 |
Технология Клиент-Сервер 2006'1
|
|
|
Сложные структуры объектов, персистентность и db4o
Автор: Рик Греган (Rick Grehan)
Опубликовано: 17.04.2007
Одна из сильных сторон объектно-ориентированного программирования – и на самом деле главная из них – предоставляемая разработчикам возможность моделирования отношений данных естественным путем. Это не значит, что процесс моделирования прост. Архитектура многих реальных систем может представлять собой сложные деревья из подсистем, взаимодействующих с другими, не менее сложными системами. Архитектура классов в таких системах может быть головокружительно запутанной, и весьма сложной в программировании.
Все еще более усложняется, если в смесь добавляется персистентность. Одно дело – кодировать данные и методы для сложной, взаимоувязанной системы из множества классов; совсем другое – сохранять результирующие объектные структуры в БД так, чтобы их было легко искать, получать, обновлять или удалять ... сохраняя при этом их отношения. Мы собираемся исследовать эти хитрости; мы рассмотрим некоторые трудности с персистентностью (модный способ сказать «сохранение в БД») больших или сложных объектных структур. Для этого мы будем использовать несколько примеров, гипотетических, но отражающих реальные ситуации в программировании:
- плоские объектные структуры
- длинные объектные деревья
- развивающиеся объектные структуры
Мы покажем, как эти сложности смягчаются при использовании ООСУБД db4o. Вы увидите, как db4o позволяет сосредоточиться на создании оптимальной структуры классов и объектов приложения. Вам не придется беспокоиться о том, что эти структуры могут мешать (или им могут помешать) операциям с БД. Другими словами, db4o обеспечивает персистентность, минимально обременяя разработчика. Никакого специального кода; никаких изменений отношений объектов в угоду БД. Просто храните объекты, которые нужно хранить; выбирайте объекты, которые нужно выбрать, и удаляйте те объекты, что больше не нужны.
Остальное сделает db4o.
Что такое db4o?
Объектно-ориентированная библиотека для организации БД db4o (database for objects), от db4objects – это исконно объектно-ориентированная СУБД, «родная» как для Java, так и для .NET-языков. Заслуживающие упоминания достоинства db4o – скорость, простота и низкие требования к памяти. db4o может сохранять «обычные объекты». Не исконно объектно-ориентированные СУБД для обеспечения персистентности нуждаются в инструментировании исполняемого кода. Остальные требуют создания отдельных файлов «схем объектов». Но db4o не требует применения каких-либо необычных (или дополнительных) приемов программирования для помещения объектов в БД, или манипуляций с ними, когда они уже там.
Приведенные ниже примеры написаны на Java. Однако, как говорилось выше, есть и версия db4o для .NET. Соответственно, приведенные в примерах концепции применимы как к Java, так и к .NET.
ПРИМЕЧАНИЕ
В db4o БД рассматривается как ObjectContainer. ObjectContainer ассоциируется с определенным файлом на диске. Открытие ObjectContainer – это простой вызов API: ObjectContainer db = Db4o.openFile(“<path>”); где <path> - путь к файлу БД. После завершения операций с БД, вызывается db.close(); В остальной части этой статьи предполагается, что объект ObjectContainer с названием db уже открыт.
|
Плоские объектные структуры
Простые объектные структуры, тем не менее содержащие множество объектов – это «плоские» структуры. Такая структуры могут включать большой массив, или, может быть, какой-нибудь связанный список. Определяя, как сохранять такую структуру, нужно сперва определить, должен ли массив (или список) постоянно находиться в памяти (здесь мы говорим об очень больших списках, включающих тысячи или миллионы вхождений). Такое определение, в свою очередь, требует определения потенциального размера списка, и прикидок, уместится ли список в доступной памяти.
Если уместится, возможно, всю штуковину можно сохранить в один прием. Иначе придется читать и записывать ее содержимое в/из БД по частям.
