 |
Технология Клиент-Сервер 2006'4
|
|
|
О возможности введения дополнительных критериев качества схем баз данных
Автор: Алексей Петров
Опубликовано: 18.04.2007
Введение
Как правильно спроектировать схему данных? Какие критерии должен применить разработчик при выборе из большого числа возможных схем? Широко известны «академические» требования к качеству схемы данных – требования нормализации или соблюдения одной из нормальных форм. При этом не афишируется (не написано в учебниках, неочевидно для начинающих проектировщиков схем данных), что и при соблюдении этих требований обычно остается достаточно широкий выбор возможных схем. В данной статье приводится пример выбора между альтернативными схемами данных, когда на первый план выступают уже не требования нормализации, а другие критерии: простота реализации клиентской части, уменьшение объема хранимой информации.
Два варианта схемы данных для табельного учета
Предметная область примера – табельный учет рабочего времени. Основная информация, которую необходимо хранить в программе табельного учета – кто, когда, сколько часов отработал, и по какому коду оплаты. Документальным отражением этой информации служит табель учета рабочего времени (рисунок 1).

Рисунок 1. Табель учета рабочего времени (фрагмент).
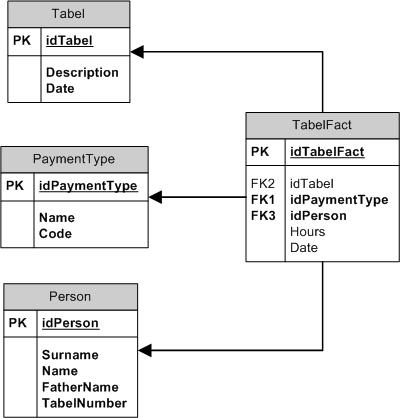
Рисунок 2. Схема данных – «Модель А».
На рисунках 2 и 3 приводятся две схемы данных, которые предлагается рассматривать как альтернативные для этой предметной области. Схемы упрощены, в реально работающем варианте базы намного больше полей и таблиц.
На схеме:
- Person – справочник сотрудников (ФИО, табельный номер…)
- PaymentType – таблица кодов оплаты
- Tabel – таблица с заголовками документов-табелей. Поле Date содержит информацию только о годе и месяце табеля.
- TabelFact – таблицы фактов (кто, когда, сколько часов отработал). Поле Date – в какой день месяца произошел факт.
Таблица TabelRow содержит строки табелей.
Предварительное сравнение этих схем показывает:
- Они различаются представлением данных фактов отработанного времени. В первом случае – хранятся факты в чистом виде, во втором – они хранятся в развернутом виде, как строки табелей.
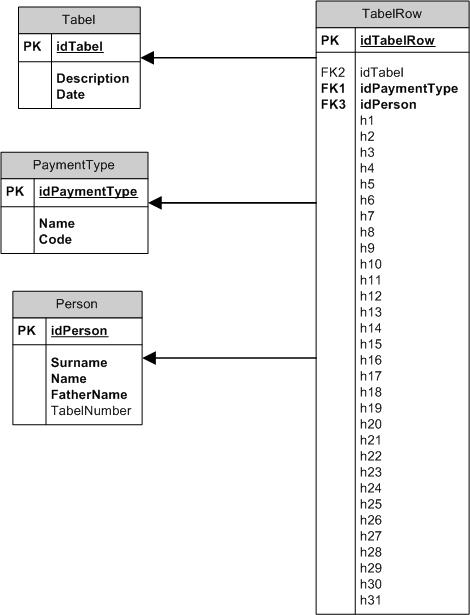
Рисунок 3. Схема данных – «Модель Б».
- В схеме в модели фактов можно создать pivot-представление, аналогичное таблице TabelRow в модели строк.
SELECT idTabel, idPaymentType, idPerson,
SUM(CASE DAY(Date) WHEN 1 THEN Hours ELSE 0 END)
AS h1,
SUM(CASE DAY(Date) WHEN 2 THEN Hours ELSE 0 END)
AS h2,
...
