage. Символы с 5-ого по 18 после SVCL указывают имя клиента.
Возможно, вы захотите писать свой собственный код каждый раз, когда эти записи нужно будет превратить в объекты. Впрочем, я думаю, уже нескольких таких упражнений будет достаточно, чтобы упростить задачу, написав один класс – Reader, который можно будет параметризировать информацией о полях считываемого класса.
У меня для этого существует очень простой класс. Он может быть параметризован коллекцией классов-стратегий для считывания объектов определенного типа. Для данного примера понадобится всего две стратегии – одна для Service Call, другая – для Usage. Стратегии я сохраняю в ассоциативном массиве (map), ключом для которого служит строковый код.
Вот код для обработки файла:
class Reader...
public IList Process(StreamReader input)
{
IList result = new ArrayList();
string line;
while ((line = input.ReadLine()) != null)
ProcessLine(line, result);
return result;
}
privatevoid ProcessLine(string line, IList result)
{
if (isBlank(line))
return;
if (isComment(line))
return;
string typeCode = GetTypeCode(line);
IReaderStrategy strategy = (IReaderStrategy)_strategies[typeCode];
if (null == strategy)
thrownew Exception("Unable to find strategy");
result.Add(strategy.Process(line));
}
privatestaticbool isComment(string line)
{
return line[0] == '#';
}
privatestaticbool isBlank(string line)
{
return line == "";
}
privatestring GetTypeCode(string line)
{
return line.Substring(0,4);
}
IDictionary _strategies = new Hashtable();
publicvoid AddStrategy(IReaderStrategy arg)
{
_strategies[arg.Code] = arg;
}
Он просто построчно считывает файл, причем для каждой строки сначала определяется, какая стратегия должна быть использована, а потом строка отдается этой стратегии на обработку. Чтобы Reader сделал свою работу, необходимо создать новый объект этого класса, добавить в него необходимое количество стратегий, и дать ему на вход файлы с данными.
Стратегии тоже можно параметризовать. На самом деле, нужен всего один класс-стратегия. При создании объектов этого класса ему можно передавать соответствующий код, класс для создаваемых объектов (целевой класс) и детальную информацию о том, какие позиции в строке соответствуют полям целевого класса. Информация о полях сохраняется в списке экстракторов, каждый из которых умеет извлекать значение поля целевого класса из соответствующей позиции.
class ReaderStrategy...
privatestring _code;
private Type _target;
private IList extractors = new ArrayList();
public ReaderStrategy(string code, Type target)
{
_code = code;
this._target = target;
}
publicstring Code
{
get { return _code; }
}
Экстракторы полей можно добавить в стратегию уже после ее создания.
class ReaderStrategy...
publicvoid AddFieldExtractor(int begin, int end, string target)
{
if (!targetPropertyNames().Contains(target))
thrownew NoFieldInTargetException(target, _target.FullName);
extractors.Add(new FieldExtractor(begin, end, target));
}
private IList targetPropertyNames()
{
IList result = new ArrayList();
foreach (PropertyInfo p in _target.GetProperties())
result.Add(p.Name);
return result;
}
При обработке строки стратегия создает целевой класс и использует список экстракторов для заполнения его полей.
class ReaderStrategy...
publicobject Process(string line)
{
object result = Activator.CreateInstance(_target);
foreach (FieldExtractor ex in extractors)
ex.extractField(line, result);
return result;
}
Экстракторы, в свою очередь, берут значения из соответствующей позиции в строке и проставляют их в поле созданного целевого объекта с помощью механизма reflection.
Пока что для решения нашей задачи я описал очень простую библиотечку. В сущности, я построил некую абстракцию, которую могу использовать для решения вполне конкретных задач. Для использования этой абстракции я должен создать ряд стратегий и указать их в Reader. Вот два примера того, как это может быть сделано.
Посмотрим на эти два различных стиля кодирования. Классы Reader и ReaderStrategy описывают абстракции, в то время как последний фрагмент кода – чистой воды конфигурация. При создании подобных библиотек очень часто бывает удобно думать в этих двух плоскостях – абстракция и конфигурация. Абстракция может представлять собой библиотеку классов, фреймворк для разработки, или просто набор вызовов функций. Абстракцию можно легко использовать в нескольких проектах, хотя часто такой необходимости и не возникает. С другой стороны, код конфигурации специфичен для проекта, довольно прост и прямолинеен.
Так как конфигурация довольно проста и, скорее всего, будет меняться чаще, чем абстракция, ее отделяют еще дальше. В нашем примере ее можно вообще вычленить из C#-кода и перенести в XML-файл (сейчас это модно).
<ReaderConfiguration>
<Mapping Code = "SVCL" TargetClass = "dsl.ServiceCall">
<Field name = "CustomerName" start = "4" end = "18"/>
<Field name = "CustomerID" start = "19" end = "23"/>
<Field name = "CallTypeCode" start = "24" end = "27"/>
<Field name = "DateOfCallString" start = "28" end = "35"/>
</Mapping>
<Mapping Code = "USGE" TargetClass = "dsl.Usage">
<Field name = "CustomerID" start = "4" end = "8"/>
<Field name = "CustomerName" start = "9" end = "22"/>
<Field name = "Cycle" start = "30" end = "30"/>
<Field name = "ReadDate" start = "31" end = "36"/>
</Mapping>
</ReaderConfiguration>
XML – очень полезная вещь, но его не очень легко читать. Легче было бы показать, что имется в виду, с помощью собственного синтаксиса. Например, вот так:
Теперь, когда вы уже знакомы с сутью стоящей перед нами задачи, разобраться в синтаксисе вы можете и без моей помощи.
Как видите, в результате получился очень маленький язык программирования, пригодный (исключительно) для отображения полей фиксированной длины на классы. Это классический пример традиционных 'малых языков' UNIX (http://martinfowler.com//articles/languageWorkbench.html#unixLittleLanguage). Для данной задачи это и будет язык предметной области, то есть DSL.
Этот язык хорошо демонстрирует сразу несколько характерных для DSL-языков черт. Во-первых, его можно использовать лишь для очень ограниченного числа задач, ведь он умеет только отображать некие записи фиксированной длины на классы. В результате этот DSL получился очень простым – в нем нет никаких управляющих структур или чего-то подобного. Он даже не является полным по Тьюрингу. Вы не сможете написать целое приложение на этом языке – все, что он позволяет, это описать малюсенький аспект целого приложения. Соответственно, чтобы сделать хоть какую-то законченную работу, этот DSL должен быть объединен с другими языками. И тем не менее, простота языка означает простоту его редактирования и транслирования (ниже я более подробно рассмотрю различные "за" и "против" DSL)
Посмотрим теперь на XML-вариант. Является ли он DSL? Я бы сказал, что да. Он использует XML в качестве синтаксиса, но по-прежнему остается DSL и во многом разделяет свойства языка из предыдущего примера.