Пример 1. Мониторинг транзакций Web-приложения
Организация предоставляет клиентам услуги через Web-приложение. Клиентские сайты подключаются к этому приложению и отправляют ему транзакции (чтение, обновление, изменение и т.д.). Организация хочет отслеживать – в произвольное время с переменным интервалом – число и время отклика запросов к этому Web-приложению.
Разработчики этой организации создают систему мониторинга, состоящую из приложения-«заглушки», подключенного к серверу, и отдельной консоли мониторинга. Заглушка встраивается в Web-приложение и отсылает данные о транзакциях консоли (через какой-либо механизм IPC). Пользователь, запускающий консольную программу, может начать «сессию». В течение сессии заглушка отслеживает тип, поступление и отправку клиентских запросов и ответов на них. Эта информация передается на консоль, получающую, организующую и сохраняющую информацию в БД.
Впоследствии администраторы могут обратиться к БД, исследовать тенденции и создавать отчеты и графики, отражающие такую информацию, как число транзакций в различное время суток, среднее время отклика в отношении к количеству транзакций в секунду, и так далее. Организация может использовать эту информацию, чтобы определить, хорошо ли масштабируется сервер под нагрузкой.
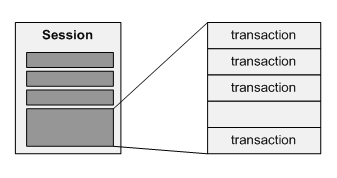
Рисунок 1. Простая структура для моделирования сессии. Объект Session включает ArrayList объектов Transaction.
Реализация
Разработчики этого гипотетического приложения моделируют сессию, используя два класса. Один, класс Session, включает глобальную информацию о сессии: уникальное имя, дату и время начала и завершения сессии. Объект Session также содержит List с собранной информацией о транзакциях.
Класс Session выглядит так:
public class Session
{ private String sessionName;
private timestamp start;
private timestamp finish;
private List transactions;
Session (String sessionName,
timestamp start)
{
this.sessionName = sessionName;
this.start = start;
this.transactions = new ArrayList();
}
public void addTransaction(Transaction trans)
{
transactions.add(trans);
}
... other methods for Session ...
}
|
А класс Transaction моделирует «пакеты» данных о транзакциях, получаемые от заглушки.
public class Transaction
{ private int type;
private int quantity;
private timestamp start;
private timestamp finish;
} ... remainder of Transaction class ...
|
ПРИМЕЧАНИЕ
Поскольку мы в первую очередь заинтересованы в том, как сохранить члены данных объектов, и только потом в поведении методов класса, код классов приведен в сокращении. Кроме того, эти классы предполагают доступность типа данных timestamp – возможно, java.sql.timestamp – а также набора констант типа int, определенных для перечисления типа транзакции type.
|
При начале сессии создается экземпляр объекта Session, которому присваивается уникальное имя (sessionName). Затем консоль «говорит» заглушке начать сбор данных о транзакциях. При поступлении пакета данных от заглушки консольное приложение создает новый объект Transaction, копирует в него данные и сохраняет объект в ArrayList транзакций сессии:
theSession.addTransaction(theTransaction);3
|
Здесь объект Session – это theSession, а объект Transaction – theTransaction
После завершения сессии нет ничего проще, чем сохранить её в БД db4o, и здесь мы впервые познакомимся со встроенной логикой db4o, существенно упрощающей работу программиста. Чтобы сохранить целый объект, с List и всем остальным, нужна только одна строка кода:
db4o молча обходит дерево объектов, отыскивая и сохраняя не только объект theSession, но также и все члены ArrayList транзакций.
Получение объектов сессий так же просто. db4o позволяет выполнять прямолинейные «запросы по образцу». Чтобы запросить БД db4o, создается «прототип» объекта класса, который нужно найти. Заполните подходящие поля значениями, которые нужно найти, и вызовите метод get()ObjectContainer'а.
