 |
Технология Клиент-Сервер 2007'1
|
|
|
Удаленный вызов процедур и рандеву
Авторы: Часть главы из книги Грегори Р. Эндрюса «Основы многопоточного
параллельного и распределенного программирования»
изд. Вильямс
ISBN 5-8459-0388-2
Опубликовано: 19.04.2007
Передача сообщений идеально подходит для программирования фильтров и взаимодействующих равных, поскольку в этих случаях процессы отсылают данные по каналам связи в одном направлении. Как было показано, передача сообщений применяется также в программировании клиентов и серверов. Но двусторонний поток данных между клиентом и сервером приходится программировать с помощью двух явных передач сообщений по двум отдельным каналам. Кроме того, каждому клиенту нужен отдельный канал ответа; все это ведет к увеличению числа каналов.
ПРИМЕЧАНИЕ
Взаимодействующие равные — одна из парадигм взаимодействия. Она встречается в распределенных программах, в которых несколько процессов для решения задачи выполняют один и тот же код и обмениваются сообщениями. Взаимодействующие равные используются для реализации распределенных параллельных программ, особенно при итеративном параллелизме и децентрализованном принятии решений в распределенных системах.
|
В данной главе рассмотрены две дополнительные программные нотации — удаленный вызов процедур (remote procedure call — RPC) и рандеву, идеально подходящие для программирования взаимодействий типа “клиент-сервер”. Они совмещают свойства мониторов и синхронной передачи сообщений. Как и при использовании мониторов, модуль или процесс экспортирует операции, а операции запускаются с помощью оператора call. Как и синхронизированная отправка сообщения, выполнение оператора call приостанавливает работу процесса. Новизна RPC и рандеву состоит в том, что они работают с двусторонним каналом связи: от процесса, вызывающего функцию, к процессу, который обслуживает вызов, и в обратном направлении. Вызвавший функцию процесс ждет, пока будет выполнена необходимая операция и возвращены ее результаты.
RPC и рандеву различаются способом обслуживания вызовов операций. Первый способ — для каждой операции объявлять процедуру и для обработки вызова создавать новый процесс (по крайней мере, теоретически). Этот способ называется удаленным вызовом процедуры (RPC), поскольку вызывающий процедуру процесс и ее тело могут находиться на разных машинах. Второй способ — назначить встречу (рандеву) с существующим процессом. Рандеву обслуживается с помощью оператора ввода (приема), который ждет вызова, обрабатывает его и возвращает результаты. (Иногда этот тип взаимодействия называется расширенным рандеву в отличие от простого рандеву, при котором встречаются операторы передачи и приема при синхронной передаче сообщений.)
Ниже описаны типичные примеры программной нотации для RPC и рандеву, продемонстрировано их использование. Как упоминалось, эти методы упрощают программирование взаимодействий типа “клиент-сервер”. Их можно использовать и при программировании фильтров, но мы увидим, что это трудоемкое занятие, поскольку ни RPC, ни рандеву напрямую не поддерживают асинхронную связь. К счастью, эту проблему можно решить, если объединить RPC, рандеву и асинхронную передачу сообщений в мощный, но достаточно простой язык, представленный в разделе 8.3.
Использование нотаций, их преимущества и недостатки демонстрируются на нескольких примерах. В некоторых из них использованы задачи, рассмотренные ранее, что помогает сравнить различные виды передачи сообщений. Некоторые задачи приводятся впервые и демонстрируют применимость RPC и рандеву в программировании взаимодействий типа “клиент-сервер”. Например, в разделе 8.4 показано, как реализовать инкапсулированную базу данных и дублирование файлов. В разделах 8.5–8.7 дан обзор механизмов распределенного программирования трех языков: Java (RPC), Ada (рандеву) и SR (совместно используемые примитивы).
8.1. Удаленный вызов процедур
В главе 5 были использованы два типа компонентов программ: мониторы и процессы. Мониторы инкапсулируют разделяемые переменные; процессы взаимодействуют и синхронизируются, вызывая процедуры монитора. Предполагается, что процессы и мониторы программы находятся в общем адресном пространстве.
При удаленном вызове процедуры (RPC) используется только один из этих компонентов — модуль, в котором есть и процессы, и процедуры. Модули могут находиться в разных адресных пространствах, например, на различных узлах сети. Процессы внутри модуля могут разделять переменные и вызывать процедуры, объявленные в этом модуле. Но процессы из одного модуля могут связываться с процессами в другом модуле, только вызывая процедуры, экспортируемые другим модулем.
ПРИМЕЧАНИЕ
Процессы в одном адресном пространстве часто называются облегченными потоками. Термин поток показывает, что каждый из процессов имеет отдельную последовательность выполнения, а облегченный — что при переключении контекста такому процессу нужно сохранять относительно мало информации. В отличие от облегченных, такие “тяжеловесные” процессы, как процессы в ОС UNIX, имеют собственное адресное пространство. Переключение контекста таких “тяжеловесных” процессов требует сохранения и загрузки таблиц управления памятью и регистров.
|
Модуль состоит из двух частей, которые позволяют отличать процедуры, локальные для модуля, от обеспечивающих каналы взаимодействия. Часть модуля с определениями содержит заголовки операций, которые можно вызывать из других модулей. Тело содержит процедуры, реализующие эти операции; оно также может содержать локальные переменные, код инициализации, локальные процедуры и процессы. Модуль имеет такой вид.
module mname
заголовки экспортируемых операций;
body
объявления переменных;
код инициализации;
процедуры для экспортируемых операций;
локальные процедуры и процессы;
end mname
|
Чтобы отличать локальные процессы от процессов экспортируемых операций (см. ниже), локальные процессы называются фоновыми.
Заголовок операции opname задается декларацией op:
op opname(параметры) [returns результат]
|
Параметры и раздел returns указывают типы и, возможно, имена параметров и возвращаемого значения. Раздел returns необязателен. При использовании удаленного вызова процедур операция задается в виде proc.
proc opname(параметры) returns идентификатор результата
объявления локальных переменных;
операторы
end
|
Таким образом, декларация proc аналогична процедуре, но типы параметров и результата в ней повторять не обязательно, поскольку они указаны в объявлении op. (Процедуру можно рассматривать просто как сокращенную форму декларации op и proc.)
Как и при использовании мониторов, процесс (или процедура) одного модуля вызывает процедуру из другого модуля, выполняя код:
call mname.opname(аргументы)
|
Ключевое слово call не обязательно для вызовов процедур, а в вызовах функций оно не используется. Для локальных вызовов имя модуля можно не указывать.
Реализация межмодульного вызова отличается от реализации локального вызова, поскольку модули могут находиться в разных адресных пространствах. В частности, вызов обслуживается новым процессом, а аргументы передаются в виде сообщений от вызывающего процесса к серверному. Вызывающий процесс ждет, пока процесс-сервер выполняет тело процедуры, реализующей операцию opname. Возвращаясь из opname, сервер отсылает результаты и возвращаемое значение вызвавшему процессу, а затем завершается. После получения результатов вызывавший процесс продолжается. Передача и получение результатов не программируются, поскольку происходят неявно.
Если вызывающий процесс и процедура находятся в одном адресном пространстве, часто можно не создавать новый процесс для обслуживания удаленного вызова, поскольку вызывающий процесс на некоторое время становится сервером и выполняет тело процедуры. Но в общем случае вызов будет удаленным, поэтому процесс нужно создавать или выделять из уже существующего набора серверов.
Следующая диаграмма иллюстрирует взаимодействие между процессом, вызывающим процедуру, и процессом-сервером.
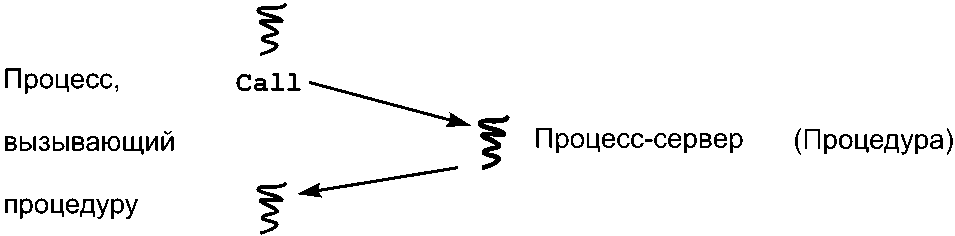
Ось времени проходит по рисунку вниз, волнистые линии показывают ход выполнения процесса. Когда вызывающий процесс доходит до оператора call, он приостанавливается, пока сервер выполняет тело вызванной процедуры. После того как сервер возвратит результаты, вызвавший процесс продолжается.
8.1.1. Синхронизация в модулях
Сам по себе RPC — это механизм взаимодействия. Хотя вызывающий процесс синхронизируется со своим сервером, единственная роль сервера — действовать от имени вызывающего процесса. Теоретически все происходит так же, как если бы вызывающий процесс сам выполнял процедуру, поэтому синхронизация между вызывающим процессом и сервером происходит неявно.
Нужен также способ обеспечивать взаимно исключающий доступ процессов модуля к разделяемым переменным и их синхронизацию. Процессы модуля — это процессы-серверы, выполняющие удаленные вызовы, и фоновые процессы, объявленные в модуле.
Существует два подхода к обеспечению синхронизации в модулях. Первый — считать, что все процессы одного модуля должны выполняться со взаимным исключением, т.е. в любой момент времени может быть активен только один процесс. Этот метод аналогичен неявному исключению, определенному для мониторов, и гарантирует защиту разделяемых переменных от одновременного доступа. Но при этом нужен способ программирования условной синхронизации процессов, для чего можно использовать условные переменные (как в мониторах) или семафоры.
Второй подход — считать, что все процессы выполняются параллельно, и явным образом программировать взаимное исключение и условную синхронизацию. Тогда каждый модуль сам становится параллельной программой, и можно применить любой описанный метод. Например, можно использовать семафоры или локальные мониторы. В действительности, как будет показано в этой главе ниже, можно использовать рандеву (или даже передачу сообщений).
Программа, содержащая модули, выполняется, начиная с кода инициализации каждого из модулей. Коды инициализации разных модулей могут выполняться параллельно при условии, что в них нет удаленных вызовов. Затем запускаются фоновые процессы. Если исключение неявное, то одновременно в модуле выполняется только один фоновый процесс; когда он приостанавливается или завершается, может выполняться другой фоновый процесс. Если процессы модуля выполняются параллельно, то все фоновые процессы модуля могут начинаться одновременно.
У неявной формы исключения есть два преимущества. Первое — модули проще программировать, поскольку разделяемые переменные автоматически защищаются от конфликтов одновременного доступа. Второе — реализация модулей, выполняемых на однопроцессорных машинах, может быть более эффективной. Дело в том, что переключение контекста происходит только в точках входа, возврата или приостановки процедур или процессов, а не в произвольных точках, когда регистры могут содержать результаты промежуточных вычислений.
С другой стороны, предположение о параллельном выполнении процессов является более общим. Параллельное выполнение — это естественная модель для программ, работающих на обычных теперь мультипроцессорах с разделяемой памятью. Кроме того, с помощью параллельной модели выполнения можно реализовать квантование времени, чтобы разделять его между процессами и “обуздывать” неуправляемые процессы (например, зациклившиеся). Это невозможно при использовании исключающей модели выполнения, если только процессы сами не освобождают процессор через разумные промежутки времени, поскольку контекст можно переключить, только когда выполняемый процесс достигает точки выхода или приостановки.
Итак, будем предполагать, что процессы внутри модуля выполняются параллельно, и поэтому необходимо программировать взаимное исключение и условную синхронизацию. В следующих двух разделах показано, как программировать сервер времени и кэширование в распределенной файловой системе с использованием семафоров.
8.1.2. Сервер времени
Рассмотрим задачу реализации сервера времени — модуля, который обслуживает работу с временными интервалами клиентских процессов из других модулей. Предположим, что в сервере времени определены две видимые операции: get_time и delay. Клиентский процесс получает время суток, вызывая операцию get_time, и блокируется на interval единиц времени с помощью операции delay. Сервер времени также содержит внутренний процесс, который постоянно запускает аппаратный таймер и при возникновении прерывания от таймера увеличивает время суток.
Листинг 8.1 содержит программу модуля сервера времени. Время суток хранится в переменной tod (time of day). Несколько клиентов могут вызывать функции get_time и delay одновременно, поэтому несколько процессов могут одновременно обслуживать вызовы. Такое обслуживание нескольких вызовов операции get_time безопасно для процессов, поскольку они просто считывают значение tod. Но операции delay и tick должны выполняться со взаимным исключением, обрабатывая очередь “уснувших” клиентских процессов napQ. Вместе с тем, в операции delay присваивание значения переменной wake_time может не быть критической секцией, поскольку переменная tod — это единственная разделяемая переменная, которая просто считывается. Кроме того, увеличение tod в процессе Clock также может не быть критической секцией, поскольку только процесс Clock может присваивать значение этой переменной.