SUM(CASE DAY(Date) WHEN 31 THEN Hours ELSE 0 END)
AS h31
FROM tblTabelFact
GROUP BY idTabel, idPaymentType, idPerson
|
или, для MS SQL Server 2005:
SELECT idTabel, idPaymentType, idPerson,
[1] AS h1, [2] AS h2, [3] AS h3, [4] AS h4, [5] AS h5,
[6] AS h6, [7] AS h7, [8] AS h8, [9] AS h9, [10] AS h10,
[11] AS h11, [12] AS h12, [13] AS h13, [14] AS h14, [15] AS h15,
[16] AS h16, [17] AS h17, [18] AS h18, [19] AS h19, [20] AS h20,
[21] AS h21, [22] AS h22, [23] AS h23, [24] AS h24, [25] AS h25,
[26] AS h26, [27] AS h27, [28] AS h28, [29] AS h29, [30] AS h30, [31] AS h31
FROM
(SELECT idTabel, idPaymentType, idPerson, Hours, DAY(Date) as Day
FROM tblTabelFact) AS t1
PIVOT (SUM(Hours) FOR [Day] IN ([1], [2], [3], [4], [5], [6], [7], [8], [9], [10],
[11], [12], [13], [14], [15], [16], [17], [18], [19], [20],
[21], [22], [23], [24], [25], [26], [27], [28], [29], [30], [31])) AS t2
|
- В модели строк можно создать unpivot-представление, аналогичное таблице TabelFact в модели А:
SELECT TabelRow.idPaymentType, Calendar.Date, TabelRow.idPerson,
TabelRow.idTabel, TabelRow.h1 AS Hours
FROM Tabel
INNER JOIN TabelRow ON Tabel.idTabel = TabelRow.idTabel
INNER JOIN Calendar ON YEAR(Calendar.Date) = YEAR(Tabel.Date)
AND MONTH(Calendar.Date) = MONTH(Tabel.Date) AND Calendar.Day = 1
UNION
SELECT TabelRow.idPaymentType, Calendar.Date, TabelRow.idPerson,
TabelRow.idTabel, TabelRow.h2 AS Hours
FROM Tabel
INNER JOIN TabelRow ON Tabel.idTabel = TabelRow.idTabel
INNER JOIN Calendar ON YEAR(Calendar.Date) = YEAR(Tabel.Date)
AND MONTH(Calendar.Date) = MONTH(Tabel.Date) AND Calendar.Day = 2
UNION
...
UNION
SELECT TabelRow.idPaymentType, Calendar.Date, TabelRow.idPerson,
TabelRow.idTabel, TabelRow.h31 AS Hours
FROM Tabel
INNER JOIN TabelRow ON Tabel.idTabel = TabelRow.idTabel
INNER JOIN Calendar ON YEAR(Calendar.Date) = YEAR(Tabel.Date)
AND MONTH(Calendar.Date) = MONTH(Tabel.Date) AND Calendar.Day = 31
|
для MS SQL-Server 2005:
SELECT t.idTabel, t.idPaymentType, idPerson, Hours, Calendar.Date
FROM tblTabelRow
UNPIVOT (Hours For Day IN (h1, h2, h3, h4, h5, h6, h7, h8, h9, h10,
h11, h12, h13, h14, h15, h16, h17, h18, h19, h20,
h21, h22, h23, h24, h25, h26, h27, h28, h29, h30, h31)) AS t
INNER JOIN tblTabel ON t.idTabel = tblTabel.idTabel
INNER JOIN Calendar ON YEAR(tblTabel.Date) = Calendar.YEAR
AND MONTH(tblTabel.Date) = Calendar.Month AND t.Day = 'd' + CAST(Calendar.Day AS VARCHAR)
|
где таблица Calendar содержит список всех календарных дат (в разумном диапазоне) и имеет следующую структуру:
CREATE TABLE Calendar(
[Date] [datetime],
[Year] [int],
[Month] [int],
[Day] [int])
|
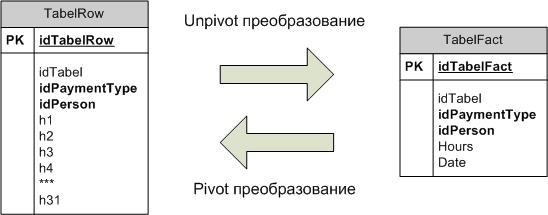
Рисунок 4. Pivot- и Unpivot-преобразования.