Сейчас самый подходящий момент дать понятие разграничения, с которым всегда сталкиваешься, когда говоришь о языках программирования: а именно различие между абстрактным и конкретным синтаксисами. Конкретный синтаксис языка – это синтаксис, который мы видим, когда смотрим на код. Конфигурации, выраженные через XML и через наш собственный формат файлов, имеют различные конкретные синтаксисы. Однако и тот, и другой используют сходную структуру – существует ряд отображений, для каждого из которых заданы строковый код, имя целевого класса и набор полей. Эта базовая структура является абстрактным синтаксисом. Когда разработчики размышляют над синтаксисом языка программирования, они, в большинстве случаев, не делают такого разграничения. И тем не менее, оно играет большую роль при использовании DSL. Об этом можно думать двояко: либо у вас есть один язык с двумя конкретными синтаксисами, либо два языка с одним и тем же абстрактным синтаксисом.
Таким образом, этот пример приводит к интересному вопросу проектирования: что лучше - собственный конкретный синтаксис для DSL или конкретный синтаксис XML? Возможно, синтаксис XML легче читать программно, поскольку для XML существует множество библиотек и инструментов. С другой стороны, приведенный выше синтаксис проще. Готов поспорить, что его гораздо легче прочитать глазами (по крайней мере, в данном случае). Но как бы там ни было, наш случай не может изменить общее соотношение "за" и "против" DSL. Да и вообще, вы всегда можете смело утверждать, что любой конфигурационный XML-файл на самом деле является DSL.
Давайте сделаем шаг назад и обратимся к конфигурационному коду на C#. DSL это или нет?
mapping('SVCL', ServiceCall) do
extract 4..18, 'customer_name'
extract 19..23, 'customer_ID'
extract 24..27, 'call_type_code'
extract 28..35, 'date_of_call_string'
end
mapping('USGE', Usage) do
extract 9..22, 'customer_name'
extract 4..8, 'customer_ID'
extract 30..30, 'cycle'
extract 31..36, 'read_date'
end
Этот кусок кода похож на код на C#. Те, кто знает о моих предпочтениях в языках программирования, могут предположить, что последний пример – это код на Ruby. На самом же деле это точный "моральный эквивалент" примера на C#. Он куда больше похож на DSL благодаря различным особенностям Ruby: ненавязчивому синтаксису, использованию специальных конструкций для выражения диапазонов литералов и гибкостью в runtime-вычислениях. Это полный конфигурационный файл, который может быть считан и обработан в области видимости экземпляра объекта в runtime-е. Но это по-прежнему чистый Ruby-код, который взаимодействует с кодом фреймворка через вызовы методов mapping и extract, соответствующих AddStrategy и AddFieldExtractor в примере на C#.
Я бы сказал, что оба примера – и на C#, и на Ruby – представляют собой DSL. В обоих случаях используется подмножество возможностей основного языка и реализуются идеи, которые выражаются через XML или специальный синтаксис. По сути, DSL внедряется в основной язык, используя его подмножество как особый синтаксис для абстрактного языка. В общем-то, это скорее вопрос отношения к проблеме, чем что-либо другое. Я же решил смотреть на код C# и Ruby через призму языкоориентированного программирования. Кстати, у этой точки зрения глубокие корни – именно так Lisp-программисты создают DSL внутри этого языка. Конечно, то, что волнует авторов таких внутренних DSL, будет отличаться от того, что волнует программистов, пишущих внешние DSL. И тем не менее, общего между ними довольно много (позже я рассмотрю этот вопрос подробнее).
Теперь, когда я привел пример DSL, мне будет проще дать определение языкоориентированному программированию. Языкоориентированное программирование описывает разрабатываемые системы при помощи всевозможных DSL. В системе, где лишь малая часть функциональности написана на DSL, языкоориентированного программирования мало. А там где на DSL написана большая часть функциональности, языкоориентированного программирования много. Сложно понять, много или мало языкоориентированного программирования у вас в системе, особенно если вы используете внутренние DSL. И здесь, как и в случае с любым другим повторно используемым кодом, вы можете написать DSL сами, или же взять какие-нибудь чужие.
Традиции языкоориентированного программирования
Как видите, языкоориентированное программирование – вещь далеко не новая, и программисты уже давным-давно используют его в работе. Давайте же обратимся к текущему положению дел в этой отрасли, а потом уже посмотрим, какие изменения в картину внесут языковые инструментарии.
На сегодняшний день существует несколько стилей языкоориентированного программирования, и мне кажется, сейчас следует вкратце описать некоторые из них.
"Малые языки" Unix
"Малые языки" UNIX являются наиболее очевидными представителями мира DSL. Эти языки представляют собой внешние DSL-системы, которые, как правило, используют для трансляции встроенные инструменты Unix. В бытность мою студентом, я нередко забавлялся с lex и yacc (инструменты такого рода являются стандартными программами Unix). С их помощью гораздо легче писать парсеры и генерировать код (зачастую на C) для малых языков. Awk – еще один пример такого мини-языка.
Lisp
Lisp представляет собой, пожалуй, самый яркий пример существования различных DSL прямо в самом языке. Символьная обработка включена и в название, и в повседневную работу "лисперов". Этому способствуют минималистический синтаксис Lisp, его замыкания (closures) и макросы (программисты часто при упоминании макросов представляют себе макросы в стиле С/C++; макросы в Lisp не имеют к ним практически никакого отношения – они функционируют на синтаксическом уровне и являются средством метапрограммирования, в С/C++ их можно сравнить с метапрограммированием на шаблонах, но макросы Lisp более мощные и гибкие – прим. ред.). Все это является отличной закваской для создания DSL. Пол Грэхем много пишет об этом стиле программирования (http://www.paulgraham.com/progbot.html). Похожие традиции разработки давно существуют и в языке Smalltalk.
Активные модели данных
Программисты, создающие сложные модели данных, могут продемонстрировать, как регулярно меняющиеся части системы могут быть закодированы с помощью информации в таблицах базы данных (их еще называют "таблицами с метаданными", а программы – "программами, управляемые таблицами"). В самой программе эти данные определенным образом интерпретируются и определеют поведение системы.
На самом деле в этом случае мы имеем дело с DSL, конкретный синтаксис которого содержится в таблицах базы данных. Довольно часто содержимое этих таблиц редактируется через GUI. Как правило, люди, которые с этим работают, даже не задумываются о создании какого-либо языка, а сложность работы с реляционным конкретным синтаксисом не позволяет таким языкам чрезмерно разрастаться и терять первичную направленность.
Адаптивные объектные модели
Поговорите с матерыми ООП-программистами, и они поведают вам о созданных ими системах, которые построены на основе компоновки различных объектов в гибком и мощном программном окружении. Такие системы строятся для сложных моделей предметной области, когда большая часть поведения системы определяется набором объектов, объединенных общей конфигурацией. Такой механизм позволяет строить различные сложные системы сходным образом. Сторонники OO-подхода используют адаптивные объектные модели (www.adaptiveobjectmodel.com) как адаптивные модели данных "на стероидах".
Эти адаптивные модели являются встроенными в язык DSL. Опыт показывает, что после того, как модель "устаканилась", разработчики, умеющие работать с адаптивными моделями, могут существенно увеличить производительность труда. Минус этого подхода в том, что новому человеку будет очень сложно разобраться в такой модели.