 Листинг 8.1. Модуль сервера времени
Листинг 8.1. Модуль сервера времени
module TimeServer
op get_time() returns int; # получить время суток
op delay(int interval); # ждать interval “тиков”
body
int tod = 0; # время суток
sem m = 1; # семафор взаимного исключения
sem d[n] = ([n] 0); # скрытые семафоры задержек
queue of (int waketime, int process_id) napQ;
## когда m == 1, tod < waketime для приостановленных процессов
proc get_time() returns time {
time = tod;
}
proc delay(interval) { # предполагается, что interval > 0
int waketime = tod + interval;
P(m);
вставить(waketime, myid) в подходящую позицию napQ;
V(m);
P(d[myid]); # ждать запуска
}
process Clock {
запустить аппаратный таймер;
while (true) {
ждать прерывания, затем перезапустить аппаратный таймер;
tod = tod+1;
P(m);
while (tod >= наименьшее waketime из napQ) {
удалить (waketime, id) из napQ;
V(d[id]); # разбудить процесс id
}
V(m);
}
}
end TimeServer
|
Предполагается, что значение переменной myid в процессе delay является уникальным целым числом в промежутке от 0 до n-1. Оно используется для указания скрытого семафора, на котором приостановлен клиент. После прерывания от часов процесс Clock выполняет цикл проверки очереди napQ; он сигнализирует соответствующему семафору задержки, когда заданный интервал задержки заканчивается. Может быть несколько процессов, ожидающих одно и то же время запуска, поэтому используется цикл.
8.1.3. Кэширование в распределенной файловой системе
Рассмотрим упрощенную версию задачи, возникающей в распределенных файловых системах и базах данных. Предположим, что прикладные процессы выполняются на рабочей станции, а файлы данных хранятся на файловом сервере. Не будем останавливаться на том, как файлы открываются и закрываются, а сосредоточимся на их чтении и записи. Когда прикладной процесс хочет получить доступ к файлу, он вызывает процедуру read или write в локальном модуле FileCache. Будем считать, что приложения читают и записывают массивы символов (байтов). Иногда это может быть несколько символов, а иногда — тысячи.
Файлы хранятся на диске файлового сервера в блоках фиксированного размера (например, по 1024 байт). Модуль FileServer управляет доступом к блокам диска. Для чтения и записи целых блоков он обеспечивает две операции, readblk и writeblk.
Модуль FileCache кэширует последние считанные блоки данных. Когда приложение запрашивает чтение части файла, модуль FileCache сначала проверяет, есть ли эти данные в его кэш-памяти. Если есть, то он может быстро обработать запрос клиента. Если нет, он должен вызвать процедуру readblk из модуля FileServer для получения блоков диска с запрашиваемыми данными. (Модуль FileCache может производить упреждающее чтение, если определит, что происходят последовательные обращения к файлу. А это бывает часто.)
Запросы на запись обрабатываются аналогично. Когда приложение вызывает операцию write, данные сохраняются в блоке в локальной кэш-памяти. Когда блок заполнен или затребован для другого запроса, модуль FileCache вызывает операцию writeblk модуля FileServer для записи блока на диск. (Модуль FileCache также может использовать стратегию сквозной записи, при которой writeblk вызывается после каждого запроса на запись. Использование сквозной записи гарантирует сохранение данных на диске при завершении операции write, но замедляет ее выполнение.)
В листинге 8.2 показаны схемы обоих модулей. Каждый модуль выполняется на отдельной машине. Вызовы модуля FileCache из приложения фактически являются локальными, а вызовы в этом модуле операций из модуля FileServer — удаленными. Модуль FileCache является сервером для прикладных процессов, а FileServer — для многих клиентов модуля FileCache, по одному на рабочую станцию.
Листинг 8.2.1. Распределенная файловая система: файловый кэш
module FileCache # расположен на бездисковых станциях
op read(int count; result char buffer[*]);
op write(int count; char buffer[]);
body
кэш файловых блоков;
переменные для хранения информации дескриптора файла;
семафоры для синхронизации доступа к кэш-памяти (если нужны);
proc read(count,buffer)
{
if (нужные данные не находятся в кэш-памяти)
{
выбрать блок кэш-памяти для использования;
if (необходимо записать блок кэш-памяти)
FileServer.writeblk(...);
FileServer.readblk(...);
}
buffer = соответствующие count байт из блока кэш-памяти;
}
proc write(count,buffer)
{
if (соответствующий блок не находится в кэш-памяти)
{
выбрать блок кэш-памяти для использования;
if (необходимо записать блок кэш-памяти)
FileServer.writeblk(...);
}
блок кэш-памяти = count байт из buffer;
}
end FileCache
|
Листинг 8.2.2. Распределенная файловая система: файловый сервер
module FileServer # расположен на файловом сервере
op readblk(int fileid, offset; result char blk[1024]);
op writeblk(int fileid, offset; char blk[1024]);
body
кэш-память дисковых блоков;
очередь запросов на доступ к диску;
семафоры для синхронизации доступа к кэш-памяти и очереди;
# N.B. код синхронизации не показан
proc readblk(fileid, offset, blk)
{
if (нужный блок не находится в кэш-памяти)
{
сохранить запрос на чтение в очереди диска;
ждать выполнения операции чтения;
}
blk = подходящий дисковый блок;
}
proc writeblk(fileid, offset, blk)
{
выбрать блок из кэш-памяти;
if (необходимо записать выбранный блок)
{
сохранить запрос на запись в очереди диска;
ждать записи блока на диск;
}
блок кэш-памяти = blk;
}
process DiskDriver
{
while (true)
{
ждать запроса на доступ к диску;
начать дисковую операцию; ждать прерывания;
запустить процесс, ожидающий завершения данного запроса;
}
}
end FileServer
|
При условии, что у каждого прикладного процесса есть отдельный модуль FileCache, внутренняя синхронизация в этом модуле не нужна, поскольку в любой момент времени может выполняться только один запрос чтения или записи. Но если несколько прикладных процессов используют один модуль FileCache или в нем есть процесс, который реализует упреждающее чтение, то для обеспечения взаимно исключающего доступа к разделяемой кэш-памяти в этом модуле необходимо использовать семафоры.
В модуле FileServer внутренняя синхронизация необходима, поскольку он совместно используется несколькими модулями FileCache и содержит внутренний процесс DiskDriver. В частности, необходимо синхронизировать процессы, обрабатывающие вызовы операций writeblk и readblk, и процесс DiskDriver, чтобы защитить доступ к кэш-памяти дисковых блоков и планировать операции доступа к диску. В листинге 8.2 код синхронизации не показан, но его нетрудно написать <…>.
8.1.4. Сортирующая сеть из фильтров слияния
Хотя RPC упрощает программирование взаимодействий “клиент-сервер”, его неудобно использовать для программирования фильтров и взаимодействующих равных. В этом разделе еще раз рассматривается задача реализации сортирующей сети из фильтров слияния, и показан способ поддержки динамических каналов связи с помощью указателей на операции в других модулях.
Напомним, что фильтр слияния получает два входных потока и производит один выходной. Предполагается, что каждый входной поток отсортирован, и задача фильтра — объединить значения из входных потоков в отсортированный выходной. Предположим, что конец входного потока обозначен маркером EOS.
Первая проблема при программировании фильтра слияния с помощью RPC состоит в том, что RPC не поддерживает непосредственное взаимодействие процесс-процесс. Вместо этого в программе нужно явно реализовывать межпроцессное взаимодействие, поскольку для него нет примитивов, аналогичных примитивам для передачи сообщений.
Еще одна проблема — связать между собой экземпляры фильтров. Каждый фильтр должен направить свой выходной поток во входной поток другого фильтра, но имена операций, представляющих каналы взаимодействия, являются различными идентификаторами. Таким образом, каждый входной поток должен быть реализован отдельной процедурой. Это затрудняет использование статического именования, поскольку фильтр слияния должен знать символьное имя операции, которую нужно вызвать для передачи выходного значения следующему фильтру. Намного удобнее использовать динамическое именование, при котором каждому фильтру передается ссылка на операцию, используемую для вывода. Динамическая ссылка представляется мандатом доступа (capabililty), который можно рассматривать как указатель на операцию.
Листинг 8.3 содержит модуль, реализующий массив фильтров Merge. В первой строке модуля дано глобальное определение типа операций stream, получающих в качестве аргумента одно целое число. Каждый модуль экспортирует две операции, in1 и in2. Они обеспечивают входные потоки и могут использоваться другими модулями для получения входных значений. Модули экспортируют третью операцию, initialize, которую вызывает главный модуль (не показан), чтобы передать фильтру мандат доступа к используемому выходному потоку. Например, главный модуль может дать фильтру Merge[i] мандат доступа к операции in2 фильтра Merge[j] с помощью следующего кода:
call Merge[i].initialize(Merge[j].in2)
|
Предполагается, что каждый модуль инициализируется до начала любых операций вывода.
Листинг 8.3. Фильтры для сортировки слиянием, использующие RPC
optype stream = (int); # тип операций с потоком данных
module Merge[i = 1 to n]
op in1 stream, in2 stream; # входные потоки
op initialize(cap stream); # ссылка на выходной поток
body
int v1, v2; # входные значения из потоков 1 и 2
cap stream out; # мандат доступа ко входному потоку
sem empty1 = 1, full1 = 0, empty2 = 1, full2 = 0;
proc initialize(output)
{ # обеспечить выходной поток
out = output;
}
proc in1(value1)
{ # создать новое значение для потока 1
P(empty1); v1 = value1; V(full1);
}
proc in2(value2)
{ # создать новое значение для потока 2
P(empty2); v2 = value2; V(full2);
}
process M
{
P(full1); P(full2); # ожидать два входных значения
while (v1 != EOS and v2 != EOS)
if (v1 <= v2) { call out(v1); V(empty1); P(full1); }
else # v2 < v1 { call out(v2); V(empty2); P(full2); }
# считать остаток непустого входного потока
if (v1 == EOS)
while (v2 != EOS) { call out(v2); V(empty2); P(full2); }
else # v2 == EOS
while (v1 != EOS) { call out(v1); V(empty1); P(full1); }
call out(EOS); # присоединить маркер конца
}
end Merge
|
Остальная часть модуля аналогична процессу Merge. Переменные v1 и v2 соответствуют одноименным переменным в листинге 7.2, а процесс M повторяет действия процесса Merge. Однако процесс M для помещения следующего значения в выходной канал out использует оператор call, а не send. Процесс M для получения следующего числа из соответствующего входного потока использует операции семафора. Внутри модуля неявные серверные процессы, которые обрабатывают вызовы операций in1 и in2, являются производителями, а процесс M — потребителем. <…>
Сравнение программ в листингах 8.3 и 7.2 четко показывает недостатки PRC по отношению к передаче сообщений при программировании фильтров. Хотя процессы в обоих листингах похожи, для работы программы 8.3 необходимы дополнительные фрагменты. В результате программа работает примерно с такой же производительностью, но, используя RPC, программист должен написать намного больше.
8.1.5. Взаимодействующие равные: обмен значений
RPC можно использовать и для программирования обмена информацией, возникающего при взаимодействии равных процессов. Однако по сравнению с использованием передачи сообщений программы получаются громоздкими. В качестве примера рассмотрим взаимодействие двух процессов из разных модулей, которым необходимо обменять значения. Чтобы связаться с другим модулем, каждый процесс должен использовать RPC, поэтому каждый модуль должен экспортировать процедуру, вызываемую из другого модуля.
В листинге 8.4 показан один из способов программирования обмена значений. Для пересылки значения из одного модуля в другой используется операция deposit. Для реализации обмена каждый из рабочих процессов выполняет два шага: передает значение myvalue в другой модуль, а затем ждет, пока другой процесс не присвоит это значение своей локальной переменной. (Выражение 3-i в каждом модуле задает номер модуля, с которым нужно взаимодействовать; например, модуль 1 должен обратиться к модулю с номером 3-1, т.е. 2.) В модулях используется семафор ready; он гарантирует, что рабочий процесс не получит доступ к переменной othervalue до того, как ей будет присвоено значение в операции deposit.
Листинг 8.4. Обмен значений с использованием RPC
module Exchange[i = 1 to 2]
op deposit(int);
body
int othervalue;
sem ready = 0; # используется для сигнализации
proc deposit(other)
{ # вызывается из другого модуля
othervalue = other; # сохранить полученное значение
V(ready); # разрешить процессу Worker забрать его
}
process Worker
{
int myvalue;
call Exchange[3-i].deposit(myvalue); # отослать другому
P(ready); # ждать получения значения из другого процесса
...
}
end Exchange
|
8.2. Рандеву
Сам по себе RPC обеспечивает только механизм межмодульного взаимодействия. Внутри модуля все равно нужно программировать синхронизацию. Иногда приходится определять дополнительные процессы, чтобы обрабатывать данные, передаваемые с помощью RPC.