Предположим, например, что нужно найти сессию с именем "FridayCapture”:
Session proto = new Session("FridayCapture", (timestamp)0);
ObjectSet result = db.get(proto);4
|
ПРИМЕЧАНИЕ
Пустые или нулевые поля не участвуют в запросе
|
Результат запроса – это ObjectSet, который можно перебирать в цикле для выборки нужных объектов. Поскольку приведенный выше запрос возвращает только один объект, его можно получить из набора напрямую:
Session theSession = (Session)result.next();
db.activate(theSession, 2);
|
Вторая строка приказывает db4o «активировать» theSession на глубину 2. Когда db4o активирует объект, она загружает поля объекта из БД. Так, приведенном примере, глубина активации 2 заставляет db4o выбрать не только объект theSession, но и его «дочерние» объекты (содержимое ArrayList). Указание глубины активации 3 выбирает детей и внуков объекта, 4 – детей, внуков и правнуков, и т.д.
ПРИМЕЧАНИЕ
db4o позволяет указывать, если нужно, глубину активации для всех объектов в БД, а не для каждого в отдельности, как показано выше. Здесь явная, пообъектная активация показана для объяснения концепции активации как таковой.
|
Вот так все просто. Вся структура объекта сохраняется одним вызовом. И всю структуру объекта можно восстановить с помощью простого, легкого для понимания API.
Это приводит нас к важному принципу:
db4o позволяет работать со структурами объекта почти так же, как если бы эти структуры находились в памяти. Для управления сохранением объектов требуется мало дополнительного кода.
Вариации на тему
Предыдущий пример был прямолинейным и функциональным, но, возможно, не идеальным. То, что все данные сессии находятся в памяти, ограничивает размер сессии объемом доступной памяти (это может быть совершенно реалистичный верхний предел, но это не относится к предмету данной статьи).
Во врезке «Как db4o обходится с утечками памяти» мы покажем, что при решении проблемы утечек памяти – которая существует независимо от того, какой back-end-движок персистентности используется – db4o не является помехой; она хорошо вписывается в решение проблемы. Ее простой механизм запросов на самом деле, значительно упрощает решение.
Удаление
Прежде, чем закончить этот раздел, нужно описать операцию, которая здесь еще не встречалась. Это позволит нам проиллюстрировать еще одно важное способность db4o.
Предположим, что нужно удалить данные сессии. Удалить один объект очень просто. Если персистентный объект Session выбран в theSession, удалить его из БД можно так:
Но удаление связанного списка произвольной длины может вылиться в громоздкий цикл. Поскольку для удаления персистентного объекта его сперва нужно выбрать, цикл будет таким:
- Выбрать головной объект Transaction
- Сохранить его ссылку на следующий объект
- Удалить Transaction
- Выбрать объект, на который ссылался Transaction
- Вернуться к п.2 и повторять, пока ссылка не будет равна null.
Это работает, но это до такой степени некрасиво, что такое как-то даже не хочется реализовать.
К счастью, db4o сохраняет нашу гордость благодаря возможности «каскадного удаления». Все, что нужно сделать – это сказать db4o перед открытием БД, что мы хотим активировать каскадное удаление для конкретного класса. Например, код может выглядеть так:
Configuration config = Db4o.configure();
ObjectClass sessionObjectClass =
config.objectClass("<package>.Session");
sessionObjectClass.cascadeOnDelete(true);
|
ПРИМЕЧАНИЕ
Здесь <package> – это package класса Session.
|
После того, как приложение выполнило этот код, открыло БД и выбрало из нее Session, подлежащий удалению, можно удалить сессию целиком – theSession и весь связанный список объектов Transaction – одним вызовом:
db4o траверсирует все дерево объектов с корнем в theSession, удаляя все дочерние объекты. В данном случае db4o пройдет до конца связанного списка, позволяя уничтожить всю цепочку объектов Transaction единственным нажатием кнопки.