Конфигурационные файлы XML
Никто не возразит, когда вы заметите, что в любом современном Java-проекте меньше Java, чем XML. Крупные системы задействуют сразу несколько программных каркасов, большинство из которых используют для конфигурации XML-файлы. По сути, эти файлы представляют собой DSL. XML-файлы легко читаются программно, хотя человеку может оказаться куда проще прочитать файлы в специально созданном формате. Для тех, кому угловые скобки режут глаз, разработчики даже пишут специальные IDE-плагины для работы с XML-файлами.
Инструменты для построения пользовательских интерфейсов (GUI builders)
Вместе с появление графических пользовательских интерфейсов появились инструменты, позволяющие создавать такие интерфейсы путем перетаскивания элементов управления. Visual Basic, наверное, самый известный из таких инструментов, хотя я пользовался похожими программами для символьных терминалов задолго до того, как в моду вошли графические интерфейсы. Такие программы либо сохраняют информацию о расположении элементов управления в собственном формате и генерируют пользовательский интерфейс во время выполнения программы на основе этой информации, либо пытаются заложить всю требуемую информацию в сгенерированный код. Хотя внешне такой стиль работы с графическим интерфейсом выглядит весьма заманчиво (особенно, если посмотреть рекламные демо-ролики), у него есть определенные ограничения. Причем ограничения эти настолько существенны, что многие опытные разработчики интерфейсов предпочитают вообще не пользоваться такими инструментами для создания мало-мальски сложных приложений.
Инструменты для построения пользовательских интерфейсов представляют собой разновидность DSL, однако здесь редактирование кода существенно отличается от редактирования кода в текстовых программных языках, к которым мы так привыкли. Даже сами их разработчики часто не рассматривают созданные им приложения для построения интерфейсов как языки программирования. Некоторые считают, что в этом и состоит основная проблема всех подобных инструментов.
Языкоориентированное программирование: за и против
Итак, мы видим, что существующие виды и формы языкоориентированного программирования довольно популярны. Мне кажется, что описывая этот вид программирования в целом, будет удобно разделить все его разновидности на две основные категории: внешние и внутренние DSL. Внешние DSL пишут не на том языке, на котором написано все приложение, а на каком-то другом, после чего такой DSL трансформируется в приложение с помощью компилятора или интерпретатора. К таким DSL относятся "малые языки" Unix, активные модели данных, конфигурационные XML-файлы. Что касается внутренних DSL, то они превращают в DSL сам основной язык приложения. Лучшим примером такого языка служит Lisp.
Термины "внешний DSL" и "внутренний DSL" были придуманы специально для этой статьи. Дело в том, что мне так и не удалось найти в существующей литературе подходящую пару терминов, которые бы хорошо описывали эту разницу в DSL. Внутренние DSL иногда называют "встроенными" (embedded), но я бы не рекомендовал использовать этот термин, потому что его можно отнести к языкам, встроенным в приложение (например, встроенный в Word язык VBA, который можно посчитать разве что внешним DSL). Однако если вы обратитесь к другим источникам, то наверняка встретите термин "встроенный DSL".
Плюсы и минусы внутренних и внешних DSL настолько отличаются друг от друга, что лучше рассмотреть каждый вид этих языков отдельно.
Внешние DSL
Внешними я называю те DSL, которые написаны на языке, отличном от основного языка программного приложения. Примерами DSL такого типа могут служить "малые языки" Unix и конфигурационные XML файлы.
Самый большой плюс внешних DSL состоит в том, что их можно писать так, как вам вздумается. Иначе говоря, вы можете выразить предметную область в самой простой и доступной для чтения и редактирования форме. Формат такого DSL будет ограничен лишь вашим умением создать транслятор, который сможет зачитать конфигурационный файл и выдать некий выполняемый код – как правило, уже на основном языке приложения.
Отсюда же следует и очевидный недостаток внешних DSL – вам придется писать этот самый транслятор. Если язык несложен, как в том примере, что я привел выше, это будет совсем нетрудно. Более сложный язык потребует больших усилий, но с этим тоже можно справиться. Существуют ведь и генераторы лексических анализаторов, и другие инструменты для создания компиляторов, которые облегчают работу со сложными языками. К тому же, в самих DSL заложена идея простоты и читабельности. Так, XML ограничивает форму DSL, но при этом делает его очень удобным для чтения.
Еще один существенный недостаток внешних DSL состоит в том, что у них нет того, что я называю "символической интеграцией". То есть, на самом деле, DSL никак не связан с основным языком приложения. Программная среда разработки базового языка, на котором пишется приложение, ничего не знает о нашем новом DSL. Сейчас, когда программные среды разработки становятся все более изощренными, эта проблема стоит довольно остро.
К примеру, захотелось нам переименовать свойства целевого класса в том примере, который я уже приводил выше. Во всех современных средах разработки автоматическим переименованием уже никого не удивишь. Однако это переименование не будет работать в коде DSL. Это и есть тот самый "символический барьер" между миром C# и DSL для отображения файлов. Такое отображение можно транслировать в С#, но этот барьер не позволяет манипулировать программой как единым целым.
Недостаток интеграции будет сказываться постоянно. Во-первых, где писать код на DSL? Конечно, можно обойтись и простым текстовым редактором, но после современных сред разработки такие редакторы выглядят слишком уж примитивно. Мне же нужен всплывающий список всех имен полей, да еще чтобы работало автодополнение слов (completion). Я хочу, чтобы перекрывающиеся интервалы для различных полей были подчеркнуты красной волнистой линией, обозначая ошибку. Однако для этого мне понадобится такой редактор, который понимал бы семантику моего DSL.
Ну хорошо, я могу прожить и без редактора, который понимает семантику языка. А как быть с отладкой? Мой отладчик сможет работать с C#-кодом, полученным для моего DSL, но он не сможет работать с исходным кодом самого DSL. Было бы здорово, чтобы иметь собственную полнофункциональную среду разработки для моего DSL! Ведь те дни, когда код писали в простых текстовых редакторах и пользовались простыми отладчиками, уже канули в Лету. Теперь мы живем в эру post-IntelliJ (см. врезку), и все изменилось.
Чаще всего против использования внешних DSL выдвигают обвинение в "языковой какофонии". Суть его в следующем: программные языки довольно сложно освоить, поэтому задействовать сразу несколько языков в одной программе – значит, чрезмерно усложнить ее. На самом деле это просто небольшое недоразумение, которое проистекает из непонимания сути DSL. Те, кто говорит о "языковой какофонии", представляют себе мешанину из программных языков общего назначения – картину, действительно, жуткую. Однако DSL куда ограниченнее и проще, чем языки общего назначения. К тому же они тесно связаны с предметной областью, и изучать их гораздо легче.
По сути, в каждой солидной программе вы сталкиваетесь с большим количеством абстракций, которыми необходимо манипулировать. Вспомните хотя бы процесс чтения файла из первого примера. Как правило, с такими абстракциями работают, используя объекты и методы. Этого достаточно, хотя при этом все приходится выражать с помощью довольно ограниченной грамматики (степень этой ограниченности зависит от используемого языка). Внешние DSL дают шанс создать такую грамматику, манипулировать которой будет проще и удобнее. Вопрос только в том, стоит ли такое удобство создания новой DSL, или нет.