Рандеву сочетает взаимодействие и синхронизацию. Как и при PRC, клиентский процесс вызывает операцию с помощью оператора call. Но операцию обслуживает уже существующий, а не вновь создаваемый процесс. В частности, процесс-сервер использует оператор ввода, чтобы ожидать и затем действовать в пределах одного вызова. Следовательно, операции обслуживаются по одной, а не параллельно.
Часть модуля с определениями содержит объявления заголовков операций, экспортируемых модулем, но тело модуля теперь состоит из одного процесса, обслуживающего операции. (В следующем разделе это обобщается.) Используются также массивы операций, объявляемые с помощью добавления диапазона значений индекса к имени операции.
8.2.1. Операторы ввода
Предположим, что модуль экспортирует следующую операцию.
op opname(типы параметров);
|
Процесс-сервер этого модуля осуществляет рандеву с процессом, вызвавшим операцию opname, выполняя оператор ввода. Простейший вариант оператора ввода имеет вид:
in opname(параметры) -> S; ni
|
Область между ключевыми словами in и ni называется защищенной операцией. Защита именует операцию и обеспечивает идентификаторы для ее параметров (если они есть). S обозначает список операторов, обслуживающих вызов операции. Область видимости параметров – вся защищенная операция, поэтому операторы из S могут считывать и записывать значения параметров.
Оператор ввода приостанавливает работу процесса-сервера до появления хотя бы одного вызова операции opname. Затем процесс выбирает самый старый из ожидающих вызовов, копирует значения его аргументов в параметры, выполняет список операторов S и, наконец, возвращает результирующие параметры вызвавшему процессу. В этот момент и процесс-сервер, выполняющий in, и клиентский процесс, который вызывал opname, могут продолжать работу.
Следующая диаграмма отражает отношения между вызывающим и серверным процессами. Время возрастает в диаграмме сверху вниз, а волнистые линии показывают, когда процесс выполняется.
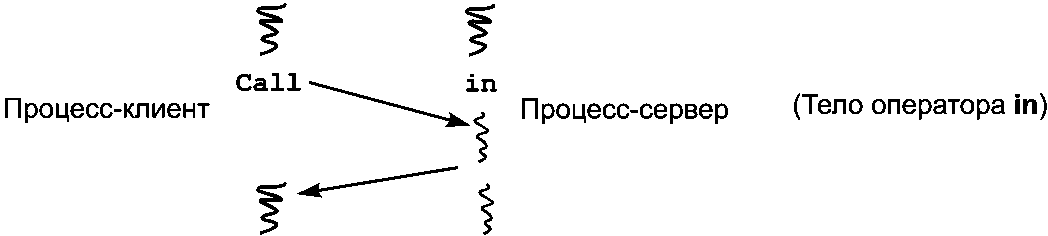
Как и при использовании RPC, процесс, достигший оператора call, приостанавливается и возобновляется после того, как процесс-сервер выполнит вызванную операцию. Однако при использовании рандеву сервер является активным процессом, который работает и до, и после обслуживания удаленного вызова. Как было указано выше, сервер также задерживается, достигая оператора in, если нет ожидающих выполнения вызовов. Читателю было бы полезно сравнить приведенную диаграмму с аналогичной диаграммой для RPC.
Приведенный выше оператор ввода обслуживает одну операцию. Защищенное взаимодействие полезно тем, что позволяет процессу ожидать выполнения одного из нескольких условий. Можно объединить рандеву и защищенное взаимодействие, используя общую форму оператора ввода.
in op1(параметры1) and B1 by e1 -> S1;
[] ...
[] opn(параметрыn) and Bn by en -> Sn;
ni
|
Каждая ветвь оператора in является защищенной операцией. Часть кода перед символами -> называется защитой; каждое Si обозначает последовательность операторов. Защита содержит имя операции, ее параметры, необязательное условие синхронизации «and Bi» и необязательное выражение планирования «by ei». В этих условиях и выражениях могут использоваться параметры операции.
В языке Ada (раздел 8.6) поддержка рандеву реализована с помощью оператора accept, а защищенное взаимодействие — оператора select. Оператор accept очень похож на in в простой форме, а оператор select — на общую форму in. Но in в общей форме предоставляет больше возможностей, чем select, поскольку в операторе select нельзя использовать аргументы операции и выражения планирования. Эти различия обсуждаются в разделе 8.6.
Защита в операторе ввода пропускает, если была вызвана операция и соответствующее условие синхронизации истинно (или отсутствует). Область видимости параметров включает всю защищенную операцию, поэтому условие синхронизации может зависеть от значений параметров, т.е. от значений аргументов в вызове операции. Таким образом, один вызов операции может привести к тому, что защита пропустит, а другой — что не пропустит.
Здесь и далее под словами «защита пропускает» имеется в виду, что производится проверка некоторых условий, и в случае успеха, выполнение операции, а при неудаче – выбор другой операции, условие которой истинно или приостановка исполнения до момента, когда условие станет истинным. – прим.ред.
Выполнение оператора in приостанавливает работу процесса, пока не пропустит какая-нибудь защита. Если пропускают несколько защит (и нет условий планирования), то оператор in обслуживает первый (по времени) вызов, пропускаемый защитой. Аргументы этого вызова копируются в параметры, и затем выполняется соответствующий список операторов. По завершении операторов результирующие параметры и возвращаемое значение (если есть) возвращаются процессу, вызвавшему операцию. В этот момент операторы call и in завершаются.
Выражение планирования используется для изменения порядка обработки вызовов, используемого по умолчанию (первым обслуживается самый старый вызов). Если есть несколько вызовов, пропускаемых защитой, то первым обслуживается самый старый вызов, у которого выражение планирования имеет минимальное значение. Как и условие синхронизации, выражение планирования может ссылаться на параметры операции, и, следовательно, его значение может зависеть от аргументов вызова операции. В действительности, если в выражении планирования используются только локальные переменные, его значение одинаково для всех вызовов и не влияет на порядок обслуживания вызовов.
Как мы увидим далее, условия синхронизации и выражения планирования очень полезны. Они используются не только в рандеву, но и в синхронной и асинхронной передаче сообщений. Например, можно позволить операторам receive задействовать свои параметры, и многие библиотеки передачи сообщений обеспечивают средства для управления порядком получения сообщений. Например, в библиотеке MPI получатель сообщения может определять отправителя и тип сообщения.
8.2.2. Примеры взаимодействий типа “клиент-сервер”
В данном разделе представлены небольшие примеры, иллюстрирующие использование операторов ввода. Вернемся к задаче реализации кольцевого буфера. Нам нужен процесс, который имеет локальный буфер на n элементов и обслуживает две операции: deposit и fetch. Вызывая операцию deposit, «вкладчик» помещает элемент в буфер, а с помощью операции fetch потребитель извлекает элемент из буфера. Как обычно, операция deposit должна задерживаться, если в буфере уже есть n элементов, а операция fetch — пока в буфере не появится хотя бы один элемент.
Листинг 8.5 содержит модуль, реализующий кольцевой буфер. Процесс Buffer объявляет локальные переменные, которые представляют буфер, и затем циклически выполняет оператор ввода. На каждой итерации процесс Buffer ждет вызова операции deposit или fetch. Условия синхронизации в защитах обеспечивают необходимые задержки операций deposit и fetch.
Листинг 8.5. Реализация кольцевого буфера с помощью рандеву
module BoundedBuffer
op deposit(typeT), fetch(result typeT);
body
process Buffer
{
typeT buf[n];
int front = 0, rear = 0, count = 0;
while (true)
in deposit(item) and count < n ->
buf[rear] = item;
rear = (rear + 1) mod n; count = count + 1;
[] fetch(item) and count > 0 ->
item = buf[front];
front = (front + 1) mod n; count = count - 1;
ni
}
end BoundedBuffer
|
Еще один пример: листинг 8.6 содержит модуль, реализующий централизованное решение задачи об обедающих философах. Структура процесса Waiter аналогична структуре процесса Buffer. Вызов операции getforks может быть обслужен, если ни один из соседей не ест, а вызов операции relforks — всегда. Философ передает свой индекс i процессу Waiter, который использует этот индекс в условии синхронизации защиты для getforks. Предполагается, что в этой защите вызовы функций left(i) и right(i) возвращают индексы соседей слева и справа от философа Philosopher[i].
Задача об обедающих философах
Задача об обедающих философах была сформулирована Дейкстрой следующим образом. Пять философов, обитающих в одном пансионе, периодически посещают столовую. В столовой вокруг круглого стола стоит пять стульев, по одному на каждого философа, а на столе лежат пять вилок. В центре стола находится блюдо со спагетти, для поедания которых каждому философу необходимы две вилки (странные люди философы!). Закончив еду, философ кладет вилки и снова предается размышлениям.
В этой задаче есть две опасные ситуации. Первая – проблема «заговора соседей», когда один из философов постоянно голодает из-за того, что соседи забирают то одну, то другую вилку. Эту задачу можно решить с помощью определенной модели поведения философа.
Вторая – проблема «голодной смерти», когда все пять философов сходятся за столом одновременно и никто из них не может есть, так как не имеет двух вилок (а философы упрямы, и никто из них вилку соседу не отдаст).
Для решения этих проблем вводится дополнительная сущность – слуга, или официант, следящий за тем, чтобы философы никогда не собирались в столовой впятером.
Листинг 8.6. Централизованное решение задачи об обедающих философах на основе рандеву
module Table
op getforks(int), relforks(int);
body
process Waiter
{
bool eating[5] = ([5] false);
while (true)
in getforks(i) and not (eating[left(i)]
and not eating[right(i)] ->
eating[i] = true;
[] relforks(i) ->
eating[i] = false;
ni
}
end Table
process Philosopher[i = 0 to 4]
{
while (true)
{
call getforks(i);
поесть;
call relforks(i);
поразмышлять;
}
}
|
Листинг 8.7 содержит модуль сервера времени <…>. Операции get_time и delay экспортируются для клиентов, а tick — для обработчика прерывания часов. В листинге 8.7 аргументом операции delay является время, в которое должен быть запущен клиентский процесс. Клиентский интерфейс данного модуля несколько отличается от интерфейса, приведенного в листинге 8.1. Клиентские процессы должны передавать время запуска, чтобы для управления порядком обслуживания вызовов delay можно было использовать условие синхронизации. В программе с применением рандеву процесс Timer может не поддерживать очередь приостановленных процессов; вместо этого приостановленными являются те процессы, время запуска которых еще не пришло. (Их вызовы остаются в очереди канала delay.)
Листинг 8.7. Сервер времени с использованием рандеву
module TimeServer
op get_time() returns int;
op delay(int);
op tick(); # вызывается обработчиком прерывания часов
body TimeServer
process Timer
{
int tod = 0; # время суток
while (true)
in get_time() returns time -> time = tod;
[] delay(waketime) and waketime <= tod -> skip;
[] tick() -> { tod = tod+1; ia?acaionoeou oaeia?; }
ni
}
end TimeServer
|
В последнем примере наряду с условием синхронизации используется выражение планирования. В листинге 8.8 показан модуль для распределения ресурсов по принципу “кратчайшее задание”. Процесс SJN, как и процесс Timer, может не поддерживать внутренние очереди. Вместо этого он просто откладывает прием вызовов request до освобождения ресурса, а затем выбирает вызовы с наименьшим значением аргумента, соответствующего time.
Листинг 8.8. Распределение ресурсов по принципу “кратчайшее задание” с помощью рандеву
module SJN_Allocator
op request(int time), release();
body
process SJN
{
bool free = true;
while (true)
in request(time) and free by time -> free = false;
[] release() -> free = true;
ni
}
end SJN_Allocator
|
8.2.3. Сортирующая сеть из фильтров слияния
Рассмотрим задачу реализации сортирующей сети с использованием фильтров слияния и решим ее, используя механизм рандеву. Есть два пути. Первый — использовать два вида процессов: один для реализации фильтров слияния и один для реализации буферов взаимодействия. Между каждой парой фильтров поместим процесс-буфер, реализованный в листинге 8.5. Каждый процесс-фильтр будет извлекать новые значения из буферов между этим процессом и его предшественниками в сети фильтров, сливать их и помещать свой выход в буфер между ним и следующим фильтром сети.
Аналогично описанному сети фильтров реализованы в операционной системе UNIX, где буферы обеспечиваются так называемыми каналами UNIX. Фильтр получает входные значения, читая из входного канала (или файла), а отсылает результаты, записывая их в выходной канал (или файл). Каналы реализуются не процессами; они больше похожи на мониторы, но процессы фильтров используют их таким же образом.