ПРИМЕЧАНИЕ
Каскадное удаление существенно упрощает программирование. Но оно может нанести вред при неаккуратном обращении. Как и любая мощная возможность, каскадное удаление требует осторожности.
|
Сравнение с реляционными СУБД
Остановитесь на минуточку, посмотрите на примеры кода в этом разделе и прикиньте, что пришлось бы писать при использовании реляционной СУБД. Где-то должно быть определение схемы для структуры таблиц. Пришлось бы создать две таблицы – одну для данных сессии, другую – для данных транзакций. В каждой таблице нужно назначить ключевые поля, и определить в схеме отношение один-ко-многим, связывающее запись сессии с множественными записями транзакций (скорее всего придется вставить в таблицу транзакций колонку, не имеющую никакого другого назначения, кроме связи с таблицей сессий). Там будут SQL-команды INSERT, UPDATE и DELETE – и операции присваивания для перемещения данных в/из членов объектов и связывания переменных в SQL-выражениях. Выборка целой сессии потребует соединения (join). И так далее.
Короче, немалое количество кода, необходимого для перемещения данных через невидимую границу, разделяющую объектно-ориентированную программу и реляционную СУБД...
...благодаря db4o не потребуется.
Что нужно?
Здесь некоторые читатели могут заподозрить, что мы делаем из мухи слона. Данные Transaction поступают последовательно, и сохраняются также последовательно. Почему не создать последовательный файл и не записывать данные в него по мере поступления? Зачем вся эта суета с БД?
При некоторых обстоятельствах это, конечно, был бы наилучший путь. Но если вы создаете репозиторий, из которого собираетесь получать информацию в будущем, использование БД даст вам готовые возможности поиска, которые иначе придется реализовать самостоятельно.
ПРИМЕЧАНИЕ
Рассматривая пример из этого раздела, предположите, что вам нужно найти некое количество байтов, передаваемых определенным видом транзакций ... во всех сессиях. При использовании набора плоских последовательных файлов придется писать код для поиска по всем этим файлам.
А вот db4o позволяет найти все эти транзакции с помощью простого запроса. Предположим, что тип транзакции определяется константой READ_TRANSACTION, а код выглядит примерно так:
|
Transaction theTrans;
double totalbytes = (double)0.0;
int totaltrans = 0;
double average;
...
Transaction proto = new Transaction();
proto.setType(READ_TRANSACTION);
ObjectSet result = db.get(proto);
while(result.hasNext())
{
theTrans = (Transaction)result.next();
totalbytes + (double)theTrans.getQuantity();
totaltrans++;
}
if(totaltrans!=0)
average = totalbytes/(double)totaltrans;
...
|
ПРИМЕЧАНИЕ
Это можно сделать потому, что объекты Transaction хранятся именно как объекты. Поэтому они доступны – независимо от объектов Session – через механизм запросов db4o.
|
Это, конечно, куда проще кодировать, чем было бы, если бы пришлось писать код для поиска по всем спискам во всех сохраненных сессиях.
Длинные деревья объектов
Одна из прелестей объектно-ориентированного программирования в том, что оно позволяет моделировать сложные и тщательно проработанные связи более естественным способом, чем пришлось бы при использовании структурного программирования (до краев набитого порождающими ошибки указателями). Некоторые из наиболее сложных структур выглядят как та или иная «древовидная» структура.
Говоря о «длинных деревьях объектов», мы имеем в виду структуры объектов, отличающиеся от упоминавшихся выше в смысле размера. Предыдущий пример был «мелким, но широким». Теперь мы займемся «глубокими» и «разветвленными» конфигурациями. То есть корневой объект ссылается на несколько дочерних объектов, у каждого из дочерних объектов тоже есть ряд потомков, и так далее, на неизвестную глубину.