Многие говорят о том, что создавать DSL сложно. Проектирование новых программных языков – вещь непростая, а писать несколько языков для каждого проекта будет просто непосильной тяжестью. Опять-таки, это обвинение коренится в том же недопонимании сути DSL, в том что они коренным образом отличаются от программных языков общего назначения. Самая сложная часть задачи, как мне кажется - построить DSL на хорошей абстракции. Это самое главное. А дальше я не вижу большой разницы между проектированием DSL и проектированием API. Не думаю, что создавать DSL намного сложнее, чем спроектировать хороший API.
Многие считают, что самый большой плюс внешних DSL состоит в том, что они вычисляются во время выполнения. Это дает возможность поменять часто изменяющиеся параметры без повторной компиляции программы. Именно поэтому конфигурационные XML-файлы так популярны в мире Java. Впрочем не стоит забывать, что это верно только для статически компилируемых языков. Существует целый ряд языков, код которых может быть проинтерпретирован во время выполнения, так что для них это не плюс. Кроме того, растет интерес к смешению компилируемых и интерпретируемых языков, например, IronPython в .NET. Это позволяет выполнить внутренний DSL IronPython прямо в контексте системы, написанной на C#. Те, кто работают с Unix, часто смешивают С и С++ с различными языками сценариев.
Внутренние DSL
Плюсы и минусы внутренних DSL являются зеркальным отражением внешних. Здесь уже нет символьного барьера. Можно в полную силу пользоваться возможностями основного языка приложения и при этом задействовать все инструменты, которые есть для этого языка. В качестве примера внутренних DSL можно назвать Lisp и адаптивные объектные модели.
Но здесь мы сталкиваемся с довольно серьезной проблемой, которая состоит в существенных различиях между основными "языками с фигурными скобками" (C, C++, Java, C#) и языками типа Lisp, которые действительно хорошо подходят для создания внутренних DSL. Стиль внутренних DSL гораздо более приемлем в Lisp или Smalltalk, чем в Java или C# - и действительно, сторонники динамических языков часто указывают на это как на одно из основных их преимуществ. Сейчас мы наблюдаем, как это происходит с некоторыми сценарными языками - в качестве примера можно привести мета-программирование в Ruby (http://poignantguide.net/ruby/chapter-6.html) и его использование в Ruby On Rails (http://www.rubyonrails.org/).
Внутренние DSL ограничены синтаксисом и структурой основного языка приложения. Чем более динамичен язык, тем меньше он страдает от этого ограничения. Такие языки обладают минималистским синтаксисом (Lisp, Smalltalk, языки сценариев), и это делает их хорошей основой для DSL, в отличие от "языков с фигурными скобками". Вы уже имели возможность в этом убедиться, сравнив примеры на C# и Ruby. Большую роль при создании внутренних DSL играют замыкания (closures) и макросы. В C-подобных языках большая часть подобных механизмов отсутствует, но у них есть другие возможности для создания внутренних DSL. Одна из них – аннотации (атрибуты в C#).
Несмотря на то, что у вас есть весь необходимый инструментарий для программирования на основном языке приложения, сам основной язык ничего не знает о вашем DSL. Следовательно, поддержка DSL инструментами программирования будет ограниченной. Конечно, это лучше, чем писать код в простом текстовом редакторе, но совсем не так хорошо, как хотелось бы.
Возможность предоставить DSL всю мощь основного языка программирования – палка о двух концах. Если вы свободно владеете базовым языком, все хорошо. Однако сильная сторона DSL как раз в том и состоит, чтобы программировать, не зная всех возможностей базового языка. Это и позволяет непрофессиональным программистам вводить данные предметной области непосредственно в систему. Внутренний DSL может усложнить этот процесс, ведь существует масса мест, где пользователь может зайти в тупик из-за недостаточной осведомленности о возможностях базового языка.
Можно посмотреть на это и с такой точки зрения: языки общего назначения предлагают множество языковых конструкций и возможностей. Ваш DSL использует только часть этих возможностей. Когда инструментов больше, чем нужно, это только замедляет работу – ведь придется разбираться в них, чтобы выбрать нужные. В идеале хочется иметь только то, что нужно для выполнения работы, ну разве чуточку больше. (Чарльз Симони обсуждает эту идею, используя нотацию степеней свободы, http://blog.intentionalsoftware.com/intentional_software/2005/05/notations_and_p.html)).
Здесь наблюдается полная аналогия с офисными программами. Многие жалуются, что современные текстовые редакторы очень сложно использовать, так как в них сотни возможностей, гораздо больше, чем необходимо среднему пользователю. Но ведь каждая из этих возможностей кому-то да нужна, поэтому в программу запихнули все! Это удовлетворяет потребности всех пользователей (правда, в результате сама программа распухает неимоверно). В качестве альтернативы можно было бы иметь несколько небольших программ, каждая из которых решала бы какую-то конкретную задачу. Такие программы было бы гораздо легче изучать и использовать. Проблема, конечно, состоит и в том, что разработать такие специализированные офисные программы будет очень дорого. Эта ситуация очень напоминает компромисс между внутренними DSL в языках программирования общего назначения и внешними DSL.
Внутренние DSL очень близки к языкам программирования, поэтому с их помощью будет сложно выразить нечто, для чего в языке программирования нет соответствующего механизма. Например, в корпоративных приложениях часто возникает понятие слоя (layer). По большей части слои можно определить с помощью пакетов в языке программирования. Однако через пакеты нельзя задать зависимости между слоями. То есть весь интерфейсный код можно разместить в пакете MyApp.Presentation, а бизнес-логику в MyApp.Domain, но вы не сможете через внутренний DSL задать такое ограничение, чтобы классы из MyApp.Domain не ссылались на классы из MyApp.Presentation. До какой-то степени это еще раз иллюстрирует ограниченность динамизма в общеупотребительных языках программирования – ибо подобные вещи были возможны в Smalltalk, где программист имел больший доступ к метаинформации.
(Для сравнения можно взглянуть на более сложный пример, который я писал на одном из таких динамических языков (http://martinfowler.com//articles/mpsAgree.html). Вряд ли я буду возвращаться к этому примеру, но если кто-то это сделает, то я обновлю раздел "Дополнительное чтение".)
И для не-программистов
Одна из тем, постоянно всплывающих в рассуждениях о языкоориентированном программировании - возможность создания кода непрофессионалами. Всевозможные эксперты в различных предметных областях могли бы программировать, используя соответствующие DSL. Впрочем, подобная цель стоит перед программированием уже давно. Многие были когда-то уверены, что ранние языки высокого уровня (Cobol, Fortran) положат конец профессии программиста, потому что пользователи смогут программировать на них сами. А мне кажется, что это просто "синдром Cobol", и все те технологии, которые якобы должны свести на нет профессиональное программирование, ни к чему подобному не приведут.
