 |
Технология Клиент-Сервер 2009'1
|
|
|
Разбираясь в своих базах данных
Опубликовано: 12.07.2010
Версия текста: 1.1
Введение
Многим из нас иногда приходится выполнять такое задание: «получить некоторые данные из некой базы данных». Не знаю, происходит ли это только со мной, но меня то и дело просят работать с базами данных, о которых я ничего не знаю. Как правило, при этом у меня нет ни документации, ни сведений о модели данных, ни соглашения о наименованиях, - словом, вообще ничего нет. Обычно есть только общая информация о том, что мне нужно найти – к примеру, «все данные о покупателях из прежней базы данных нашего Интернет-магазина». Это означает, что я буду иметь дело с типичными таблицами, которые связаны с покупателями и заказами: Покупатели, Организации, Страны, Заказы и т.д. Однако во всех этих таблицах и колонках довольно легко запутаться.
Посему в качестве отправной точки, с которой можно начинать изучение этих баз данных, я создал три небольших хранимых процедуры. Каждая из них позволяет получить более подробную информацию об объектах, с которыми я имею дело. Подозреваю, что эти действия будут выглядеть более изящно на другом инструментарии, но в моем распоряжении имеется только SQL Server 2000.
Идея заключается в следующем. У вас есть база данных, но вы не знаете, в какую таблицу смотреть. Попробуйте сначала найти интересные таблицы или, по крайней мере, ограничьте список подходящих претендентов. Когда вы определитесь, какие таблицы анализировать, нужно будет узнать, связаны ли они как-нибудь с другими, поэтому следующим шагом будет проверка их зависимостей, причем проверка тщательная (хотя при использовании запросов она не всегда может оказаться простой и легкой). Затем вам понадобится составить представление о том, какие колонки, скорее всего, имеет смысл проверить. Попробуйте отыскать колонки со схожими именами.
Конечно, результат сильно зависит от конкретной ситуации, но поскольку таблица с какими-либо элементами (Item table) обычно содержит колонки, названные как-нибудь вроде %элемент%, проверка таблиц со схожими названиями может иметь смысл. Параллельно следует проанализировать список таблиц-претендентов: насколько они велики, какие в них колонки, сколько различающихся значений и т.д. Эти числа не всегда стопроцентно отражают действительность, но они хороши для нашей цели – что нам, в сущности, и нужно. В самом конце понадобится немного поработать ручками: просмотреть результаты, - в принципе, ничего страшного.
Поскольку мы ищем таблицы, которые являются в некотором роде центральными для базы данных, содержат все «хорошие данные» и обладают множеством строк и зависимостей, понятно, что в таких таблицах найдется хотя бы несколько колонок, именованных схожим образом. Эти колонки – хорошие претенденты на рассмотрение. Если, к примеру, я вижу стандартную таблицу, названную «Заказы» (Orders), в ней, скорее всего, будет колонка под названием «Номер покупателя» ([Customer No.]) или что-то в этом роде. И, вероятно, во всех таблицах этой базы данных, где важен и должен быть указан покупатель, станет повторяться колонка с точно таким же названием. А это как раз то, что нам ищем.
Большие таблицы и зависимости
Первой процедурой является уже известная процедура BigTables, основанная на системной процедуре sp_spaceused. Я модифицировал и слегка расширил код Билла Гразиано (http://www.sqlteam.com/article/finding-the-biggest-tables-in-a-database). Эта процедура выдает верхнюю часть списка для самых больших таблиц (количество строк, зарезервированный/использованный объем и размер индекса) и одновременно показывает количество зависимых объектов для каждой таблицы. Это дает важную подсказку по поводу каждой таблицы, потому что «большие таблицы» могут попросту оказаться свалками данных – к примеру, картинки (много дискового пространства), некоторые таблицы подсчетов (много строк) и т.п. Но если известно, что некая таблица используется в определенных представлениях или хранимых процедурах, можно точнее фокусировать свой поиск.