- Возможности, продемонстрированные в пп. 2 и 3 показывают, что схемы действительно являются альтернативными и можно говорить о выборе между ними. (На самом деле схемы являются до конца эквивалентными лишь с учетом следующих ограничений: в модели фактов у одного человека в табеле в один день по конкретному виду оплаты труда не может быть двух записей, в модели строк – проще: на одного человека в табеле не может быть двух строк по одному виду оплаты. Если это соблюдается – приведенные выше операции pivot и unpivot будут обратными.)
- Проверка таблиц TabelFact и TabelRow на соответствие нормальным формам:
- Ни одно из полей обеих таблиц не содержит более одного значения и ни одно из ключевых полей не пусто – выполняется требование 1-й нормальной формы
- В TabelRow есть составной первичный ключ {idTabel, idPaymentType, idPerson} (в одном табеле не может быть двух строк с одним видом оплаты для одного человека), который связан полной функциональной зависимостью с любым полем, не входящим в первичный ключ. Аналогично – таблица TabelFact с составным ключом {idTabel, idPaymentType, idPerson, Date} (в один день не может быть зафиксировано два факта работы с одинаковым видом оплаты для одного и того же человека). В этой таблице остается лишь одно поле, не входящее в составной ключ – Hours оно не является функционально зависимым от части составного ключа – соответственно связано полной функциональной зависимостью с составным первичным ключом. – Для обеих таблиц выполняется требование 2-й нормальной формы.
- Неключевые поля обеих таблиц не зависят функционально от других неключевых полей: в TabelFact – одно неключевое поле (Hours), в TabelRow – неключевые поля h1-h31 на языке предметной области требование означает, что количество часов, отработанное человеком в какой-либо день месяца не должно зависеть функционально от количества часов, отработанного в другие дни – так оно и есть на самом деле. Таким образом, таблицы соответствуют 3-й нормальной форме.
- Таблицы соответствуют нормальной форме Бойса-Кодда, т.к. имеют всего по одному ключу, уже рассмотренному в пункте b.
- В таблицах нет многозначных зависимостей (многозначная зависимость не является функциональной, она существует в том случае, когда из факта, что в таблице содержится некоторая строка X, следует, что в таблице обязательно существует некоторая определённая строка Y). Соответственно, выполняются требования четвертой и пятой нормальных форм (они формулируются, как ограничения на существующие многозначные зависимости).
Таким образом, выбор между моделями А и Б возможен и, принимая решение, необходимо руководствоваться иными критериями, нежели нормализация данных.
Критерий простоты программирования учетной системы
С точки зрения дизайна пользовательского интерфейса логично было бы предположить, что проще вводить информацию в электронном табеле таким же образом, как это делается в бумажном документе. Т.е., напрашивается табличная форма ввода, в общих чертах повторяющая табель (рисунок 1).
Запросы для получения данных в эту форму:
SELECT idTabel, idPaymentType, idPerson,
SUM(CASE DAY(Date) WHEN 1 THEN Hours ELSE 0 END) AS h1,
SUM(CASE DAY(Date) WHEN 2 THEN Hours ELSE 0 END) AS h2,
...
SUM(CASE DAY(Date) WHEN 31 THEN Hours ELSE 0 END) AS h31
FROM tblTabelFact
GROUP BY idTabel, idPaymentType, idPerson
WHERE idTabel = @idTabel
|
Всего 35 строк. Можно конечно принять решение о разворачивании данных не в SQL-запросе, а в программном коде, но вряд ли это будет проще.
