 |
Технология Клиент-Сервер 2007'3
|
|
|
Linux и симметричная многопроцессорная система
Автор: М. Тим Джонс
Emulex
Опубликовано: 20.10.2008
Быстродействие системы Linux вы можете увеличить разными способами, и один из наиболее популярных – увеличить производительность процессора. Очевидное решение – использовать процессор с большей тактовой частотой, но для любой технологии существует физическое ограничение, когда тактовый генератор просто не может работать быстрее. При достижении этого предела вы можете использовать гораздо лучший подход и применить несколько процессоров. К сожалению, быстродействие имеет нелинейную зависимость от совокупности параметров отдельных процессоров.
Прежде чем обсуждать применение многопроцессорной обработки в Linux, давайте взглянем на ее историю.
История многопроцессорной обработки
ПРИМЕЧАНИЕ
Классификация многопроцессорных архитектур Флинна.
SISD (Один поток команд, один поток данных, Single Instruction, Single Data) – типичная однопроцессорная архитектура. Многопроцессорная архитектура MIMD (Multiple Instruction, Multiple Data, Много потоков команд, много потоков данных) содержит отдельные процессоры, оперирующие независимыми данными (параллелизм управления). Наконец, SIMD (Single Instruction, Multiple Data, Один поток команд, много потоков данных) имеет ряд процессоров, оперирующих разнотипными данными (параллелизм данных).
|
Многопроцессорная обработка зародилась в середине 1950-х в ряде компаний, некоторые из которых вы знаете, а о некоторых, возможно, уже забыли (IBM, Digital Equipment Corporation, Control Data Corporation). В начале 1960-х Burroughs Corporation представила симметричный мультипроцессор типа MIMD с четырьмя CPU, имеющий до шестнадцати модулей памяти, соединенных координатным соединителем (первая архитектура SMP). Широко известный и удачный CDC 6600 был представлен в 1964 и предоставлял CPU десять подпроцессоров (периферийными процессорами). В конце 1960-х Honeywell выпустил другую симметричную мультипроцессорную систему Multics из восьми CPU.
В то время как многопроцессорные системы развивались, технологии также шли вперед, уменьшая размеры процессоров и увеличивая их способности работать на значительно большей тактовой частоте. В 1980-х такие компании, как Cray Research, представили многопроцессорные системы и UNIX-подобные операционные системы, которые могли их использовать (CX-OS).
В конце 1980-х с популярностью однопроцессорных персональных компьютеров, таких как IBM PC, в многопроцессорных системах наблюдался упадок. Но сейчас, двадцать лет спустя, многопроцессорная обработка вернулась на те же самые персональные компьютеры в виде симметричной многопроцессорной обработки.
Закон Амдаля
Джин Амдаль (Gene Amdahl), компьютерный архитектор и сотрудник IBM, разрабатывал в IBM компьютерные архитектуры, создал одноименную фирму, Amdahl Corporation и др. Но известность ему принес его закон, в котором рассчитывается максимально возможное улучшение системы при улучшении ее части. Закон используется, главным образом, для вычисления максимального теоретического улучшения работы системы при использовании нескольких процессоров (смотри Рисунок 1).
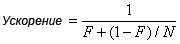
Рисунок 1. Закон Амдаля для распараллеливания процессов.
Используя уравнение, показанное на Рисунке 1, вы можете вычислить максимальное улучшение производительности системы, использующей N процессоров и фактор F, который указывает, какая часть системы не может быть распараллелена (часть системы, которая последовательна по своей природе). Результат приведен на Рисунке 2.
Верхняя линия на Рисунке 2 показывает число процессоров. В идеале это то, что вы хотели бы увидеть после добавления дополнительных процессоров для решения задачи. К сожалению, из-за того что не все в задаче может быть распараллелено, и наличия непроизводительных издержек на управление процессорами, ускорение оказывается немного меньше. Внизу (лиловая линия) – случай задачи, которая на 90% последовательна. Лучшему случаю на этом графике соответствует коричневая линия, которая изображает задачу, которая на 10% последовательна и, соответственно, на 90% – параллелизуема. Даже в этом случае десять процессоров работают совсем не намного лучше, чем пять.