Независимо от "синдрома COBOL-а", порой действительно удается сделать так, чтобы пользователи вносили существенный вклад в написание программ. Вот один из способов: выделить некую часть проблемы (не очень сложную и имеющую четкие границы) и позволить пользователям программировать именно в этой части. Впоследствии такие области можно превратить в DSL. Кстати, подобные DSL могут быть весьма сложными – возьмите, к примеру, MatLab. Это довольно сложный DSL, выживающий именно потому, что он жестко сфокусирован на своей предметной области.
Преимущество внешнего DSL для использования непрофессионалами состоит в том, что можно смело отказаться от всех сложностей базового языка приложения, и создать DSL, который будет понятен и удобен пользователям. Это особенно важно для языков с ограничивающим синтаксисом. Однако даже если вы имеете дело с простыми языками, внутренние DSL будут менее удобны: пользователь может сделать то, что кажется логичным с точки зрения языка, но будет выходить за рамки DSL. В результате он получит странное поведение программы или таинственные сообщения об ошибках, что легко вгонит его в ступор.
Многие адепты языкоориентированного программирования описывают, как в скором будущем вся предметная логика системы будет создаваться пользователями, а программисты будут лишь писать для них необходимые инструменты поддержки, позволяющие компилировать такие программы. Конечно, это не означает конца профессии "программист", однако едва ли при таком раскладе их понадобится много (ведь эти самые инструменты поддержки можно будет использовать повторно). Кроме того, при таком сценарии исчезнут все проблемы взаимодействия между программистами и заказчиками, которые так осложняют процесс программирования в наши дни. Красивая идея, ничего не скажешь. И все же это очень напоминает "синдром Cobol".
Конечно, подключение непрофессионалов к программированию – весьма ценная вещь, но я не думаю, что это самый веский аргумент в пользу языкоориентированного программирования. Хороший DSL позволяет работать более продуктивно и профессиональному программисту, даже если этим DSL не смогут пользоваться непрофессионалы. Возможно, хороший DSL должен изначально писать профессиональный программист, а уже потом его будут уточнять и пересматривать эксперты в предметной области.
Использование труда непрофессиональных программистов – рискованная ставка, но и выигрыш тут большой. Я ни за что не поверю в разговоры о том, что новую технологию подхватит огромное число пользователей и тут же начнет писать программы не хуже профессиональных программистов. Но если бы это все же удалось, то выгоду от внедрения такой технологии трудно было бы переоценить. И дело вовсе не в том, что профессиональных программистов станет меньше (или не будет вовсе). Дело в том, что можно было бы исправить то ужасное состояние дел, которое наблюдается сейчас в области взаимодействия программистов и экспертов в предметных областях. А это, по моему мнению, является камнем преткновения для успешной работы над проектами.
Подведем итоги
С моей точки зрения, самое большое достоинство языкоориентированного программирования – это возможность использования DSL, а недостаток – необходимость создавать средства для их поддержки. Если писать внутренние DSL, то уменьшится необходимость в средствах поддержки. Однако вместе с этим уменьшатся и возможности самого DSL – на него будут наложены ограничения, связанные с базовым языком (особенно если вы пишете на C-подобных языках). Внешние DSL не ограничивают ваши возможности, однако требуют усилий по проектированию самого языка, созданию транслятора, а также некоего инструментария, который будет помогать вам программировать.
Именно поэтому языкоориентированное программирование так медленно распространяется: и внешние, и внутренние DSL имеют весьма ощутимые недостатки. Вот в результате мы и мучаемся ощущением того, что с помощью DSL можно работать куда эффективнее, только непонятно, как.
И это естественным образом подводит нас к теме языкового инструментария. Итак, по сути своей, эти инструменты должны предоставить программистам широту возможностей внешних DSL и при этом уничтожить "семантический барьер". Более того, они должны позволять с легкостью создавать вспомогательные инструменты, не уступающие современным средам разработки. В результате языкоориентированное программирование станет доступным для тех, кого до сих пор отпугивали связанные с ним неудобства.
Составляющие языкового инструментария
Несмотря на некоторые существенные отличия, у всех вышеперечисленных приложений есть много общего.
Одной из сильных сторон языковых инструментариев является то, как они изменяют соотношение между редактированием и компиляцией программы. По сути, они дают возможность редактировать не текст программы, а некое абстрактное ее представление. Давайте остановимся на этом чуть-чуть подробнее.
В обычном программировании мы редактируем текст программы с помощью текстового редактора. После этого мы при помощи транслятора делаем исходный код исполняемым, то есть превращаем текст в то, что компьютер сможет понять и исполнить. Трансляция может происходить во время выполнения, как, например, в скриптовых языках (Python, Ruby), или же представлять собой отдельный шаг, как в транслируемых языках типа Java, C# и С.
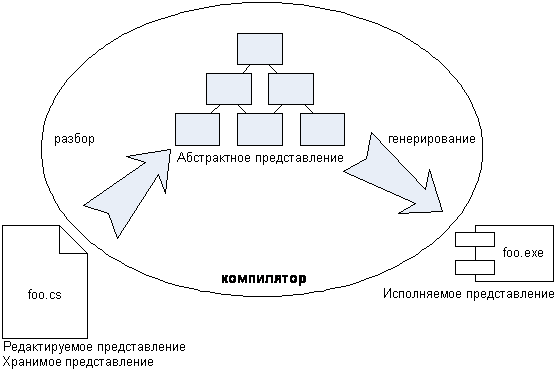
Разобьем этот процесс на составляющие. На рисунке 1 изображен упрощенный процесс компиляции программы. Чтобы файл foo.cs стал исполняемым, надо запустить компилятор. Учитывая контекст нашей беседы, давайте разобьем весь процесс компиляции на два шага. Во время первого на основе текста из файла foo.cs компилятор строит абстрактное синтаксическое дерево (АСТ). Во время второго шага происходит обход этого дерева и формируется CLR байт-код, который затем помещается в скомпонованный файл (exe).
Более подробно о генерации кода из внешнего DSL читайте в статье Generating Code for DSLs (http://martinfowler.com//articles/codeGenDsl.html).
Можно сказать, что существует несколько разных представлений программного приложения, а компилятор осуществляет трансляцию между ними. Файл с исходным кодом представляет собой редактируемое представление программы – именно с ним мы работаем, когда хотим изменить что-то в программе. Кроме того, это также и вид хранения программы, потому что при необходимости мы будем обращаться к исходному коду. Когда мы запускаем компилятор, на первом этапе он создает отображение редактируемого файла в виде абстрактного представления программы (абстрактное синтаксическое дерево), а потом генератор кода превращает его в еще одно представление – исполняемое (CLR байт-код).
(На самом деле потребуется гораздо больше преобразований, чтобы сделать из текстового файла исполняемый. Однако работа компилятора заканчивается с появлением байт-кода, а все что происходит после этого, выходит за рамки нашей темы.)
Абстрактное представление очень недолговечно – оно существует только во время работы компилятора. Используется оно с одной лишь целью – разделить процесс компиляции на два последовательных шага. Разумеется, эта недолговечность является одной из самых серьезных причин, по которым мы не можем добиться символической интеграции между внешними DSL. Каждый из таких языков будет проходить через собственный процесс компиляции, поэтому их абстрактные представления окажутся никак не связанными между собой. Все соединтся лишь на последней стадии – в сгенерированном коде, когда все ключевые абстракции уже утеряны.