SELECT idTabel, idTabelRow, idPerson, idPaymentType, h1, h2, h3, h4, h5, h6, h7, h8, h9, h10,
h11, h12, h13, h14, h15, h16, h17, h18, h19, h20,
h21, h22, h23, h24, h25, h26, h27, h28, h29, h30, h31
FROM TabelRow
WHERE idTabel = @idTabel
|
Разница очевидна: запрос в модели А значительно сложнее. Это еще сильнее проявляется для запросов, модифицирующих данные: если для модели строк подходят стандартные механизмы сохранения данных таблицы (грида), то для модели фактов придется изобретать свои методы – задача, конечно же, решаемая, но все же не типовая. Причем именно усложнение программирования модификации данных здесь позволяют сделать выбор в пользу модели Б, ведь, как уже говорилось выше, модели эквивалентны –можно создать представление (view) и пользоваться в модели А коротким запросом, как в модели Б.
Критерий объема хранимой информации
В современных условиях дисковое пространство – не самый дорогой ресурс. Тем не менее, бывают ситуации, когда желательно минимизировать объем хранимой информации. Расчет размера памяти, необходимого для хранения одной строки табеля (для 30-дневного месяца)
30*(sizeof(idTabel) + sizeof(idPaymentType) + sizeof(idPerson) + sizeof(Hours) + sizeof(Date));
|
sizeof(idTabel) + sizeof(idPaymentType) + sizeof(idPerson) + 30*sizeof(Hours).
|
При любых размерах полей таблицы выигрыш будет за моделью Б. Если предположить, что все поля одного размера, то речь идет о соотношении 150:33). При этом прошу заметить, что из расчета исключены искусственные ключи таблицы (принимая во внимание существование спора «суррогатные vs. естественные ключи»). Если их включить в расчет, то соотношение еще больше будет в пользу модели Б. Некоторую поправку может внести соображение, что не все ячейки табеля заполнены. Например, человек вышел работать сверхурочно только один раз в месяц. Для таблицы TabelFact модели А это означает просто отсутствие строк (следовательно, экономию памяти). Однако практика показывает, что пустых ячеек в табелях не более половины.
Критерий простоты составления запросов для отчетных (аналитических) систем.
Невозможно предусмотреть все возможные запросы, которые могут понадобиться для составления отчетов по данным табельного учета. Тем не менее, логично предположить, что большинство запросов будут содержать фильтр данных по датам. Как это будет выглядеть для альтернативных моделей:
SELECT *
FROM TabelFact
WHERE Date>=@BeginDate AND Date<=@EndDate
|
SELECT *
FROM (
SELECT TabelRow.idPaymentType, Calendar.Date, TabelRow.idPerson,
TabelRow.idTabel, TabelRow.h1 AS Hours
FROM Tabel
INNER JOIN TabelRow ON Tabel.idTabel = TabelRow.idTabel
INNER JOIN Calendar ON YEAR(Calendar.Date) = YEAR(Tabel.Date)
AND MONTH(Calendar.Date) = MONTH(Tabel.Date) AND Calendar.Day = 1
UNION
SELECT TabelRow.idPaymentType, Calendar.Date, TabelRow.idPerson,
TabelRow.idTabel, TabelRow.h2 AS Hours
FROM Tabel
INNER JOIN TabelRow ON Tabel.idTabel = TabelRow.idTabel
INNER JOIN Calendar ON YEAR(Calendar.Date) = YEAR(Tabel.Date)
AND MONTH(Calendar.Date) = MONTH(Tabel.Date) AND Calendar.Day = 2
UNION
...
UNION
SELECT TabelRow.idPaymentType, Calendar.Date, TabelRow.idPerson,
TabelRow.idTabel, TabelRow.h31 AS Hours
FROM Tabel
INNER JOIN TabelRow ON Tabel.idTabel = TabelRow.idTabel
INNER JOIN Calendar ON YEAR(Calendar.Date) = YEAR(Tabel.Date)
AND MONTH(Calendar.Date) = MONTH(Tabel.Date) AND Calendar.Day = 31 ) AS t
WHERE Date>=@BeginDate AND Date<=@EndDate
|
Видно, что с точностью до наоборот повторяется ситуация с SELECT-запросами строк табеля. Теперь запрос в модели фактов выглядит намного лаконичнее. Опять же ситуацию можно поправить, используя представление (view) в случае выбора модели Б.