Пример 2: БД материалов для электрогенераторов
Компания, производящая линейку электрогенераторов, хотела бы создать БД со списком материалов. В такой БД каждый конечный продукт «указывает» на коллекцию узлов и агрегатов. Они, в свою очередь, указывают на следующие узлы и агрегаты. Кроме того, узлы и агрегаты ссылаются на списки деталей. В результате вся структура продукта отражается в структуре узлов, агрегатов и частей, и полный обход дерева объектов показывает все составные части продукта.
Эта структура как будто специально создана для ОО БД. «Продукт» в БД естественно представляется как дерево. Таким образом, разработчики определяют три класса: Assembly, ComponentParts и RawPart.
Как db4o справляется с утечками памяти.
Пример “Мониторинг транзакций Web-приложения” в разделе «Плоские объектёные структуры» был простым и функциональным, но, возможно, не идеальным. То, что все данные сессии находятся в памяти, ставит верхний предел размера сессии – этим пределом является, конечно, объем доступной памяти.
Предположим, что разработчики определили, что приложение должно работать с произвольно большими сессиями. Следовательно, они изменят классы так, чтобы данные транзакций помещались в однонаправленный список:
public class Session
{ private String sessionName;
private timestamp start;
private timestamp finish;
private Transaction head;
private int length;
...
public void incrementLength()
{ length++; }
public int getLength()
{ return(length); }
public void setFinish(timestamp theTime)
{ finish = theTime; }
public void setHead(Transaction theHead)
{ head = theHead; }
... remainder of Session class ...
}
public class Transaction
{ private int type;
private int quantity;
private timestamp start;
private timestamp finish;
private Transaction next;
... remainder of Transaction class ...
}
|
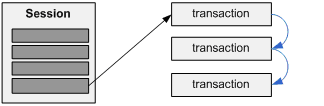
Более продуманная структура. Теперь объекты Session содержат ссылку на однонаправленный список объектов Transaction.
Цель, конечно, состоит в том, чтобы помещать транзакции в БД, используя меньше памяти. При поступлении данных транзакции они присоединяются к списку – в каждом объекте Transaction есть указатель на следующие объекты, у последнего этот указатель равен null, показывая, что это заключительный объект спика – и записываются в БД. При завершении сессии в объект Session записывается метка времени, и этот объект сохраняется в БД. Вот код для этого:
Transaction tail;
Transaction newTransaction;
Session theSession;
...
theSession = new Session("<Session Name>",
new timestamp(System.currentTimeMillis()));
tail = null;
...
newTransaction = new Transaction(<fill in from incoming data>);
if (theSession.getLength() == 0)
Session.setHead(newTransaction);
else
{
tail.next = newTransaction;
db.set(tail);
}
tail=newTransaction;
theSession.incrementLength();
...
theSession.setFinish(new timestamp(System.currentTimeMillis());
if(tail != null) db.set(tail);
db.set(theSession);
...
|
Радуясь новому коду, разработчики запускают его и...
...обнаруживают, что он не работает. Все данные по-прежнему в памяти.
Внимательные программисты, видимо, заметили, что это классическая утечка памяти в Java. Поскольку объект theSession содержит ссылку на начало списка, присоединение новых объектов просто удлиняет цепочку в памяти, хотя члены списка и сохраняются в БД. Пока ссылка на начало списка находится в памяти, весь список остается в памяти.
К счастью, есть простое решение, не только устраняющее утечку памяти, но и позволяющее настроить «шаг» записи элементов списка на диск. Это решение включает:
- Запись объекта Session на диск и удаление любых ссылок на него, то есть «отрезание головы».
- Кеширование поступающих объектов транзакций по мере их поступления, чтобы запись в БД происходила «кусками» (после заполнения кеша).
- Считывание объекта Session обратно для исправления длины и заполнения полей.