Сложные современные среды разработки (IDE), которые появились после IntelliJ IDEA, существенным образом изменили эту модель. Когда среда разработки загружает файл, в ее памяти создается его абстрактное представление, которое помогает редактировать файл. (В языке Smalltalk было нечто похожее.) С помощью абстрактного представления файла мы можем делать такие простые вещи, как автодополнение имени метода, или же такие сложные как рефакторинг (автоматизированный рефакторинг представляет собой трансформацию абстрактной модели).
Один из моих коллег, Мэтт Фёммель, рассказывал, как однажды во время работы в IntelliJ IDEA он с удивлением понял, что, занимаясь рефакторингом, он практически не пишет код, а лишь манипулирует абстрактным представлением программы. Разумеется, после этого IDE отображала эти изменения в тексте программы, но суть от этого не менялась – Мэтт менял не код, а абстрактное представление. Если вам тоже доводилось ощущать нечто подобное во время работы с современной средой разработки, то вы уже представляете, что такое работа с языковым инструментарием.
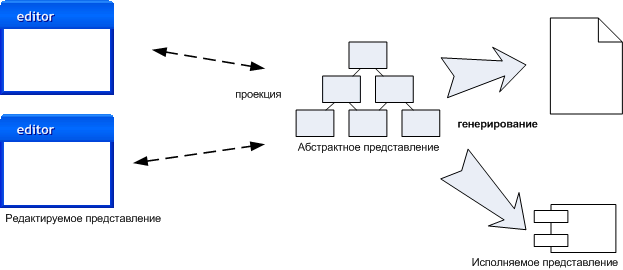
Рисунок. 2: Манипулирование различными представлениями программы с помощью языкового инструментария.
На рисунке 2 изображен тот же процесс, но уже в языковом инструментарии. Самое главное отличие – «исходным» становится уже не редактируемый текстовый файл. Здесь вы изменяете само абстрактное представление программы. Чтобы у вас была возможность редактировать абстрактное представление, оно должно подаваться в каком-нибудь редактируемом виде. И теперь уже редактируемое представление программы будет недолговечным (оно нужно только чтобы облегчить работу). А настоящим «исходником» программы будет постоянно существующее абстрактное ее представление.
Тот факт, что редактируемое представление программы является всего лишь временной проекцией, подводит к нескольким интересным выводам. И возможно, самым важным из них будет то, что редактируемое представление совсем не обязательно должно быть полным и законченным. Если отдельные его составляющие не важны для текущей задачи, то их вообще можно не показывать. Более того, редактируемых представлений может быть несколько, и каждое из них призвано иллюстрировать некоторые аспекты абстрактного представления. А поскольку абстрактная проекция находится внутри языкового инструментария, то редактируемое представление будет гораздо активнее, чем обычный текстовый файл. Таким образом, редактор абстрактной проекции окажется тесно связан с языком программирования, а следовательно во время работы с редактируемыми представлениями вы будете активно думать о том, как преобразовывает их редактор. Возможно, у вас будут возникать гораздо более интересные идеи, чем те, которые вы можете придумать при работе с таким пассивным видом редактируемого материала, как текст.
Языковой инструментарий отделяет представление, в котором хранится код, от его редактируемой ипостаси. Теперь хранение кода осуществляется через сериализацию абстрактной проекции программы. Обычно это делается с помощью XML, однако в данном случае этот XML уже не предназначен для редактирования человеком. Выбор XML для хранения программного кода облегчает взаимодействие приложения с другими системами. Хотя, конечно, достичь такого взаимодействия будет очень и очень непросто.
С генерацией кода происходит похожая ситуация, хотя обычно кодогенераторы рассматривают в качестве исполнимого кода обычные исходники. Исходные файлы, созданные обычными кодогенераторами, по сути не являются исходными, потому что они не предназначены для прямого редактирования. По мере развития языкового инструментария мы будем все больше полагаться на такую генерацию не редактируемых структур, например в байт-код.
Абстрактное представление, с которым мы работаем в языковом инструментарии, должно быть терпимо к ошибкам и всевозможным неточностям. Возможно, это не самая очевидная его характеристика, но тем не менее, одна из наиважнейших. Принято считать, что абстрактное представление программы должно быть абсолютно правильным, что в нее нельзя вносить неточную информацию. Так вот, это предположение приводит к отсутствию юзабилити таких приложений. Те среды разработки, которые пошли по стопам IntelliJ IDEA, прекрасно уяснили это, и теперь весьма элегантно обращаются с ошибками в коде. Например, вы сможете заниматься рефакторингом в приложениях, которые компилируются с ошибками (это – признак высокой юзабилити).
Это еще нужнее в ситуациях, когда вы собираете разнообразную информацию из разных источников. В этом случае вы просто не сможете сделать так, чтобы вся информация постоянно оставалась правильной и непротиворечивой. Следовательно, вы обязательно столкнетесь со сложными и ошибочными ситуациями, в которых будет куда полезнее подсвечивать такой код определенным цветом, а не запрещать ввод ошибочных данных. Кроме того, надо дать возможность вносить в модель неисчисляемые данные, например, документацию. А значит, в результирующем коде вашего DSL может появиться отсканированное изображение салфетки с набросками архитектуры приложения.
Определяем новый DSL
Наметив общие цели и установки языкового инструментария, обратимся теперь к процессу создания новых DSL. Он состоит из трех шагов:
Определить абстрактный синтаксис, который станет схемой абстрактного представления программы.
Выбрать редактор, который позволил бы людям манипулировать абстрактным представлением с помощью некой проекции.
Создать генератор, который будет транслировать абстрактное представление в исполнимое. В действительности генератор определяет семантику DSL.
Разумеется, это только основные пункты, кроме того, в них возможны некоторые вариации. Как я уже говорил ранее, при работе с DSL вполне можно воспользоваться несколькими редакторами и генераторами. У разных людей могут быть разные предпочтения при выборе редактора. Например, в редакторе Intentional можно переключаться между несколькими проекциями одной и той же модели и видеть иерархическую структуру данных как LISP-образные списки, как вложенные блоки или же в виде дерева.
Разные редакторы понадобятся по нескольким причинам. Какие-то из них могут оказаться удобнее для работы с определенными фреймворками, поддерживающими схожую функциональность. Хороший пример такого случая – многочисленные диалекты SQL. Кроме того, различные компромиссы в разработке могут возникать из-за различия в характеристиках производительности или библиотеках. И наконец, может понадобиться генерировать код на разных языках – то есть чтобы ваш DSL мог генерировать код и на Java, и на C#.
Кроме того, может оказаться полезной возможность определять трансляторы для хранения данных. Вполне вероятно, что языковой инструментарий будет по умолчанию создавать какую-то схему хранения данных, которая автоматически осуществит сериализацию абстрактной модели. Тем не менее, может понадобиться несколько альтернативных представлений хранения данных. Например, для того, чтобы поддержать возможность взаимодействия между различными системами, или для передачи данных из одного инструмента в другой. В отличие от генераторов кода, в данном случае общение с таким представлением будет двусторонним.