Второй путь для программирования фильтров — использовать операторы ввода для извлечения входных значений и операторы call для передачи выходных. При таком подходе фильтры взаимодействуют между собой напрямую. В листинге 8.9 показан массив фильтров для сортировки слиянием, запрограммированных по второму методу. Фильтр получает значения из двух входных потоков и отсылает результаты в выходной поток. Здесь также используется динамическое именование, чтобы с помощью операции initialize дать каждому процессу мандат доступа к выходному потоку, который он должен использовать. Этот поток связан со входным потоком другого элемента массива модулей Merge. Несмотря на эти общие черты, сортировка слиянием, реализованная средствами RPC, и приведенная в листинге 8.8 совершенно разные, поскольку рандеву, в отличие от RPC, поддерживает прямую связь между процессами. Поэтому для программирования процессов-фильтров легче использовать рандеву.
Листинг 8.9. Фильтры сортировки слиянием с использованием рандеву
optype stream = (int); # тип потоков данных
module Merge[i = 1 to n]
op in1 stream, in2 stream; # входные потоки
op initialize(cap stream); # ссылка на выходной поток
body
process Filter
{
int v1, v2; # значения из входных потоков
cap stream out; # мандат доступа к выходному потоку
in initialize(c) -> out = c ni
# получить первые значения из входных потоков
in in1(v) -> v1 = v; ni
in in2(v) -> v2 = v; ni
while (v1 != EOS and v2 != EOS)
{
if (v1 <= v2)
{
call out(v1);
in in1(v) -> v1 = v; ni
}
else
{
call out(v2);
in in2(v) -> v2 = v; ni
}
}
# получить оставшиеся значения из непустого входного потока
if (v1 == EOS)
{
while (v2 != EOS)
{
call out(v2);
in in2(v) -> v2 = v; ni
}
}
else
{
while (v1 != EOS)
{
call out(v1);
in in1(v) -> v1 = v; ni
}
}
call out(EOS);
}
end Merge
|
Процесс в листинге 8.9 похож на процесс из программы в листинге 7.2, который был запрограммирован с помощью асинхронной передачи сообщений. Операторы взаимодействия запрограммированы по-разному, но находятся в одних и тех же местах программ. Однако, поскольку оператор call является блокирующим, выполнение процесса гораздо теснее связано с рандеву, чем с асинхронной передачей сообщений. В частности, разные процессы Filter будут выполняться примерно с одинаковой скоростью, поскольку каждый поток будет всегда содержать не больше одного числа. (Процесс-фильтр не может вывести в поток второе значение, пока другой фильтр не получит первое.)
8.2.4. Взаимодействующие равные: обмен значений
Вернемся к задаче о процессах из двух модулей, которые обмениваются значениями переменных. Из листинга 8.4 видно, насколько сложно решить эту задачу с использованием RPC. Упростить решение можно, используя рандеву, хотя это хуже, чем передача сообщений.
Используя рандеву, процессы могут связываться между собой напрямую. Но, если оба процесса сделают вызовы одновременно, они заблокируют друг друга. Аналогично процессы одновременно не могут выполнять операторы in. Таким образом, решение должно быть асимметричным; один процесс должен выполнить оператор call и затем in, а другой — сначала in, а затем call. Это решение представлено в листинге 8.10. Требование асимметрии процессов приводит к появлению оператора if в каждом процессе Worker. (Асимметричное решение можно получить, имитируя программу с RPC в листинге 8.4, но это еще сложнее.)
Листинг 8.10. Обмен значений с использованием рандеву
module Exchange[i = 1 to 2]
op deposit(int);
body
process Worker
{
int myvalue, othervalue;
if (i == 1)
{ # один процесс вызывает
call Exchange[2].deposit(myvalue);
in deposit(othervalue) -> skip; ni
}
else
{ # другой процесс получает
in deposit(othervalue) -> skip; ni
call Exchange[1].deposit(myvalue);
}
...
}
end Exchange
|
8.3. Нотация совместно используемых примитивов
При использовании RPC и рандеву процесс инициирует взаимодействие, выполняя оператор call, который блокирует вызвавший процесс до того, как вызов будет обслужен и результаты возвращены. Такая последовательность действий идеальна для программирования взаимодействий типа “клиент-сервер”, но, как видно из двух последних разделов, усложняет программирование фильтров и взаимодействующих равных. С другой стороны, односторонний поток информации между фильтрами и равными процессами легче программировать с помощью асинхронной передачи сообщений.
В данном разделе описана программная нотация, которая объединяет RPC, рандеву и асинхронную передачу сообщений в единое целое. Такая составная нотация (нотация совместно используемых примитивов) сочетает преимущества всех трех ее компонентов и обеспечивает дополнительные возможности.
8.3.1. Вызов и обслуживание операций
По своей структуре программа будет набором модулей. Видимые операции объявляются в области определений модуля. Эти операции могут вызываться процессами из других модулей, а обслуживаются процессом или процедурой модуля, в котором объявлены. Могут использоваться также локальные операции, которые объявляются, вызываются и обслуживаются в теле одного модуля.
В составной нотации операция может быть вызвана либо синхронным оператором call, либо асинхронным send. Они имеют следующий вид.
call Mname.opname(аргументы);
send Mname.opname(аргументы);
|
Оператор call завершается, когда операция обслужена и возвращены результирующие аргументы, а оператор send — как только вычислены аргументы. Если операция возвращает результат, ее можно вызывать в выражении; ключевое слово call опускается. Если операция имеет результирующие параметры и вызывается оператором send, или функция вызывается оператором send, или вызов функции находится не в выражении, то возвращаемое значение игнорируется.
В составной нотации операция может быть обслужена либо в процедуре (proc), либо с помощью рандеву (операторы in). Выбор — за программистом, который объявляет операцию в модуле. Это зависит от того, нужен ли программисту новый процесс для обслуживания вызова, или удобнее использовать рандеву с существующим процессом. Преимущества и недостатки каждого способа демонстрируются в дальнейших примерах.
Когда операцию обслуживает процедура (proc), для обработки вызова создается новый процесс. Вызов операции даст тот же результат, что и при использовании RPC. Если операция вызвана оператором send, результат будет тем же, что и при создании нового процесса, поскольку вызвавший операцию процесс продолжается асинхронно по отношению к процессу, обслуживающему вызов. В обоих случаях вызов обслуживается немедленно, и очереди ожидающих обработки вызовов нет.
Другой способ обслуживания операций состоит в использовании операторов ввода, которые имеют вид, указанный в разделе 8.2. С каждой операцией связана очередь ожидающих обработки вызовов, и доступ к этой очереди является неделимым. Выбор операции для обслуживания происходит в соответствии с семантикой операторов ввода. При вызове такой операции процесс приостанавливается, поэтому результат аналогичен использованию рандеву. Если такую операцию вызвать с помощью оператора send, результат будет аналогичным использованию асинхронной передачи сообщений, поскольку отправитель сообщения продолжает работу.
Итак, есть два способа вызова операции (операторы call и send) и два способа обслуживания вызова — proc и in. Эти четыре комбинации приводят к таким результатам.
| Вызов |
Обслуживание |
Результат |
| call |
proc |
Вызов процедуры |
| call |
in |
Рандеву |
| send |
proc |
Динамическое создание процесса |
| send |
in |
Асинхронная передача сообщения |
Если вызывающий процесс и процедура proc находятся в одном модуле, то вызов является локальным, иначе — удаленным. Операцию нельзя обслуживать как с помощью proc, так и в операторе in, поскольку тогда возникает неопределенность — обслужить операцию немедленно или поместить в очередь. Но операцию можно обслуживать в нескольких операторах ввода; они могут находиться в нескольких процессах модуля, в котором объявлена операция. В этом случае процессы совместно используют очередь ожидающих вызовов, но доступ к ней является неделимым.
Для мониторов и асинхронной передачи сообщений был определен примитив empty, который проверяет, есть ли сообщения в канале сообщений или очереди условной переменной. В этой главе будет использован аналогичный, но несколько отличающийся примитив. Если opname является операцией, то ?opname — это функция, которая возвращает число вызовов, помещенных в очередь этой операции. Эту функцию удобно использовать в операторах ввода. Например, в следующем фрагменте кода операция op1 имеет приоритет перед операцией op2.
in op1(...) -> S1;
[] op2(...) and ?op1 == 0 -> S2;
ni
|
Условие синхронизации во второй защите разрешает выбор операции op2, только если при вычислении ?op1 определено, что вызовов операции op1 нет.
8.3.2. Примеры
Различные способы вызова и обслуживания операций проиллюстрируем тремя небольшими, тесно связанными примерами. Вначале рассмотрим реализацию очереди (листинг 8.11). Когда вызывается операция deposit, в buf помещается новый элемент. Если deposit вызвана оператором call, то вызывающий процесс ждет; если deposit вызвана оператором send, то вызывающий процесс продолжает работу (в этом случае процессу, вызывающему операцию, возможно, стоило бы убедиться, не переполнен ли буфер). Когда вызывается операция fetch, из массива buf извлекается элемент. Ее необходимо вызывать оператором call, иначе вызывающий процесс не получит результат.
Листинг 8.11. Последовательная очередь
module Queue
op deposit(typeT), fetch(result typeT);
body
typeT buf[n];
int front = 1, rear = 1, count = 0;
proc deposit(item)
{
if (count < n)
{
buf[rear] = item;
rear = (rear + 1) mod n;
count = count + 1;
}
else
предпринять действия, соответствующие переполнению;
}
proc fetch(item)
{
if (count > 0)
{
item = buf[front];
front = (front + 1) mod n;
count = count - 1;
}
else
предпринять действия, соответствующие опустошению;
}
end Queue
|
Модуль Queue пригоден для использования одним процессом в другом модуле. Его не могут совместно использовать несколько процессов, поскольку в модуле нет критических секций для защиты переменных модуля. При параллельном вызове операций может возникнуть взаимное влияние.
Если нужна синхронизированная очередь, модуль Queue можно изменить так, чтобы он реализовывал кольцевой буфер. В листинге 8.5 был представлен именно такой модуль. Видимые операции в этом модуле те же, что и в модуле Queue. Но их вызовы обслуживаются оператором ввода в одном процессе, т.е. по одному. Операция fetch должна вызываться оператором call, однако для операции deposit вполне можно использовать оператор send.
Модули в листингах 8.5 и 8.11 демонстрируют два разных способа реализации одного и того же интерфейса. Выбор определяется программистом и зависит от того, как именно используется очередь. Но есть еще один способ реализации кольцевого буфера, иллюстрирующий еще одно сочетание различных способов вызова и обслуживания операций в нотации совместно используемых примитивов.
Рассмотрим следующий оператор ввода, который ждет вызова операции op, а затем присваивает параметры постоянным переменным:
in op(f1, ..., fn) -> v1 = f1; ...; vn = fn; ni
|
Результат идентичен действию оператора receive:
Поскольку оператор receive является просто сокращенной формой оператора in, будем использовать receive, когда нужно обработать вызов именно таким образом.
Теперь рассмотрим операцию, которая не имеет аргументов, вызывается оператором send и обслуживается оператором receive (или эквивалентным in). Такая операция эквивалентна семафору, причем send выступает в качестве V, а receive — P. Начальное значение семафора равно нулю. Его текущее значение — это число “пустых” сообщений, переданных операции, минус число полученных сообщений.
В листинге 8.12 представлена еще одна реализация модуля BoundedBuffer, в которой для синхронизации использованы семафоры. Операции deposit и fetch обслуживаются процедурами так же, как в листинге 8.11. Следовательно, одновременно может существовать несколько активных экземпляров этих процедур. Однако для реализации взаимного исключения и условной синхронизации в этой программе используются семафорные операции. Структура этого модуля аналогична структуре монитора, но синхронизация реализована с помощью семафоров, а не исключений монитора и условных переменных.
Листинг 8.12. Кольцевой буфер, использующий семафорные операции
module BoundedBuffer
op deposit(typeT), fetch(result typeT);
body
typeT buf[n];
int front = 1, rear = 1;
# локальные операции для имитации семафоров
op empty(), full(), mutexD(), mutexF();
send mutexD(); send mutexF();
for [i = 1 to n] # инициализировать пустой (семафор(
send empty();
proc deposit(item)
{
receive empty(); receive mutexD();
buf[rear] = item; rear = (rear+1) mod n;
send mutexD(); send full();
}
proc fetch(item)
{
receive full(); receive mutexF();
item = buf[front]; front = (front+1) mod n;
send mutexF(); send empty();
}
end BoundedBuffer
|
Две реализации кольцевого буфера (см. листинги 8.5 и 8.11) иллюстрируют важную взаимосвязь между условиями синхронизации в операторах ввода и явной синхронизацией в процедурах. Во-первых, их часто используют с одинаковой целью. Во-вторых, поскольку условия синхронизации операторов ввода могут зависеть от аргументов ожидающих вызовов, эти два метода синхронизации обладают равной мощью. Но пока не нужна параллельность, которую обеспечивают несколько вызовов процедур, эффективнее использовать рандеву клиентов с одним процессом.