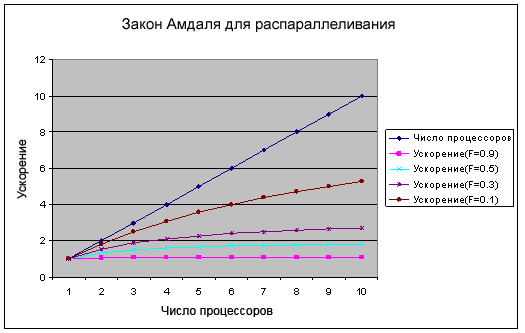
Рисунок 2. Закон Амдаля для системы, имеющей до десяти CPU.
Многопроцессорная обработка и ПК
Архитектура SMP – одна из тех, где два или более идентичных процессоров соединены друг с другом посредством разделяемой памяти. У всех них одинаковый доступ к разделяемой памяти (с одинаковым временем ожидания доступа к пространству памяти). Противоположностью ей является архитектура неоднородного доступа к памяти (NUMA – Non-Uniform Memory Access). Каждый процессор в этом случае может обладать собственной памятью, но разным временем ожидания доступа к разделяемой памяти.
Слабосвязанная многопроцессорная обработка
Ранние SMP Linux-системы были слабосвязанными многопроцессорными системами, то есть построенными из нескольких отдельных систем, связанных высокоскоростным соединением (таким как 10G Ethernet, Fibre Channel или Infiniband). Другое название такого типа архитектуры – кластер (см. Рисунок 3), для которого популярным решением остается проект Linux Beowulf. Кластеры Linux Beowulf могут быть построены из доступного оборудования, соединенного обычной сетью, например, Ethernet.
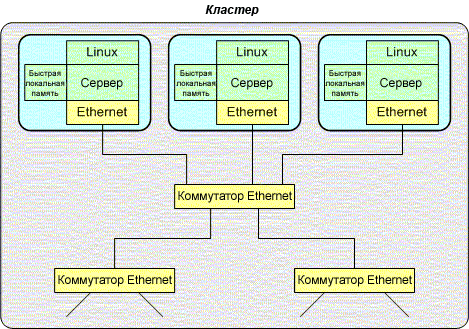
Рисунок 3. Слабосвязанная многопроцессорная архитектура.
Строить системы со слабосвязанной многопроцессорной архитектурой просто (спасибо проектам вроде Beowulf), но у них есть свои ограничения. Создание большой многопроцессорной сети может потребовать значительных мощностей и места. Более серьезное препятствие – материал канала связи. Даже с высокоскоростной сетью, такой как 10G Ethernet, есть предел масштабируемости системы.
Сильносвязанная многопроцессорная обработка
Сильносвязанная многопроцессорная обработка относится к обработке на уровне кристалла (CMP – chip-level multiprocessing). Представьте слабосвязанную архитектуру, уменьшенную до уровня кристалла. Это и есть идея сильносвязанной многопроцессорной обработки (также называемой многоядерным вычислением). На одной интегральной микросхеме несколько кристаллов, общая память и соединение образуют хорошо интегрированное ядро для многопроцессорной обработки (смотрите Рисунок 4).
Процессорные соединения
Конфигурация ядра
SMP и ядро Linux
SMP в ядре
Потоки пользовательского пространства: развивая силу SMP
Защита переменной ядра для SMP
Заключение
Когда частота процессора достигает своего предела, для увеличения производительности обычно просто добавляют еще процессоры. Раньше это означало размещение большего числа процессоров на материнской плате или объединение в кластер несколько независимых компьютеров. Сегодня многопроцессорная обработка на уровне кристалла предоставляет больше процессоров на одном кристалле, давая еще большее быстродействие путем уменьшения времени ожидания памяти.
Системы SMP вы найдете не только на серверах, но и на десктопах, особенно с внедрением виртуализации. Как и многие передовые технологии, Linux предоставляет поддержку SMP. Ядро выполняет свою часть оптимизации загрузки доступных CPU (от потоков до виртуализованных операционных систем). Все, что остается, - это убедиться, что приложение может быть в достаточной мере разделено на потоки, чтобы использовать силу SMP.
Любой из материалов, опубликованных на этом сервере, не может быть воспроизведен в какой бы
то ни было форме и какими бы то ни было средствами без письменного разрешения владельцев авторских
прав.
........................
"С полным содержанием данной статьи можно ознакомиться в печатной версии журнала"
Copyright © 1994-2016 ООО "К-Пресс"