Вот исправленный код:
Transaction transactionCache[];
int transactionCacheNext;
int numTransactions;
boolean sessionWritten;
Session theSession;
String theSessionName;
...
sessionWritten=false;
numTransactions=0;
theSessionName = theSession.getSessionName();
dbTransCacheInit(CACHE_SIZE);
...
public void dbTransCacheInit(int size)
{
transactionCache = new Transaction[size];
transactionCacheNext = 0;
}
...
public void dbCachedSet(Transaction obj)
{
if((transactionCacheNext+1)==transactionCache.length)
dbCacheFlush();
transactionCache[transactionCachNext++]=obj;
}
public void dbCacheFlush()
{
if(sessionWritten==false)
{ db.set(theSession);
theSession=null;
sessionWritten=true;
}
if(transactionCacheNext>0)
for(int i=0; i<transactionCacheNext; i++)
{ db.set(transactionCache[i];
numTransactions++;
transactionCache[i]=null;
}
transactionCacheNext=0;
}
...
finishTime = new timestamp(currentTimeMillis());
dbCacheFlush();
Session proto = new Session(theSessionName,0);
ObjectSet result = db.get(proto);
theSession = (Session) result.next();
theSession.setFinish(finishTime);
theSession.setLength(numTransactions);
db.set(theSession);
...
|
Новый код создает структуру персистентного связанного списка, который может расти до произвольно больших размеров. Кроме того, размер кеша настраивается, что позволяет разработчикам регулировать потребление памяти.
Посмотрите, что именно здесь показано. Мы решили проблему утечки памяти – существующую независимо от движка персистентности – с минимумом усилий. И db4o не мешала нам, очень удачно встроилась в решение проблемы. на самом деле, ее простой механизм запросов значительно облегчил решение проблемы.
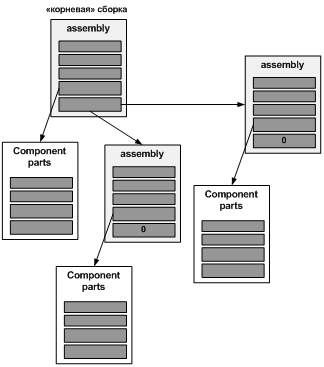
Рисунок 2.
Assembly состоит из произвольного числа (number) subAssemblies и произвольного числа (number) componentParts (subAssemblies и componentParts - массивы). Деталь (component part) представляет собой реальную, физическую деталь, такую, как винт, болт, клемма и т.д. (как вы увидите ниже, каждое вхождение componentParts содержит количество. Так что если узел содержит как составные части 15 винтов #2, они будут показаны как один элемент массива componentParts, а не 15). Кроме того, структура рекурсивна: каждый из подузлов является узлом (вложенным), состоящим из componentParts и, возможно, из других subAssemblies.
Каждый элемент массива componentParts ссылается на элементы RawPart, где хранится информация, нужная для идентификации отдельного предмета: фирма-поставщик (или фирмы-поставщики), SKU детали и ее цена.
Таким образом, описание продукта – это дерево. Корень (сверху) – это сам продукт. При продвижении от корня к ветвям вы непременно дойдете до «листьев» - узлов, состоящих из отдельных componentParts.
public class Assembly
{
public String name;
public Assembly subAssemblies[];
public ComponentParts componentParts[];
... remainder Assembly class ...
}
public class ComponentParts
{
public int productID;
public int quantity;
...remainder of ComponentParts class...
}
public class RawPart
{
public int productID;
public string SKU;
public List suppliers;
public BigDecimal cost;
...remainder of RawPart class...
}
|
Если вы ищете здесь сложный кусок кода, добавляющего в БД новый предмет со всеми его потомками, то вы его не найдете. db4o может обработать эту структуру так же легко, как объекты из предыдущего раздела. Если вы создали объект узла theAssembly, а также создали и связали между собой все его составные части, вы можете поместить theAssembly в БД так:
И, как и раньше, если вы включили каскадное удаление, удалить объект Assembly со всеми потомками можно вызовом:
Заметьте, однако, что мы позаимствовали из мира баз данных понятие внешнего ключа, чтобы создать отношение между объектом ComponentParts и объектом RawPart. Их связывает между собой поле productID. Поэтому, если мы захотим получить, например, цену конкретной детали, мы напишем что-то вроде:
int prodID = theAssembly.componentParts[<index>];
RawPart rawPartProto = new RawPart;
rawPartProto.productID = prodID;
ObjectSet result = db.get(rawPartProto);
theRawPart = (RawPart) result.next();
|
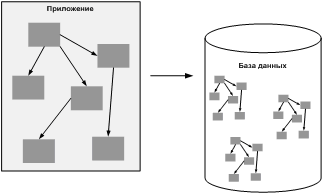
Рисунок 3. С помощью db4o сложные структуры объектов сохраняются в БД так же легко, как и простые – с помощью одного вызова.