8.4. Новые решения задачи о читателях и писателях
С применением нотации совместно используемых примитивов можно программировать фильтры и взаимодействующие равные. Поскольку эта нотация включает и RPC, и рандеву, можно программировать процессы-клиенты и процессы-серверы, как в разделах 8.1 и 8.2. Совместно используемые примитивы обеспечивают дополнительную гибкость, которая демонстрируется здесь. Сначала разработаем еще одно решение задачи о читателях и. В отличие от предыдущих решений, здесь инкапсулирован доступ к базе данных. Затем расширим решение до распределенной реализации дублируемых файлов или баз данных. Обсудим также, как можно программировать эти решения, используя только RPC и локальную синхронизацию или только рандеву.
8.4.1. Инкапсулированный доступ
Напомню, что в задаче о читателях и писателях читательские процессы просматривают базу данных, возможно, параллельно. Процессы-писатели могут изменять базу данных, поэтому им нужен исключающий доступ к базе данных. В предыдущих решениях (с помощью семафоров в листингах 4.9 и 4.12 или с помощью мониторов в листинге 5.4) база данных была глобальной по отношению к процессам читателей и писателей, чтобы читатели могли обращаться к ней параллельно. При этом процессы должны были перед доступом к базе данных запрашивать разрешение, а после работы с ней освобождать доступ. Намного лучше инкапсулировать доступ к базе данных в модуле, чтобы спрятать протоколы запроса и освобождения, тем самым гарантируя их выполнение. Такой подход поддерживается в языке Java (это показано в конце раздела 5.4), поскольку программист может выбирать, будут методы (экспортируемые операции) выполняться параллельно или по одному. При использовании составной нотации решение можно структурировать аналогичным образом, причем полученное решение будет еще короче, а синхронизация — яснее.
В листинге 8.13 представлен модуль, инкапсулирующий доступ к базе данных. Клиентские процессы просто вызывают операции read или write, а вся синхронизация скрыта внутри модуля. В реализации модуля использованы и RPC, и рандеву. Операция read реализована в виде proc, поэтому несколько процессов-читателей могут выполняться параллельно, но операция write реализована на основе рандеву с процессом Writer, поэтому операции записи обслуживаются по очереди. Модуль также содержит две локальные операции, startread и endread, которые используются, чтобы обеспечить взаимное исключение операций чтения и записи. Их также обслуживает процесс Writer, поэтому он может отслеживать количество активных процессов-читателей и при необходимости откладывать выполнение операции write. Благодаря использованию рандеву в процессе Writer ограничения синхронизации выражаются непосредственно в виде логических условий, без обращений к условным переменным или семафорам. Отметим, что локальная операция endread вызывается оператором send, а не call, поскольку процесс-читатель не обязан ждать завершения обслуживания endread.
Листинг 8.13. Читатели и писатели с инкапсулированной базой данных
module ReadersWriters
op read(result типы результатов);
op write(типы значений); # использует рандеву
body
op startread(), endread(); # локальные операции
память для хранения буферов базы данных или передачи файлов;
proc read(результаты)
{
call startread(); # получить разрешение на чтение
читать из базы данных;
send endread(); # освободить доступ
}
process Writer
{
int nr = 0;
while (true)
{
in startread() -> nr = nr+1;
[] endread() -> nr = nr-1;
[] write(значения) and nr == 0 ->
записать в базу данных;
ni
}
}
end ReadersWriters
|
В языке, поддерживающем RPC, но не рандеву, этот модуль пришлось бы запрограммировать иначе. Например, обе операции read и write должны быть реализованы как экспортируемые процедуры, которые в свою очередь должны вызывать локальные процедуры для запроса разрешения на доступ к базе данных и для освобождения доступа. Внутренняя синхронизация должна обеспечиваться семафорами или мониторами.
Хуже, если язык поддерживает только рандеву. Операции обслуживаются существующими процессами, и каждый процесс может обслуживать одновременно только одну операцию. Таким образом, есть только один способ обеспечить параллельное чтение базы данных — экспортировать массив операций чтения, по одной для каждого клиента, и для их обслуживания использовать отдельные процессы. Такое решение по меньшей мере неуклюже и неэффективно.
Решение в листинге 8.13 отдает предпочтение читателям. Приоритет писателям можно дать, изменив оператор ввода с помощью функции ? для приостановки вызовов операции startread, когда есть задержанные вызовы операции write.
in startread() and ?write == 0 -> nr = nr+1;
[] endread() -> nr = nr-1;
[] write(значения) and nr == 0 -> записать в БД;
ni
|
Разработка решения со справедливым планированием оставляется читателю.
Модуль в листинге 8.13 блокирует для читателей или для писателей всю базу данных. Обычно этого достаточно для небольших файлов данных. Однако для транзакций в базах данных обычно нужно блокировать отдельные записи по мере их обработки, поскольку заранее не известно, какие конкретно записи понадобятся в транзакции. Например, транзакции нужно просмотреть некоторые записи, чтобы определить, какие именно считывать далее. Для реализации такого вида динамической блокировки можно использовать много модулей, по одному на каждую запись. Но тогда не будет инкапсулирован доступ к базе данных. Вместо этого в модуле ReadersWriters можно применить более сложную схему блокировки с мелкомодульной структурой. Например, выделять необходимые блокировки для каждой операции read и write. Именно этот подход типичен для систем управления базами данных.
8.4.2. Дублируемые файлы
Простой способ повысить доступность файла с критическими данными — хранить его резервную копию на другом диске, обычно расположенном на другой машине. Пользователь может делать это вручную, периодически копируя файлы, либо файловая система будет автоматически поддерживать копию таких файлов. В любом случае при необходимости доступа к файлу пользователь должен сначала проверить доступность основной копии файла и, если она недоступна, использовать резервную копию. (С этой задачей связана проблема обновления основной копии, когда она вновь становится доступной.)
Третий подход состоит в том, что файловая система обеспечивает прозрачное копирование. Предположим, что есть n копий файла данных и n серверных модулей. Каждый сервер обеспечивает доступ к одной копии файла. Клиент взаимодействует с одним из серверных модулей, например, с тем, который выполняется на одном процессоре с клиентом. Серверы взаимодействуют между собой, создавая у клиентов иллюзию работы с файлом. На рис. 8.1 показана структура такой схемы взаимодействия.
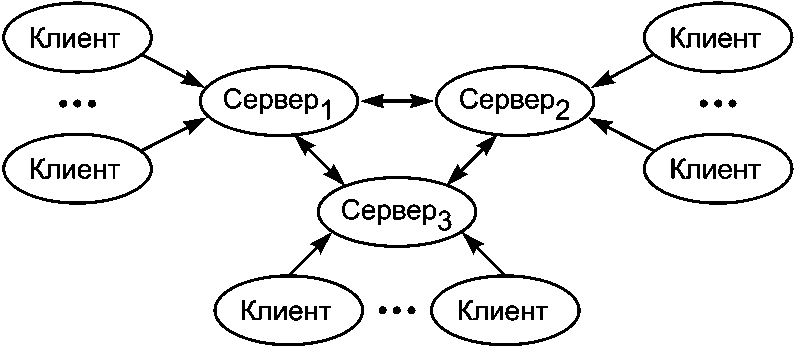
Рис. 8.1. Схема взаимодействия сервера дублируемого файла
Каждый модуль сервера экспортирует четыре операции: open, close, read и write. Желая обратиться к файлу, клиент вызывает операцию open своего сервера с указанием, собирается он записывать в файл или читать из него. Затем клиент общается с тем же сервером, вызывая операции read и write. Если файл был открыт для чтения, можно использовать только операции read, а если для записи — и read, и write. В конце концов клиент заканчивает диалог, вызвав операцию close.
Файловые серверы взаимодействуют, чтобы поддерживать согласованность копий файла и не давать делать записи в файл одновременно нескольким процессам. В каждом файловом сервере есть локальный процесс-диспетчер блокировок, реализующий решение задачи о читателях и писателях. Когда клиент открывает файл для чтения, операция open вызывает операцию startread локального диспетчера блокировок. Но когда клиентский процесс открывает файл для записи, операция open вызывает startwrite для всех n диспетчеров блокировок.
В листинге 8.14 представлен модуль FileServer. Для простоты использован массив и статическое именование, хотя на практике серверы должны создаваться динамически и размещаться на разных процессорах. Так или иначе, в реализации этого модуля есть несколько интересных аспектов.
Листинг 8.14. Дублируемые файлы с использованием блокировок для каждой копии
module FileServer[myid = 1 to n]
type mode = (READ, WRITE);
op open(mode), close(), # клиентские операции
read(result типы результатов), write(типы значений);
op startwrite(), endwrite(), # серверные операции
remote_write(типы значений);
body
op startread(), endread(); # локальные операции
mode use; объявления для файловых буферов;
proc open(m)
{
if (m == READ)
{
call startread(); # получить локальную блокировку чтения
use = READ;
}
else
{ # предполагается, что состояние - WRITE
# получить блокировки записи для всех копий
for [i = 1 to n]
call FileServer[i].startwrite();
use = WRITE;
}
}
proc close()
{
if (use == READ) # освободить локальную блокировку чтения
send endread();
else # use == WRITE, поэтому освободить все блокировки записи
for [i = 1 to n]
send FileServer.endwrite()
}
proc read(результаты)
{
читать из локальной копии файла и возвратить результаты;
}
proc write(значения)
{
if (use == READ)
возвратиться с ошибкой: файл не был открыт для записи;
записать значения в локальную копию файла;
# параллельно обновить все удаленные копии
co [i = 1 to n st i != myid]
call FileServer[i].remote_write(значения);
}
proc remote_write(значения)
{ # вызывается другими серверами
записать значения в локальную копию файла;
}
process Lock
{
int nr = 0, nw = 0;
while (true)
{
## RW: (nr == 0 ( nw == 0) ( nw <= 1
in startread() and nw == 0 -> nr = nr+1;
[] endread() -> nr = nr-1;
[] startwrite() and nr == 0 and nw == 0 ->
nw = nw+1;
[] endwrite() -> nw = nw-1;
ni
}
}
end FileServer
|
- Каждый модуль FileServer экспортирует два набора операций: вызываемые его клиентами и вызываемые другими файловыми серверами. Операции open, close, read и write реализованы процедурами, но read — единственная, которая должна быть реализована процедурой, чтобы допустить параллельное чтение. Операции блокировки реализованы с помощью рандеву с диспетчером блокировок.
- Каждый модуль следит за текущим режимом доступа (каким образом файл был открыт последний раз), чтобы не разрешать записывать в файл, открытый для чтения, и определять, какие действия нужно выполнить при закрытии файла. Но модуль не защищен от клиента, получившего доступ к файлу, предварительно не открыв его. Эту проблему можно решить с помощью динамического именования или дополнительных проверок в других операциях.
- В процедуре write модуль сначала обновляет свою локальную копию файла, а затем параллельно обновляет все удаленные копии. Это аналогично использованию стратегии сквозного обновления кэш-памяти. Вместо этого можно использовать стратегию с обратной записью, при которой операция write обновляет только локальную копию, а удаленные копии файла обновляются при его закрытии.
- В операции open клиент получает блокировки записи, по одной от каждого блокирующего процесса. Чтобы не возникла взаимоблокировка клиентов, все клиенты получают блокировку в одном и том же порядке. В операции close клиент освобождает блокировки записи с помощью оператора send, а не call, поскольку процессу не нужно ждать освобождения блокировок.
- Диспетчер блокировок реализует решение задачи о читателях и писателях с классическим предпочтением для читателей. <…>
В программе в листинге 8.14 читатель для чтения файла должен получить только одну блокировку чтения. Писатель же должен получить все n блокировок записи, по одной от каждого экземпляра модуля FileServer. В обобщении этой схемы нужно использовать так называемое взвешенное голосование.
Пусть readWeight — это число блокировок, необходимых для чтения файла, а writeWeight — для записи в файл. В нашем примере readWeight равно 1, а writeWeight — n. Можно было бы использовать другие значения — для readWeight значение 2, а для writeWeight — n-2. Это означало бы, что читатель должен получить две блокировки чтения и n-2 блокировок записи. Можно использовать любые весовые значения, лишь бы выполнялись следующие условия.
writeWeight > n/2 и
(readWeight + writeWeight) > n
|
При использовании взвешенного голосования, когда писатель закрывает файл, нужно обновить только копии, заблокированные для записи. Но каждая копия должна иметь метку времени последней записи в файл. Первое указанное выше требование гарантирует, что самые свежие данные и последние метки времени будут по меньшей мере у половины копий. (Как реализовать глобальные часы и метки времени последнего доступа к файлам, описывается в разделе 9.4.)
Открывая файл и получая блокировки чтения, читатель также должен прочитать метки времени последних изменений в каждой копии файла и использовать копию с самой последней меткой. Второе из указанных выше требований гарантирует, что будет хотя бы одна копия с самым последним временем изменений и, следовательно, с самыми последними данными. В нашей программе в листинге 8.14 не нужно было заботиться о метках времени, поскольку при закрытии файла обновлялись все его копии.