Дополнительный вид генератора может создавать документацию, которую сможет читать человек (эквивалент javadoc). Разумеется, все взаимодействие с языковым инструментарием должно осуществляться с помощью редактора, однако это не отменяет необходимости создавать документацию – как бумажную, так и электронную.
Более подробно об этом написано в статье A Language Workbench in Action – MPS (http://martinfowler.com//articles/mpsAgree.html). В ней показан пример создания новыого DSL с помощью Meta-Programming System (MPS) компании JetBrains. Это реальный пример работающего языкового инструментария.
Создаем новый языковой инструментарий
На сегодняшний день не существует единого определения того, что же представляет собой языковой инструментарий. Неудивительно, что мне пришлось изобретать столько новых терминов для этой статьи! Меня поражает еще и то, что мне приходится определять здесь и основные характерики языкового инструментария. В противном случае, мы столкнемся с такой же жуткой неразберихой, которая окружает большинство тем, касающихся программирования (например, понятия «компонентов» (components), сервисно-ориентированной архитектуры (Service Oriented Architecture) и т.д.).
Впрочем, теперь, после того, как мы довольно подробно рассмотрели многие вопросы, связанные с языкоориентированным программированием, определить базовые свойства языкового инструментария совсем не трудно:
Пользователи языкового инструментария могут легко создавать новые языки, которые при этом будут взаимно интегрированы.
Главным и основным источником информации является постоянно существующая абстрактная модель приложения.
Новый DSL создается в трех основных составляющих: схема, редактор (редакторы) и генератор (генераторы).
Пользователи нового языка манипулируют им с помощью проекционного редактора.
Языковой инструментарий может работать, даже если абстрактная модель содержит неполную или противоречивую информацию.
Как языковые инструментарии меняют соотношение «за» и «против» в языкоориентированном программировании
Некоторое время назад я говорил о плюсах и минусах языкоориентированного программирования. Языковой инструментарий оказывает непосредственное влияние на соотношение сил в этом вопросе и вносит несколько новых аргументов.
Самый большой плюс языкового инструментария – легкость создания внешних DSL. Теперь не нужно писать парсер. Достаточно определить абстрактный синтаксис – но это обычный этап моделирования данных. К вашим услугам будет мощная среда разработки (IDE). Правда, потребуется некоторое время, чтобы внести нужные установки в ее редактор. Вам все также придется создавать генератор, и мне кажется, что языковый инструментарий не сделает эту задачу проще. Но с другой стороны, написать генератор для хорошего и несложного DSL – задача почти что пустяковая.
Еще одно большое достоинство языкового инструментария состоит в том, что он дает интеграцию на уровне символов. Это же просто здорово – взять похожий на Excel язык формул и просто вставить его в тот язык, который вы сами создали. То же самое можно сказать и о возможности менять символы в одном языке, с тем, чтобы эти изменения прошли через всю систему (языковому инструментарию это вполне по силам, хотя я не уверен, что они уже умеют это на сегодняшний день).
Еще одним важным моментом в использовании языкового инструментария является рефакторинг. Когда я говорю о языковом инструментарии, вы можете представить себе что-то вроде: «Сначала создай DSL, а потом пиши на нем то, что его использует». Если вы знакомы с другими моими работами, то это должно вас насторожить. Да, я большой поклонник эволюционного проектирования, что в данном контексте означает – у вас должна быть возможность одновременно менять и сам язык, и написанный на нем код. Это весьма сложная проблема, и разработчики Intentional с самого начала решили учесть ее. Пока еще нельзя сказать, появится ли в будущих, готовых, версиях языкового инструментария такая возможность, но если нет, то это будет очень большим препятствием к его использованию.
Могу назвать еще одну большую проблему. Это зависимость от поставщика языкового инструментария. Пока не существует никаких стандартов для определения трио «схема, редактор и генератор». Создав язык в каком-либо языковом инструментарии, вы тут же попадаете в зависимость от него. Раз нет никаких стандартных способов обмена данными между разными языковыми инструментария, значит при переходе на другой языковой инструментарий придется создавать заново и схему, и редактор, и генератор. Может быть, с течением времени возникнет некий специальный вид хранения данных – специально для таких случаев. Однако если этого не случится, то риск зависимости от поставщика инструментария будет весьма большим. (Архитектура MDA дает некоторый ответ на эту проблему, но на мой взгляд, он по меньшей мере неполон.)
Эта проблема несколько смягчается, если вы собираетесь использовать языковой инструментарий для генерации исходного кода. Например, если нужно контролировать все конфигурационные XML-файлы Java-приложения. Сгенерированные конфигурационные файлы останутся у вас даже в самом плохом случае, если вы решите отказаться от языкового инструментария. И если вы обращали должное внимание на читабельность сгенерированных файлов, то они будут не хуже, чем написанные вручную, и вы немного потеряете. А для расширения возможностей опять-таки можно сгенерировать хорошо структурированный код на Java. Это в некоторой степени уменьшает риск зависимости от поставщика языкового инструментария (по крайней мере, вам не придется совсем туго). И тем не менее, забывать об этом риске не стоит.
Вопрос выбора инструментария остро встает вследствие ухода от использования текста как носителя исходного кода. Вам придется заново решать различные проблемы, которые уже успешно решались для текстовых файлов. Я имею в виду управление версиями для абстрактных моделей. Мы уже научились делать хорошие инструменты такого рода для текстовых файлов – с возможностью посмотреть разницу в файлах, а затем внести ее в результирующий вариант. Языковой инструментарий должен предлагать такую же функциональность для абстрактных представлений, иначе с ним будет сложно работать. Теоретически, эта проблема, конечно же, решается. Более того, ее решение позволит видеть семантические отличия абстрактных моделей (когда можно явно увидеть, что две модели отличаются переименованным символом, а не догадываться об этом по изменениям в тексте.) Компания Intentional придумала для этого неплохой вариант решения, однако подождем их хвалить, пока не опробуем его в деле.
Но вернемся к положительным сторонам перехода на языковые инструментарии. Прежде всего, та комбинация нового специфического языка программирования и редактора, в котором это можно осуществлять, открывает путь к программированию для непрофессионалов. Более того, интеграция на уровне символов сводит на нет проблему разницы кода, написанного профессионалом и непрофессионалом. Может быть, мощные современные редакторы дадут возможность преодолеть проблему языка COBOL, так как предоставят непрограммистам среду, специально настроенную на нужды их работы.
Да, пожалуй, возможность привлечения к программированию знатоков предметной области – самая захватывающая из всех, связанных с языкоориентированным программированием. Похоже, что когда мы снова и снова говорим о том, что какое-то приложение серьезно увеличивает продуктивность работы программиста, мы пытаемся оптимизировать пустой цикл. В абсолютном большинстве проектов, с которыми мне доводилось сталкиваться, самой большой проблемой было общение между программистами и людьми, для которых они писали программное приложение. Если решить эту проблему, можно достичь больших успехов даже без самых лучших технологий. А если эта проблема стоит остро, то никакой Smalltalk вас не спасет.