То, что связь между объектами ComponentParts и RawPart – это не объектная ссылка, позволяет не удалять из БД детали при каскадном удалении узлов.
Как видите, манипуляции со сложными древовидными структурами так же просты, как манипуляции с «плоскими» массивами или списками.
Изменения структур объектов
«Я не усложняю вещи. Они сами усложняются.»
Martin Riggs, Lethal Weapon
Смысл этого известного высказывания в том, что, хотим мы того или нет, но вещи эволюционируют, и делают это, как правило, в сторону повышения сложности. Программисты, воевавшие с проектами, в которых со временем требования изменялись, понимающе кивнут головой. Если меняется структура данных, необходимые изменения кода могут быть громоздкими и привести к появлению ошибок, особенно если БД забита «старыми» данными, которые нужно сделать «новыми».
Но при использовании db4o такие изменения просты. Вернемся к первому примеру.
Пример 1 – возвращение
Спустя некоторое время организация выросла, и теперь ее серверы приложений работают в нескольких местах. Разработчиков просят расширить систему мониторинга, чтобы собирать данные одновременно с нескольких серверов.
Они, соответственно, изменяют определение класса:
public class Session
{
private String sessionName;
private List hosts;
private timestamp start;
private timestamp finish;
private Transaction head;
private int length;
... remainder of Session class ...
}
public class Transaction
{ private String host;
private int type;
private int quantity;
private timestamp start;
private timestamp finish;
private Transaction next;
... остальная часть класса Transaction ...
}
|
В новой версии объекты Session содержат список серверов, с которых собираются данные. Кроме того, каждый объект Transaction включает идентификатор хоста. Это позволяет в одной сессии получать данные с произвольного количества серверов.
Мы решили использовать строку для идентификации хостов в каждой транзакции. Это упрощает пример. В реальности мы отнеслись бы экономнее к дисковому пространству; возможно, использовали бы однобайтовый идентификатор, и присвоили каждому серверу в сети ID от 1 до 255.
Теперь, когда сессия запущена, имена хостов хранятся в списке хостов. При поступлении транзакций каждой из них, до помещения в связанный список и записи в БД, присваивается идентификатор сервера. То, что мы показали в первом примере – механика сохранения данных в БД – останется в основном без изменений.
Изменения схемы
Впрочем, подождите. Кое-что изменилось: структура класса. Что с лучилось с данными, уже хранящимися в БД? Не потеряем ли мы всю информацию, накопленную, пока организация использовала единственный сервер? Предположим, приложение начинает запись «новых» объектов Session и Transaction в исходную БД: «вылетит» ли приложение, когда «старые» данные будут считаны в объекты новых классов? Нужно ли нам создавать новую БД, и писать приложения для конвертирования данных?
К счастью, нет. db4o ассимилирует развивающиеся классы, не теряя ни бита. Нужно только добавить новый метод к каждому из определений классов. К классу Session нужно добавить:
public void objectOnActivate(ObjectContainer container)
{
if(hosts == null)
{
hosts = new ArrayList();
hosts.add("MainServer");
}
}
|
А к классу Transaction:
public void objectOnActivate(ObjectContainer container)
{
if(host == null)
host = "MainServer";
}
|
Вот так. Отряхните руки. Конверсия выполнена.