С точки зрения аналитических (OLAP) систем, известно, что для построения OLAP-куба необходима схема типа «снежинка», центром которой является таблица фактов, содержащая значения мер куба. Модель А идеально соответствует этому требованию, а в модели Б понадобиться построение unpivot-view для таблицы TabelRow.
Таким образом, по данному критерию привлекательнее выглядит модель А, однако в случае выбора модели Б проблема решается построение всего одного представления.
Критерий производительности
Исследование вариантов схемы данных будет неполным без рассмотрения вопросов производительности. На момент принятия решения у меня не было данных для тестирования производительности – пришлось их генерировать, в настоящий момент – программа работает три года, накопилось достаточно информации, поэтому приведу факты по реальной базе данных:
| Показатель |
Модель А,таблица TabelFact |
Модель Б,таблица TabelRow |
| Число строк в таблице |
5 млн. |
300 тыс. |
| Время выполнения запроса на получение деталей одного табеля |
30ms |
5ms |
| Время на изменение значения одного факта |
12ms |
2ms |
| Время расчета OLAP-куба |
1мин. |
4мин. |
Таблица 1. Характеристики базы данных табельного учета
Таблица TabelFact создана и рассчитана специально для настоящего исследования, в реальной базе ее нет. При развороте должно было получиться примерно 300*30 –9 млн. строк, но как уже говорилось – примерно половина из них пустые (нулевые). Заполнение таблицы на сервере заняло 5 минут. Резервная копия базы возросла при этом с 300 до 500 Мб.
Разница в скорости выполнения запросов учетной системы вполне предсказуема и определяется в основном количеством записей в таблицах.
Описание структуры OLAP-куба выходит за рамки обсуждаемой темы, важно соотношение времени его расчета для разных моделей.
Осталось выяснить, насколько эти показатели соответствуют характеру требований производительности:
- Для учетной системы требования полностью удовлетворены как при выборе модели фактов, так и при выборе модели строк. 6-кратное различие в скорости запросов на выбор данных одного табеля и изменение одного факта – некритично, если принимать во внимание, что в самом худшем варианте задержка составляет 30ms (0,03 секунды).
- С точки зрения отчетных систем, надо принять во внимание такую особенность предметной области, как периодический характер составления отчетности. Табели заполняются раз в месяц, компактно по времени (после 25-го числа, должны быть поданы до конца месяца), в период подачи документов сводная информации по данным текущего месяца не требуется. Как следствие, достаточно раз в месяц рассчитывать OLAP-куб (4 минуты – не проблема при такой периодичности). Если волнуют проблемы производительности построения отчетов на основании unpivot-представления – можно раз в месяц рассчитывать таблицу TabelFact и в отчетах использовать уже ее.
Заключение
Результаты проведенного исследования, конечно же, говорят в пользу модели Б – «модели строк»: программировать учетную систему проще, запросы для нее будут работать быстрее, данные займут меньше места, проблему падения производительности в отчетной системе можно легко решить при помощи предварительного ежемесячного расчета таблицы фактов.
Можно ли применить результаты данного исследования при проектировании других баз? В самой предметной области есть одна особенность, без которой модель строк вообще бы не рассматривалась: в любом месяце года от 28-и до 31-го дня. Соответственно, если в предметной области факты группируются на основании признака, возможные значения которого ограничены и заранее известны, то в этом случае возможно рассмотрение альтернативных схем данных, переход между которыми осуществляется на основе pivot-unpivot преобразований. Общий характер и последовательность исследования по приведенным критериям, применимы для любой схемы данных.
Любой из материалов, опубликованных на этом сервере, не может быть воспроизведен в какой бы
то ни было форме и какими бы то ни было средствами без письменного разрешения владельцев авторских
прав.
Copyright © 1994-2016 ООО "К-Пресс"