Большинство энтузиастов языкоориентированного программирования говорят о привлечении к программированию знатоков предметной области. Я даже слышал о том, что секретарши будут программировать на внутренних DSL, созданных на Lisp. К сожалению, по опыту известно, что подобные утверждения еще ни к чему не приводили. Может быть хоть в этот раз мы сможем наконец сделать это – ведь теперь появилась возможность объединить достоинства специфического для данной предметной области языка и мощного инструментария, в котором этот язык можно редактировать. Если это получится, то выгода от использования языкоориентированного программирования будет неизмерима. Я был просто поражен, когда узнал, насколько важным считают вовлечение в процесс непрограммистов Чарльз Симони и разработчики из Intentional Software, и как это влияет на все принимаемые ими решения.
Впрочем, на сегодняшний день самым большим недостатком подобных инструментов является их незрелость. Пройдет немало времени, прежде чем их начнут использовать хотя бы самые большие охотники до новинок. Впрочем, в нашей отрасли все так быстро меняется – посмотрите, какими инструментами и языками мы пользовались еще десять лет назад, и что у нас есть теперь.
Изменения в нашей концепции DSL
В этой статье я приводил довольно малоинтересные варианты DSL. Их было легче использовать, потому что их просто писать и удобно приводить в пример. Однако даже более сложный DSL для составления соглашений весьма условен – хорошо видно, как его можно представить в виде обычного текстового варианта языка. Многие рассчитывают на появление графических DSL, однако даже это не может продемонстрировать все их возможности. Самую большую опасность представляет сам термин «язык», который может скрыть от людей те возможности, которые скрывает в себе языковой инструментарий.
ПРИМЕЧАНИЕ
См. статью "A Language Workbench in Action – MPS", http://www.martinfowler.com/articles/mpsAgree.html#AgreementDsl
Когда мы с коллегами обсуждали конференцию OOPSLA 2004, больше всего разговоров шло о выступлении Джонатана Эдвардса, который рассказывал о «Примеро-центрическом программировании» (Example Centric Programming). Главным в этой методологии является редактор, который отображает не только программный код, но и результаты выполнения фрагментов этого кода. Суть метода заключается в том, что нам легче думать о конкретных примерах даже тогда, когда мы манипулируем абстрактной моделью. Такая же склонность к примерам привлекает многих и к «Разработке, основанной на тестах» (Test Driven Development). Я думаю, это можно назвать Specification by Example (http://martinfowler.com/bliki/SpecificationByExample.html).
На основе своих идей Эдвардс создал собственное приложение под названием Subtext (http://subtextual.org/). Во многом оно напоминает языковой инструментарий (например, в отказе от текстовых исходных файлов). Subtext менее интересен с точки зрения создания новых языков, однако он дает понимание того, как может меняться мышление программиста с развитием языковых инструментариев, мышление, основанное на том, что язык и инструмент тесно переплетены между собой.
И это именно та причина, которая сможет помочь языкоориентированному программированию преодолеть опасности, погубившие планы разработчиков COBOL. Как я уже говорил выше, мы постоянно пытаемся изобрести технологии, которые позволили бы пользователям выступить в роли программистов. И нам это постоянно не удается. А теперь давайте обратимся к одной технологии, в которой нам удалось достичь этой цели – к электронным таблицам (spreadsheets).
Большинство программистов никогда не назовут работу с электронными таблицами программированием. И тем не менее, пользователи – непрофессиональные программисты – умудряются создать с их помощью весьма сложные системы. Электронные таблицы – это замечательная среда программирования, которая уже показала, какие свойства должны быть у инструмента, предназначенного для непрофессионального программирования:
Незамедлительная обратная связь с пользователем, включая немедленное отображение результатов вычисления.
Глубокая взаимосвязь инструмента и языка программирования.
Отсутствие текстовых исходных файлов.
Отсутствие постоянного отображения всей имеющейся информации – формула выводится только при редактировании ячейки, в которой она содержится. Во всех остальных случаях программа показывает ее значение.
Но в то же самое время электронные таблицы не очень удобны в использовании. Недостаток структуры в них подталкивает пользователя к экспериментам, однако мне кажется, что куда проще было бы просто восполнить этот недостаток, чем заставлять пользователя искать решение в многочисленных экспериментах.
Итак, когда мы говорим о работе с DSL в языковом инструментарии, мы должны думать не столько о тех примерах, которые я здесь приводил, и не о графических языках, которые так любят те, кто занимается моделированием приложений. Лучше представить себе, что языковой инструментарий станет следующим поколением электронных таблиц.
Заключение
Я хотел написать эту статью, чтобы просто познакомить вас с тем, что такое языковой инструментарий. По меньшей мере, я надеюсь, теперь предложение начальства заменить вашу привычную среду программирования на языковой инструментарий уже не поставит вас в тупик.
С моей точки зрения, языковой инструментарий дает два основных преимущества. Во-первых, это большая продуктивность работы, возникающая за счет использования лучших инструментов. Во-вторых, это большая продуктивность работы, которую дает более тесное сотрудничество между программистами и людьми, знающими предметную область. Фактически, это возможность для непрограммистов непосредственно участвовать в разработке приложения. Конечно, понять, насколько реализовались эти преимущества, можно только по прошествии некоторого времени. Сам я думаю, что первое преимущество никуда не денется, программистам будет действительно удобнее работать с языковым инструментарием. Однако оно не окажет глобального влияния на всю программную отрасль. А вот если языковые инструментарии изменят отношения между программистами и экспертами предметной области – вот это уже будет иметь просто ошеломительный эффект. Но для этого языкоориентированному программированию надо учесть и преодолеть уроки COBOL.
И пожалуй, самое интересное – если мы будем использовать языковые инструментарии, то едва ли сможем себе представить, как будут выглядеть DSL будущего. До сих пор мое представление ограничивалось тем, как могут выглядеть текстовые или графические языки. Но при тесном взаимодействии редактора и схемы перед нами откроются такие возможности, какие и в голову не приходят сейчас программистам, пишущим внешние DSL. И если языковой инструментарий оправдает наши надежды, то уже через десять лет мы будем смеяться над тем, как мы представляли себе DSL.
Как я уже говорил, сейчас языковой инструментарий находится на самой ранней стадии развития. И только через несколько лет мы сможем по-настоящему опробовать, на что он способен. Не буду ничего говорить о том, насколько языковой инструментарий изменит всю парадигму программирования, как надеются его фанаты. Из меня вообще неважный предсказатель. Скажу только, что это – одна из самых интересных идей на горизонте современного программирования. И если разработчики языкового инструментария осознают весь потенциал своих приложений, это будет иметь огромный резонанс во всем, что связано с нашей профессией. И даже если этого не случится, я думаю, что их разработки подарят нам немало весьма и весьма интересных идей.
Настоятельно рекомендую вам следить за этой темой. Она интересна сейчас и имеет все шансы оставаться интересной еще много лет. К счастью, за последние несколько месяцев я успел получить хорошее представление о ней и собираюсь продолжать свои изыскания.
Любой из материалов, опубликованных на этом сервере, не может быть воспроизведен в какой бы
то ни было форме и какими бы то ни было средствами без письменного разрешения владельцев авторских
прав.