<…>
8.6. Учебные примеры: язык Ada
Язык Ada был создан при содействии министерства обороны США в качестве стандартного языка программирования приложений для обороны (от встроенных систем реального времени до больших информационных систем). Возможности параллелизма языка Ada являются его важной частью; они критичны для его использования по назначению. В языке Ada также есть большой набор механизмов для последовательного программирования.
Язык Ada стал результатом широкого международного конкурса разработок в конце 1970-х годов и впервые был стандартизован в 1983 г. В языке Ada 83 был представлен механизм рандеву для межпроцессного взаимодействия. Сам термин рандеву был выбран потому, что руководителем группы разработчиков был француз. Вторая версия языка Ada была стандартизована в 1995 г. Язык Ada 95 совместим снизу вверх с языком Ada 83 (поэтому старые программы остались работоспособными), но в нем появилось несколько новых свойств. Два самых интересных свойства, связанных с параллельным программированием, — это защищенные типы, подобные мониторам, и оператор requeue, позволяющий программисту более полно управлять синхронизацией и планированием.
В данном разделе сначала представлен обзор основных механизмов параллельности в языке Ada: задачи, рандеву и защищенные типы. Далее показано, как запрограммировать барьер в виде защищенного типа, а решение задачи об обедающих философах — в виде набора задач, которые взаимодействуют с помощью рандеву. В примерах также демонстрируются возможности языка Ada для последовательного программирования.
8.6.1. Задачи
Программа на языке Ada состоит из подпрограмм, модулей (пакетов) и задач. Подпрограмма — это процедура или функция, пакет — набор деклараций, а задача — независимый процесс. Каждый компонент имеет раздел определений и тело. Определения объявляют видимые объекты, тело содержит локальные декларации и операторы. Подпрограммы и модули могут быть настраиваемыми (generic), т.е. параметризоваться типами данных.
Базовая форма определения задачи имеет следующий вид.
task Name is
декларации точек входа;
end;
|
Декларации точек входа аналогичны декларациям op в модулях. Они определяют операции, которые обслуживает задача, и имеют такой вид.
entry Identifier(параметры);
|
Параметры передаются путем копирования в подпрограмму (по умолчанию), копирования из подпрограммы или обоими способами. Язык Ada поддерживает массивы точек входа, которые называются семействами точек входа.
Базовая форма тела задачи имеет следующий вид.
task body Name is
eieaeuiua aaeea?aoee
begin
iia?aoi?u;
end Name;
|
Задача должна быть объявлена внутри подпрограммы или пакета. Простейшая параллельная программа на языке Ada является, таким образом, процедурой, содержащей определения задач и их тела. Объявления в любом компоненте обрабатываются по одному в порядке их появления. Обработка объявления задачи приводит к созданию экземпляра задачи. После обработки всех объявлений начинают выполняться последовательные операторы подпрограммы в виде безымянной задачи.
Пара “определение задачи-тело” определяет одну задачу. Язык Ada также поддерживает массивы задач, но способ поддержки не такой, как в других языках программирования. Программист сначала объявляет тип задачи, а затем — массив экземпляров этого типа. Для динамического создания задач программист может использовать типы задач совместно с указателями (в языке Ada они называются типами доступа).
8.6.2. Рандеву
В языке Ada 83 первичным механизмом взаимодействия и единственной схемой синхронизации было рандеву. (Задачи на одной машине могли также считывать и записывать значения разделяемых переменных.) Все остальные схемы взаимодействия нужно было программировать с помощью рандеву. Язык Ada 95 также поддерживает защищенные типы для синхронизированного доступа к разделяемым объектам; это описано в следующем разделе.
Предположим, что в задаче T объявлена точка входа E. Задачи из области видимости задачи T могут вызвать E следующим образом.
Как обычно, выполнение call приостанавливает работу вызывающего процесса до тех пор, пока не завершится E (будет уничтожена или вызовет исключение).
Задача T обслуживает вызовы точки входа E с помощью оператора accept, имеющего следующий вид.
accept E(параметры) do
список операторов;
end;
|
Выполнение оператора accept приостанавливает задачу, пока не появится вызов E, копирует значения входных аргументов во входные параметры и выполняет список операторов. Когда выполнение списка операторов завершается, значения выходных параметров копируются в выходные аргументы. В этот момент продолжают работу и процесс, вызвавший точку входа, и процесс, выполняющий ее. Оператор accept, таким образом, похож на оператор ввода (раздел 8.2) с одной защитой, без условия синхронизации и выражения планирования.
Для поддержки недетерминированного взаимодействия задач в языке Ada используются операторы select трех типов: селективное ожидание, условный вызов точки входа и синхронизированный вызов точки входа. Оператор селективного ожидания поддерживает защищенное взаимодействие. Его обычная форма такова.
select when B1 => accept оператор; дополнительные операторы;
or ...
or when Bn => accept оператор; дополнительные операторы;
end select;
|
Каждая строка называется альтернативой. Каждое Bi — это логическое выражение, части when необязательны. Говорят, что альтернатива открыта, если условие Bi истинно или часть when отсутствует.
Эта форма селективного ожидания приостанавливает выполняющий процесс до тех пор, пока не сможет выполниться оператор accept в одной из открытых альтернатив, т.е. если есть ожидающий вызов точки входа, указанной в операторе accept. Поскольку каждая защита Bi предшествует оператору accept, защита не может ссылаться на параметры вызова точки входа. Также язык Ada не поддерживает выражения планирования. Как отмечалось в разделе 8.2 и будет видно из примеров следующих двух разделов, это усложняет решение многих задач синхронизации и планирования.
Оператор селективного ожидания может содержать необязательную альтернативу else, которая выбирается, если нельзя выбрать ни одну из остальных альтернатив. Вместо оператора accept программист может использовать оператор delay или альтернативу terminate. Открытая альтернатива с оператором delay выбирается, если истек интервал ожидания; этим обеспечивается механизм управления временем простоя. Альтернатива terminate выбирается, если завершились или ожидают в своих альтернативах terminate все задачи, которые взаимодействуют с помощью рандеву с данной задачей (см. пример в листинге 8.18).
Условный вызов точки входа используется, если одна задача должна опросить другую. Он имеет такой вид.
select вызов точки входа; дополнительные операторы;
else операторы;
end select;
|
Вызов точки входа выбирается, если его можно выполнить немедленно, иначе выбирается альтернатива else.
Синхронизированный вызов точки входа используется, когда вызывающая задача должна ожидать не дольше заданного интервала времени. По форме такой вызов аналогичен условному вызову точки входа.
select вызов точки входа; дополнительные операторы;
or delay оператор; дополнительные операторы;
end select;
|
Здесь выбирается вызов точки входа, если он может быть выполнен до истечения заданного интервала времени задержки.
Языки Ada 83 и Ada 95 обеспечивают несколько дополнительных механизмов для параллельного программирования. Задачи могут разделять переменные, однако обновление значений этих переменных гарантированно происходит только в точках синхронизации (например, в операторах рандеву). Оператор abort позволяет одной задаче прекращать выполнение другой. Существует механизм установки приоритета задачи. Кроме того, задача имеет так называемые атрибуты. Они позволяют определить, можно ли вызвать задачу, или она уже прекращена, а также узнать количество ожидающих вызовов точек входа.
8.6.3. Защищенные типы
Язык Ada 95 развил механизмы параллельного программирования языка Ada 83 по нескольким направлениям. Наиболее существенные дополнения — защищенные типы, которые поддерживают синхронизированный доступ к разделяемым данным, и оператор requeue, обеспечивающий планирование и синхронизацию в зависимости от аргументов вызова.
Защищенный тип инкапсулирует разделяемые данные и синхронизирует доступ к ним. Экземпляр защищенного типа аналогичен монитору, а его раздел определений имеет следующий вид.
protected type Name is
декларации функций, процедур или точек входа;
private
декларации переменных;
end Name;
|
Тело имеет такой вид.
protected body Name is
тела функций, процедур или точек входа;
end Name;
|
Защищенные функции обеспечивают доступ только для чтения к скрытым переменным; следовательно, функцию могут вызвать одновременно несколько задач. Защищенные процедуры обеспечивают исключительный доступ к скрытым переменным для чтения и записи. Защищенные точки входа похожи на защищенные процедуры, но имеют еще часть when, которая определяет логическое условие синхронизации. Защищенная процедура или точка входа в любой момент времени может выполняться только для одной вызвавшей ее задачи. Вызов защищенной точки входа приостанавливается, пока условие синхронизации не станет истинным и вызывающая задача не получит исключительный доступ к скрытым переменным. Условие синхронизации не может зависеть от параметров вызова.
Вызовы защищенных процедур и точек входа обслуживаются в порядке FIFO, но в зависимости от условий синхронизации точек входа. Чтобы отложить завершение обслуживаемого вызова, в теле защищенной процедуры или точки входа можно использовать оператор requeue. (Его можно использовать и в теле оператора accept.) Он имеет следующий вид.
Opname — это имя точки входа или защищенной процедуры, которая или не имеет параметров или имеет те же параметры, что и обслуживаемая операция. В результате выполнения оператора requeue вызов помещается в очередь операции Opname, как если бы задача непосредственно вызвала операцию Opname.
В качестве примера использования защищенного типа и оператора requeue рассмотрим код N-задачного барьера-счетчика в листинге 8.16. Предполагается, что N — глобальная константа. Экземпляр барьера объявляется и используется следующим образом.
B : Barrier; -- декларация барьера
...
B.Arrive; -- или "call B.Arrive;"
|
Первые N-1 задач, подходя к барьеру, увеличивают значение счетчика барьера count и задерживаются в очереди на скрытой точке входа Go. Последняя прибывшая к барьеру задача присваивает переменной time_to_leave значение True; это позволяет запускать по одному процессы, задержанные в очереди операции Go. Каждая задача перед выходом из барьера уменьшает значение count, а последняя уходящая задача переустанавливает значение переменной time_to_leave, поэтому барьер можно использовать снова. (Семантика защищенных типов гарантирует, что каждая приостановленная в очереди Go задача будет выполняться до обслуживания любого последующего вызова процедуры Arrive.) <…>
Листинг 8.16. Барьерная синхронизация на языке Ada
protected type Barrier is
procedure Arrive;
private
entry Go; -- используется для приостановки первых прибывших
count : Integer := 0; -- число прибывших
time_to_leave : Boolean := False;
end Barrier;
protected body Barrier is
procedure Arrive is begin
count := count+1;
if count < N then
requeue Go; -- ждать остальных
else
count := count-1; time_to_leave := True;
end if;
end;
entry Go when time_to_leave is begin
count := count-1;
if count = 0 then time_to_leave := False; end if;
end;
end Barrier;
|
8.6.4. Пример: обедающие философы
В данном разделе представлена законченная Ada-программа для задачи об обедающих философах. Программа иллюстрирует использование как задач и рандеву, так и некоторых общих свойств языка Ada. Для удобства предполагается, что существуют две функции left(i) и right(i), которые возвращают индексы левого и правого соседей философа i.
В листинге 8.17 представлена главная процедура Dining_Philosophers. Перед процедурой находятся декларации with и use. В декларации with сообщается, что эта процедура использует объекты пакета Ada.Text_IO, а use импортирует имена объектов этого пакета (т.е. их не нужно уточнять именем пакета).
Листинг 8.17. Решение задачи об обедающих философах на языке Ada: главная программа
with Ada.Text_IO; use Ada.Text_IO;
procedure Dining_Philosophers is
subtype ID is Integer range 1..5;
task Waiter is -- спецификация задачи-официанта
entry Pickup(I : in ID);
entry Putdown(I : in ID);
end
task body Waiter is separate;
task type Philosopher is -- тип задачи-философа
entry init(who : ID);
end;
DP : array(ID) of Philosopher; -- философы
rounds : Integer; -- число циклов
task body Philosopher is -- тело задачи-философа
myid : ID;
begin
accept init(who); myid := who; end;
for j in 1..rounds loop
-- "подумать"
Waiter.Pickup(myid); -- взять вилки
-- "поесть"
Waiter.Putdown(myid); -- положить вилки
end loop;
end Philosopher;
begin -- считать число циклов и запустить задачи-философы
Get(rounds);
for j in ID loop
DP(j).init(j);
end loop;
end Dining_Philosophers;
|
ПРИМЕЧАНИЕ
В теле задачи-философа отсутствует имитация случайных промежутков времени, в течение которых философы едят или думают. — Прим. ред.
|
В главной процедуре сначала объявлен тип ID с целыми значениями от 1 до 5. В спецификации задачи Waiter объявлены два входа Pickup и Putdown, вызываемых философами, чтобы взять (pick up) или положить (put down) вилку. Тело задачи Waiter компилируется отдельно; оно представлено в листинге 8.18.