При активации объекта db4o должна создать экземпляр объекта по определению класса. В процессе создания экземпляра db4o проверяет наличие в классе метода objectOnActivate() с сигнатурой, приведенной в двух методах выше. Если db4o находит такой метод, она вызывает его в конце процесса активации. Следовательно, этот метод можно использовать для проверки содержимого созданного объекта, а также для заполнения пустых или равных null членов объекта нужными данными до передачи объекта приложению.
Таким образом, можно незаметно заставить «старые» выглядеть «новыми». Код приложения никогда не знает – и не должен знать – что производится изменение. Для приложения все объекты, полученные из БД, являются «новыми». Реально, когда код приложения их видит, они уже являются «новыми». А если их придется записывать их обратно в БД, новая версия перезапишет старую.
В приведенных выше примерах мы предполагаем, что исходный сервер приложений называется "MainServer." Таким образом, все старые объекты Session и Transaction будут выглядеть для приложения так, как если бы все они были получены из одного источника "MainServer."
Наконец, заметьте, что db4o позволяет использовать изменившуюся структуру объектов – на самом деле схему объектов – без загрязнения кода приложения. Изменения потребовали только два маленьких методов, запрятанных в определениях классов, и вызываемы только при необходимости, без нашего участия.
Еще раз сравниваем с РСУБД
Теперь остановимся еще раз и прикинем, что бы пришлось делать, если бы данные хранились в РСУБД. Нам бы пришлось:
- Создать отдельный набор таблиц; один набор содержал бы старые данные, а другой – новые. Нам пришлось бы писать утилиты для управления одновременным использованием старых и новых данных, или...
- Создать новую БД, определить новые схемы, написать приложение, конвертирующее старые данные в новые, и надеяться, что в будущем структуру объектов не придется менять еще раз.
На самом деле, даже non-native ООСУБД не может работать с изменившейся структурой объектов с легкостью db4o. Многих из них смесь «новых» и «старых» объектов поставит в тупик. Какого-то рода конверторы потребуются почти наверняка.
Есть соблазн сказать, что db4o заходит еще дальше. Даже если структуры объектов могут измениться прямо «на ходу», db4o управляет изменяющейся ситуацией так, что мы практически никогда не теряем равновесия. db4o позволяет аккуратно обрабатывать изменения, используя API, производящий легкий в поддержке код, и тем самым позволяет решать действительно заслуживающие внимания задачи, не тратя времени на создание вспомогательного кода.
Суммируем
Надеемся, что в этой статье нам удалось показать, что управление персистентностью объектов – благодаря db4o – очень просто. Причем очень просто, независимо от структуры сохраняемых данных.
Мы также надеемся, что мы в достаточной мере показали, что db4o не смущает сложность объектов в пространстве и времени; то есть, db4o может не только управлять «плоскими» и «разветвленными» структурами объектов, но и работать с изменяющимися структурами. Кроме того, мы надеемся, что нам удалось показать, что если вы должны использовать БД в следующем Java- (или .NET) приложении, вам не потребуется тратить время на изучение нюансов таких технологий, как JDBC, ODBC, SQL, OQL и т.д. Вы уже потратили время на изучение деталей объектно-ориентированного программирования; db4o оптимизирует ваши затраты.
Не то, чтобы мы хотели сказать, что эти технологии в каком-либо отношении ущербны. Но, как было показано, в db4o одной строкой кода делается то, что в РСУБД требует нескольких. А non-native ООСУБД требуют дополнительных шагов по инструментированию кода или дополнительных материалов (таких, как файлов схем), к счастью, не нужных при использовании db4o.
Проще сказать, db4o упрощает даже самые сложные задачи по сохранению объектов.
Любой из материалов, опубликованных на этом сервере, не может быть воспроизведен в какой бы
то ни было форме и какими бы то ни было средствами без письменного разрешения владельцев авторских
прав.
Copyright © 1994-2016 ООО "К-Пресс"