Листинг 8.18. Решение задачи об обедающих философах на языке Ada: задача-официант
separate (Dining_Philosophers)
task body Waiter is
entry Wait(ID); -- для постановки философов в очередь
eating : array (ID) of Boolean; -- кто занят едой
want : array (ID) of Boolean; -- кто хочет есть
begin
for j in ID loop -- инициализация массивов
eating(j) := False;
want(j) := False;
end loop;
loop -- основной цикл сервера
select
accept Pickup(i : in ID) do -- вилки нужны для DP(i)
if not(eating(left(i)) or eating(right(i))) then
eating(i) := True;
else
want(i) := True;
requeue Wait(i);
end if;
end;
or
accept Putdown(i : in ID) do -- DP(i) закончил есть
eating(i) := False;
end;
-- проверить, могут ли теперь есть соседи
if want(left(i)) and not eating(left(left(i))) then
accept Wait(left(i));
eating(left(i)) := True;
want(left(i)) := False;
end if;
if want(right(i)) and not eating(right(right(i))) then
accept Wait(right(i));
eating(right(i)) := True;
want(right(i)) := False;
end if;
or
terminate; -- выход, когда философы закончили
end select;
end loop;
end Waiter;
|
В листинге 8.17 имя Philosopher определено как тип задачи, чтобы можно было объявить массив DP из пяти таких задач. Экземпляры пяти задач-философов создаются при обработке декларации массива DP. Каждый философ сначала ждет, чтобы принять вызов своей инициализирующей точки входа init, затем выполняет rounds итераций. Переменная rounds объявлена внешней по отношению к телу задач философов, поэтому все они могут ее читать. Переменная rounds инициализируется вводимым значением в теле главной процедуры (конец листинга 8.17). Затем каждому философу передается его индекс с помощью вызова DP(j).init(j).
Листинг 8.18 содержит тело задачи Waiter (официант). Оно сложнее, чем процесс Waiter в листинге 8.6, поскольку условие when в операторе select языка Ada не может ссылаться на входные параметры. Waiter многократно принимает вызовы операций Pickup и Putdown. Принимая вызов Pickup, официант проверяет, ест ли хотя бы один сосед философа i, вызвавшего эту операцию. Если нет, то философ i может есть. Но если хотя бы один сосед ест, то вызов Pickup должен быть вновь поставлен в очередь так, чтобы задача-философ не была слишком рано запущена вновь. Для приостановки ожидающих философов используется локальный массив из пяти точек входа Wait(ID); каждый философ ставится в очередь отдельного элемента этого массива.
Поев, философ вызывает операцию Putdown. Принимая этот вызов, официант проверяет, хочет ли есть каждый сосед данного философа и может ли он приступить к еде. Если да, официант принимает отложенный вызов операции Wait, чтобы запустить задачу-философа, вызов операции Pickup который был поставлен в очередь. Оператор accept, обслуживающий операцию Putdown, мог бы охватывать всю альтернативу в операторе select, т.е. заканчиваться после двух операторов if. Однако он заканчивается раньше, поскольку незачем приостанавливать задачу-философа, вызвавшую операцию Putdown.
8.7. Учебные примеры: язык SR
Язык синхронизируемых ресурсов (synchronizing resources — SR) был создан в 1980-х годах. В его первой версии был представлен механизм рандеву (см. раздел 8.2), затем он был дополнен поддержкой совместно используемых примитивов (см. раздел 8.3). Язык SR поддерживает разделяемые переменные и распределенное программирование, его можно использовать для непосредственной реализации почти всех программ из данной книги. SR-программы могут выполняться на мультипроцессорах с разделяемой памятью и в сетях рабочих станций, а также на однопроцессорных машинах.
Хотя язык SR содержит множество различных механизмов, все они основаны на нескольких ортогональных концепциях. Последовательный и параллельный механизмы объединены, чтобы похожие результаты достигались аналогичными способами. Выше уже были представлены и продемонстрированы многие аспекты языка SR, хотя явно об этом не говорилось. В данном разделе описываются такие вопросы, как структура программы, динамическое создание и размещение, дополнительные операторы. В качестве примера представлена программа, имитирующая выполнение процессов, которые входят в критические секции и выходят из них.
8.7.1. Ресурсы и глобальные объекты
Программа на языке SR состоит из ресурсов и глобальных компонентов. Декларация ресурса определяет схему модуля и имеет почти такую же структуру, как и module.
resource name
описания импортируемых объектов
декларации операций и типов
body name(параметры) # тело
декларации переменных и других локальных объектов
код инициализации
процедуры и процессы
код завершения
end name
|
Декларация ресурса содержит описания импортируемых объектов, если ресурс использует декларации, экспортируемые другими ресурсами или глобальными компонентами. Декларации и код инициализации в теле могут перемежаться; это позволяет использовать динамические массивы и управлять порядком инициализации переменных и создания процессов. Раздел описаний может быть опущен. Раздел описаний и тело могут компилироваться отдельно.
Экземпляры ресурса создаются динамически с помощью оператора create. Например, код
rcap := create name(аргументы)
|
передает аргументы (по значению) новому экземпляру ресурса name и затем выполняет код инициализации ресурса. Когда код инициализации завершается, возвращается мандат доступа к ресурсу, который присваивается переменной rcap. В дальнейшем эту переменную можно использовать для вызова операций, экспортируемых ресурсом, или для уничтожения экземпляра ресурса. Ресурсы уничтожаются динамически с помощью оператора destroy. Выполнение destroy останавливает любую работу в указанном ресурсе, выполняет его код завершения (если есть) и освобождает выделенную ему память.
По умолчанию компоненты SR-программы размещаются в одном адресном пространстве. Оператор create можно также использовать для создания дополнительных адресных пространств, которые называются виртуальными машинами.
vmcap := create vm() on machine
|
Этот оператор создает на указанном узле виртуальную машину и возвращает мандат доступа к ней. Последующие операторы создания ресурса могут использовать конструкцию “on vmcap”, чтобы размещать новые ресурсы в этом адресном пространстве. Таким образом, язык SR, в отличие от Ada, дает программисту полный контроль над распределением ресурсов по машинам, которое может зависеть от входных данных программы.
Для объявления типов, переменных, операций и процедур, разделяемых ресурсами, применяется глобальный компонент. Это, по существу, одиночный экземпляр ресурса. На каждой виртуальной машине, использующей глобальный компонент, хранится одна его копия. Для этого при создании ресурса неявно создаются все глобальные объекты (если они не были созданы ранее).
SR-программа содержит один отдельный главный ресурс. Выполнение программы начинается с неявного создания одного экземпляра этого ресурса. Затем выполняется код инициализации главного ресурса; обычно он создает экземпляры других ресурсов.
SR-программа завершается, когда завершаются или блокируются все процессы, или когда выполняется оператор stop. В этот момент подсистема времени исполнения (run-time system) выполняет код завершения (если он есть) главного ресурса и затем коды завершения (если есть) глобальных компонентов. Это обеспечивает программисту управление, чтобы, например, напечатать результаты или данные о времени работы программы.
В качестве простого примера приведем SR-программу, которая печатает две строки.
resource silly()
write("Hello world.")
final
write("Goodbye world.")
end
end
|
Этот ресурс создается автоматически. Он выводит строку и завершается. Тогда выполняется код завершения, выводящий вторую строку. Результат будет тем же, если убрать слова final и первое end.
8.7.2. Взаимодействие и синхронизация
Отличительным свойством языка SR является многообразие механизмов взаимодействия и синхронизации. Переменные могут разделяться процессами одного ресурса, а также ресурсами в одном адресном пространстве (с помощью глобальных компонентов). Процессы также могут взаимодействовать и синхронизироваться, используя все примитивы, описанные в разделе 8.3, — семафоры, асинхронную передачу сообщений, RPC и рандеву. Таким образом, язык SR можно использовать для реализации параллельных программ как на мультипроцессорных машинах с разделяемой памятью, так и в распределенных системах.
Декларации операций начинаются ключевым словом op; их вид уже был представлен в данной главе. Такие декларации можно записывать в разделе описаний ресурса, в теле ресурса и даже в процессах. Операция, объявленная в процессе, называется локальной. Процесс, который объявляет операцию, может передавать мандат доступа к локальной операции другому процессу, позволяя ему вызывать эту операцию. Эта возможность поддерживает непрерывность диалога.
Операция вызывается с помощью синхронного оператора call или асинхронного send. Для указания вызываемой операции оператор вызова использует мандат доступа к операции или поле мандата доступа к ресурсу. Внутри ресурса, объявившего операцию, ее мандатом фактически является ее имя, поэтому в операторе вызова можно использовать непосредственно имя операции. Мандаты ресурсов и операций можно передавать между ресурсами, поэтому пути взаимодействия могут изменяться динамически.
Операцию обслуживает либо процедура (proc), либо оператор ввода (in). Для обслуживания каждого удаленного вызова proc создается новый процесс; вызовы в пределах одного адресного пространства оптимизируются так, чтобы тело процедуры выполнял процесс, который ее вызвал. Все процессы ресурса работают параллельно, по крайней мере, теоретически.
Оператор ввода in поддерживает рандеву. Этот оператор показан в разделе 8.2; он может содержать условия синхронизации и выражения планирования, зависящие от параметров. Оператор ввода может содержать необязательную часть else, которая выбирается, если не пропускает ни одна из защит.
Язык SR содержит несколько механизмов, являющихся сокращениями других конструкций. Декларация process — это сокращение декларации op и определения proc для обслуживания вызовов операции. Один экземпляр процесса создается неявным оператором send при создании ресурса. (Программист может объявлять и массивы процессов.) Декларация procedure также является сокращением декларации op и определения proc для обслуживания вызовов операции.
Еще два сокращения — это оператор receive и семафоры. Оператор receive выполняется так же, как оператор ввода, который обслуживает одну операцию и просто записывает значения аргументов в локальные переменные. Декларация семафора (sem) является сокращенной формой объявления операции без параметров. Оператор P представляет собой частный случай оператора receive, а V — оператора send.
Язык SR обеспечивает несколько дополнительных полезных операторов. Оператор reply — это вариант оператора return. Он возвращает значения, но выполняющий его процесс продолжает работу. Оператор forward можно использовать, передавая вызов другому процессу для последующего обслуживания. Он аналогичен оператору requeue языка Ada. Наконец, в языке SR есть оператор «co» для параллельного вызова операций.
8.7.3. Пример: моделирование критической секции
В листинге 8.19 приведена законченная программа, использующая несколько механизмов передачи сообщений языка SR. Программа также показывает, как разработать простую модель решения задачи (в данном случае — задачи критической секции).
Листинг 8.19. SR-программа, моделирующая критические секции
global CS
op CSenter(id: int) {call} # вызывается оператором call
op CSexit() # вызывается оператором call или send
body CS
process arbitrator
do true ->
in CSenter(id) by id ->
write("user", id, "in its CS at", age())
ni
receive CSexit()
od
end
end
resource main()
import CS
var numusers, rounds: int
getarg(1, numusers); getarg(2, rounds)
process user(i := 1 to numusers)
fa j := 1 to rounds ->
call CSenter(i) # войти в критическую секцию
nap(int(random(100))) # ждать до 100 мс
send CSexit() # выйти из критической секции
nap(int(random(1000))) # ждать до 1 сек
af
end
end
|
Глобальный компонент CS экспортирует две операции: CSenter и CSexit. Тело CS содержит процесс arbitrator, реализующий эти операции. Для ожидания вызова операции CSenter в нем использован оператор ввода.
in CSenter(id) by id ->
write("user", id, "in its CS at", age())
ni
|
Это механизм рандеву языка SR. Если есть несколько вызовов операции CSenter, то выбирается вызов с наименьшим значением параметра id, после чего печатается сообщение. Затем процесс arbitrator использует оператор receive для ожидания вызова операции CSexit. В этой программе процесс arbitrator и его операции можно было бы поместить внутрь ресурса main. Однако, находясь в глобальном компоненте, они могут использоваться другими ресурсами в большей программе.
Ресурс main считывает из командной строки два аргумента, после чего создает numusers экземпляров процесса user. Каждый процесс с индексом i выполняет цикл “для всех” (for all — fa), в котором вызывает операцию CSenter с аргументом i, чтобы получить разрешение на вход в критическую секцию. Длительность критической и некритической секций кода имитируется “сном” (nap) каждого процесса user в течение случайного числа миллисекунд. После “сна” процесс вызывает операцию CSexit. Операцию CSenter можно вызвать только синхронным оператором call, поскольку процесс user должен ожидать получения разрешения на вход в критическую секцию. Это выражено ограничением {call} в объявлении операции CSenter. Однако операцию CSexit можно вызывать асинхронным оператором send, поскольку процесс user может не задерживаться, покидая критическую секцию.
В программе использованы несколько предопределенных функций языка SR. Оператор write печатает строку, а getarg считывает аргумент из командной строки. Функция age в операторе write возвращает длительность работы программы в миллисекундах. Функция nap заставляет процесс “спать” в течение времени, заданного ее аргументом в миллисекундах. Функция random возвращает псевдослучайное число в промежутке от 0 до значения ее аргумента. Использована также функция преобразования типа в int, чтобы преобразовать результат, возвращаемый функцией random, к целому типу, необходимому для аргумента функции nap.
Историческая справка
Удаленный вызов процедур (RPC) и рандеву появились в конце 1970-х годов. Исследования по семантике, использованию и реализации RPC были начаты и продолжаются разработчиками операционных систем. Нельсон (Bruce Nelson) провел много экспериментов по этой теме в исследовательском центре фирмы Xerox в Пало-Альто (PARC) и написал отличную диссертацию [Nelson, 1981]. Эффективная реализация RPC в ядре операционной системы представлена в работе [Birrell and Nelson, 1984]. Перейдя из PARC в Стэнфордский университет, Спектор [Alfred Spector, 1982] написал диссертацию по семантике и реализации RPC.
Бринч Хансен [Brinch Hansen, 1978] выдвинул основные идеи RPC (хотя и не дал этого названия) и разработал первый язык программирования, основанный на удаленном вызове процедур. Он назвал свой язык “Распределенные процессы” (Distributed Processes — DP). Процессы в DP могут экспортировать процедуры. Процедура, вызванная другим процессом, выполняется в новом потоке управления. Процесс может также иметь один “фоновый” поток, который выполняется первым и может продолжать работу в цикле. Потоки в процессе выполняются со взаимным исключением. Они синхронизируются с помощью разделяемых переменных и оператора when, аналогичного оператору await (глава 2).
RPC был включен в некоторые другие языки программирования, такие как Cedar, Eden, Emerald и Lynx. На RPC основаны языки Argus, Aeolus, Avalon и другие. В этих трех языках RPC объединен с так называемыми неделимыми транзакциями. Транзакция — это группа операций (вызовов процедур). Транзакция неделима, если ее нельзя прервать и она обратима. Если транзакция совершается (commit), выполнение всех операций выглядит единым и неделимым. Если транзакция прекращается (abort), то никаких видимых результатов ее выполнения нет. Неделимые транзакции возникли в области баз данных и использовались для программирования отказоустойчивых распределенных приложений.
В статье [Stamos and Gifford, 1990] представлено интересное обобщение RPC, которое названо удаленными вычислениями (remote evaluation — REV). С помощью RPC серверный модуль обеспечивает фиксированный набор предопределенных сервисных функций. С помощью REV клиент может в аргументы удаленного вызова включить программу. Получая вызов, сервер выполняет программу и возвращает результаты. Это позволяет серверу обеспечивать неограниченный набор сервисных функций. В работе Стамоса и Гиффорда показано, как использование REV может упростить разработку многих распределенных систем, и описан опыт разработчиков с реализацией прототипа. Аналогичные возможности (хотя чаще всего для клиентской стороны) предоставляют аплеты Java. Например, аплет обычно возвращается сервером и выполняется на машине клиента.
Рандеву были предложены в 1978 г. параллельно и независимо Жаном-Раймоном Абриалем (Jean-Raymond Abrial) из команды Ada и автором этой книги при разработке SR. Термин рандеву был введен разработчиками Ada (многие из них были французами). На рандеву основан еще один язык — Concurrent С [Gehani and Roome, 1986, 1989]. Он дополняет язык С процессами, рандеву (с помощью оператора accept) и защищенным взаимодействием (с помощью select). Оператор select похож на одноименный оператор в языке Ada, а оператор accept обладает большей мощью. Concurrent С позаимствовал из SR две идеи: условия синхронизации могут ссылаться на параметры, а оператор accept — содержать выражение планирования (часть by). Concurrent С также допускает вызов операций с помощью send и call, как и в SR. Позже Джехани и Руми [Gehani and Roome, 1988] разработали Concurrent C++, сочетавший черты Concurrent С и С++.
Совместно используемые примитивы включены в несколько языков программирования, самый известный из которых — SR. Язык StarMod (расширение Modula) поддерживает синхронную передачу сообщений, RPC, рандеву и динамическое создание процессов. Язык Lynx поддерживает RPC и рандеву. Новизна Lynx заключается в том, что он поддерживает динамическую реконфигурацию программы и защиту с помощью так называемых связей.
Обзор [Bal, Steiner and Tanenbaum, 1989] представляет исчерпывающую информацию и ссылки по всем упомянутым здесь языкам. Антология [Gehani and McGettrick, 1988] содержит перепечатки основных работ по нескольким языкам (Ada, Argus, Concurrent С, DP, SR), сравнительные обзоры и оценки языка Ada.
Кэширование файлов на клиентских рабочих станциях реализовано в большинстве распределенных операционных систем. Файловая система, представленная схематически в листинге 8.2, по сути та же, что в операционной системе Amoeba. В статье [Tanenbaum et al., 1990] дан обзор системы Amoeba и описан опыт работы с ней. Система Amoeba использует RPC в качестве базовой системы взаимодействия. Внутри модуля потоки выполняются параллельно и синхронизируются с помощью блокировок и семафоров.
В разделе 8.4 были описаны способы реализации дублируемых файлов. Техника взвешенного голосования подробно рассмотрена в работе [Gifford, 1979]. Основная причина использования дублирования — необходимость отказоустойчивости файловой системы. <…>
Удаленный вызов методов (RMI) появился в языке Java, начиная с версии 1.1. Пояснения к RMI и примеры его использования можно найти в книгах [Flanagan, 1997] и [Hartley, 1998]. Дополнительную информацию по RMI можно найти на главном Web-узле языка Java www.javasoft.com.
В 1974 году Министерство обороны США (МО США) начало программу “универсального языка программирования высокого уровня” (как ответ на рост стоимости разработки и поддержки программного обеспечения). На ранних этапах программы появилась серия документов с основными требованиями, которые вылились в так называемые спецификации Стилмена (Steelman). Четыре команды разработчиков, связанных с промышленностью и университетами, представили проекты языков весной 1978 г. Для завершающей стадии были выбраны два из них, названные Красным и Зеленым. На доработку им было дано несколько месяцев. “Красной” командой разработчиков руководил Intermetrics, “зеленой” — Cii Honey Bull. Обе команды сотрудничали с многочисленными внешними экспертами. Весной 1979 г. был выбран Зеленый проект. (Интересно, что вначале Зеленый проект основывался на синхронной передаче сообщений, аналогичной используемой в CSP; разработчики заменили ее рандеву летом и осенью 1978 г.)
МО США назвало новый язык Ada в честь Августы Ады Лавлейс, дочери поэта Байрона и помощницы Чарльза Бэббиджа, изобретателя аналитической машины. Первая версия языка Ada с учетом замечаний и опыта использования была усовершенствована и стандартизована в 1983 г. Новый язык был встречен и похвалой, и критикой; похвалой за превосходство над другими языками, использовавшимся в МО США, а критикой — за размеры и сложность. Оглядываясь в прошлое, можно заметить, что этот язык уже не кажется таким сложным. Некоторые замечания по Ada 83 и опыт его использования в следующем десятилетии привели к появлению языка Ada 95, который содержит новые механизмы параллельного программирования, описанные в разделе 8.6.
Реализации языка Ada и среды разработки для множества различных аппаратных платформ производятся несколькими компаниями. Этот язык описан во многих книгах. Особое внимание на большие возможности языка Ada обращено в книге [Gehani, 1983]; алгоритм решения задачи об обедающих философах (см. листинги 8.17 и 8.18) в своей основе был взят именно оттуда. В книге [Burns and Wellings, 1995] описаны механизмы параллельного программирования языка Ada 95 и показано, как его использовать для программирования систем реального времени и распределенных систем. Исчерпывающий Web-источник информации по языку Ada находится по адресу www.adahome.com.
Основные идеи языка SR (ресурсы, операции, операторы ввода, синхронные и асинхронные вызовы) были задуманы автором этой книги в 1978 г. и описаны в статье [Andrews, 1981]. Полностью язык был определен в начале 1980-х и реализован несколькими студентами. Эндрюс и Олсон (Olsson) разработали новую версию этого языка в середине 1980-х годов. Были добавлены RPC, семафоры, быстрый ответ и некоторые дополнительные механизмы [Andrews et al., 1988]. Последующий опыт и желание обеспечить оптимальную поддержку для параллельного программирования привели к разработке версии 2.0. SR 2.0 представлен в книге [Andrews and Olsson, 1992], где также приведены многочисленные примеры и обзор реализации. Параллельное программирование на SR описано в книге [Hartley, 1995], задуманной как учебное руководство по операционным системам и параллельному программированию. Адрес домашний страницы проекта SR и реализаций: www.cs.arizona.edu/sr.
Основная тема этой книги — как писать многопоточные, параллельные и/или распределенные программы. Близкая тема, но имеющая более высокий уровень, — как связывать существующие или будущие прикладные программы, чтобы они совместно работали в распределенном окружении, основанном на Web. Программные системы, которые обеспечивают такую связь, называются ПО промежуточного уровня (middleware). CORBA и DCOM — это наиболее известные из подобных систем. Они и большинство других основаны на объектно-ориентированных технологиях. CORBA (Common Object Request Broker Architecture — технология построения распределенных объектных приложений) — это набор спецификаций и инструментальных средств для обеспечения возможности взаимодействия программ в распределенных системах. DCOM (Distributed Component Object Model — распределенная модель компонентных объектов) служит основой для удаленных взаимодействий, например, между компонентами ActiveX. Эти и многие другие технологии описаны в книге [Umar, 1997]. Полезным Web-узлом по CORBA является www.omg.org, а по Active-X и DCOM — www.activex.org.
Литература
- Andrews, G. R. 1981. Synchronizing resources. ACM Trans. on Prog. Languages and Systems 3, 4 (October): 405–430.
- Andrews, G. R., and R. A. Olsson. 1992. Concurrent Programming in SR. Menlo Park, CA: Benjamin/Cummings.
- Andrews, G. R., R. A. Olsson, M. Coffin, I. Elshoff, K. Nilsen, T. Purdin, and G. Townsend. 1988. An overview of the SR language and implementation. ACM Trans. on Prog. Languages and Systems 10, 1 (January): 51–86.
- Bal, H. E., J. G. Steiner, and A. S. Tanenbaum. 1989. Programming languages for distributed computing systems. ACM Computing Surveys 21, 3 (September): 261–322.
- Birrell, A. D., and B. J. Nelson. 1984. Implementing remote procedure calls. ACM Trans. on Computer Systems 2, 1 (February): 39–59.
- Brinch Hansen, P. 1978. Distributed processes: A concurrent programming concept. Comm. ACM 21, 11 (November): 934–941.
- Burns, A., and A. Wellings. 1995. Concurrency in Ada. Cambridge, England: Cambridge University Press.
- Flanagan, D. 1997. Java Examples in a Nutshell: A Tutorial Companion to Java in a Nutshell. Sebastopol, CA: O'Reilly & Associates.
- Gehani, N. 1983. Ada: An Advanced Introduction. Englewood Cliffs, NJ: Prentice-Hall.
- Gehani, N. H., and A. D. McGettrick. 1988. Concurrent Programming. Reading, MA: Addison-Wesley.
- Gehani, N. H., and W. D. Roome. 1986. Concurrent C. Software — Practice and Experience 16, 9 (September): 821–844.
- Gehani, N. H., and W. D. Roome. 1988. Concurrent C++: Concurrent programming with class(es). Software — Practice and Experience 18, 12 (December): 1157–1177.
- Gehani, N. H., and W. D. Roome. 1989. The Concurrent C Programming Language. Summit, NJ: Silicon Press.
- Gifford, D. K. 1979. Weighted voting for replicated data. Proc. Seventh Symp. on Operating Systems Principles (December): 150–162.
- Hartley, S. J. 1995. Operating Systems Programming: The SR Programming Language. New York: Oxford University Press.
- Hartley, S. J. 1998. Concurrent Programming: The Java Programming Language. New York: Oxford University Press.
- Nelson, B. J. 1981. Remote procedure call. Doctoral dissertation, CMU-CS-81-119, Carnegie-Mellon University, May.
- Spector, A. Z. 1982. Performing remote operations efficiently on a local computer network. Comm. ACM 25, 4 (April): 246–260.
- Stamos, J. W, and D. K. Gifford. 1990. Remote evaluation. ACM Trans. on Prog. Languages and Systems 12, 4 (October): 537–565.
- Tanenbaum, A. S, R. van Renesse, H. van Staveren, G. J. Sharp, S. J. Mullender, J. Jansen, and G. van Rossum. 1990. Experiences with the Amoeba distributed operating system. Comm. ACM 33, 12 (December): 46–63.
- Umar, A. 1997. Object-Oriented Client/Server Internet Environments. Englewood Cliffs, NJ: Prentice-Hall.
Любой из материалов, опубликованных на этом сервере, не может быть воспроизведен в какой бы
то ни было форме и какими бы то ни было средствами без письменного разрешения владельцев авторских
прав.
Copyright © 1994-2016 ООО "К-Пресс"