CREATE PROCEDURE spBigTables As
DECLARE @id int
DECLARE @pages int
DECLARE @used dec(15)
DECLARE @tTableName sysname
CREATE TABLE #spt_space
(
objid int not null,
rows int null,
reserved dec(15) null,
data dec(15) null,
indexp dec(15) null,
unused dec(15) null,
dependants int null
)
CREATE TABLE #tDepends (
oType smallint, oobjname sysname, oowner varchar(50), osequence smallint)
DECLARE c_TABLEs CURSOR STATIC FORWARD_ONLY READ_ONLY
FOR SELECT ID FROM sysobjects WHERE xtype = 'U'
OPEN c_TABLEs
FETCH NEXT FROM c_TABLEs INTO @id
WHILE @@FETCH_STATUS = 0
BEGIN
INSERT INTO #spt_space (objid, reserved)
SELECT objid = @id, SUM(reserved)
FROM sysindexes WHERE indid in (0, 1, 255) AND id = @id
SELECT @pages = SUM(dpages) FROM sysindexes WHERE indid < 2 AND id = @id
SELECT @pages = @pages + ISNULL(SUM(used), 0)
FROM sysindexes WHERE indid = 255 AND id = @id
UPDATE #spt_space
SET data = @pages
WHERE objid = @id
SET @used = (
SELECT SUM(used) FROM sysindexes WHERE indid in (0, 1, 255) AND id = @id)
UPDATE #spt_space
SET indexp = @used - data
WHERE objid = @id
UPDATE #spt_space
SET unused = reserved - @used
WHERE objid = @id
UPDATE #spt_space
SET rows = i.rows FROM sysindexes i
WHERE i.indid < 2 AND i.id = @id AND objid = @id
SET @tTableName = (SELECT name FROM sysobjects WHERE id=@id)
INSERT INTO #tDepends EXEC sp_MSdependencies @tTableName, null, 1315327
UPDATE #spt_space
SET dependants = (SELECT COUNT(*) FROM #tDepends)
WHERE objid = @id
TRUNCATE TABLE #tDepends
FETCH NEXT FROM c_TABLEs INTO @id
END
SELECT TOP 25
TABLE_Name = (SELECT LEFT(name,25) FROM sysobjects WHERE id = objid),
rows,
reservedKB = STR(reserved * d.low / 1024.) + ' ' + 'KB',
dataPrcnt = STR(data / nullif(reserved,0) * 100) + ' %',
indexPrcnt = STR(indexp / nullif(reserved,0) * 100) + ' %',
unusedPrcnt = STR(unused/nullif(reserved,0) * 100) + ' %',
dependants
FROM #spt_space, master.dbo.spt_values d
WHERE d.number = 1
AND d.type = 'E' –-размер страницы
ORDER BY rows DESC
DROP TABLE #spt_space
CLOSE c_TABLEs
DEALLOCATE c_TABLEs
GO
EXEC spBigTables
|
На рисунке ниже приводится пример с результатом вышеописанных действий.

ПРИМЕЧАНИЕ
Примечание: Самый простой путь проверки зависимых объектов в Enterprise Manager или Management Studio – при работе с таблицей вывести на экран зависимости правой кнопкой мыши, но в SQL 2000 не слишком элегантно делать это с помощью запроса. Там есть системная хранимая процедура sp_depends, которая использует таблицу sysdepends, а также еще более подробная, но недокументированная процедура sp_msdependencies. Последняя представляет собой целую кучу кода, и я даже не пытаюсь в нем разобраться, а просто использую sp_msdependencies, чтобы заполнить временную таблицу. К сожалению, это может вызвать кое-какие ошибки (не особо опасные), поэтому – на тот случай, если вы не хотите видеть вообще никаких ошибок – я еще включил туда фрагмент для использования sp_depends. Не хотелось бы так говорить, но: игнорируйте ошибки и оценивайте результаты запроса.
|
Поиск колонок со схожими названиями
Целью второй процедуры является поиск таблиц со схожими названиями колонок. Она перечисляет все колонки заданной таблицы, игнорируя содержащие некоторые типы данных (картинки, отметки времени и т.д.). Кроме того, данная процедура не принимает во внимание колонки, которые не использованы в индексах связанных таблиц. Это делается для сужения результата. Если на выходе вы получаете мало строк с потенциально связанными таблицами, можно попробовать закомментировать строку со связью на таблицу sysindexes и/или попытаться проверить частичные совпадения с названиями колонок, используя символы процента.
CREATE PROCEDURE spColumnSearch
(@tTableName VARCHAR(150))
As
SELECT name INTO #tmpCols FROM syscolumns
WHERE 1=1
AND id = (SELECT id FROM sysobjects WHERE name=@tTableName and xtype='U')
AND xtype not in (34, 35, 99, 189)
SELECT c.name As Column_name,
(SELECT data_type
FROM INFORMATION_SCHEMA.COLUMNS
WHERE table_name=o.name
AND column_name=c.name
) As Column_type,
o.name As Table_name,
(SELECT isnull(rowcnt,0)
FROM sysindexes
WHERE id = (SELECT id
FROM sysobjects
WHERE name=o.name and xtype='U')
AND indid IN(0,1)) As RowsCount
FROM sysobjects o, syscolumns c, #tmpCols tc
WHERE o.id=c.id and o.xtype='U' and c.name=tc.name
AND c.id in (SELECT k.id
FROM sysindexkeys k, sysindexes x
WHERE k.id=c.id AND k.colid=c.colid
AND k.indid=x.indid
AND (x.status & 64) = 0 AND c.id=x.id)
ORDER BY c.name, o.name
DROP TABLE #tmpCols
GO
EXEC spColumnSearch 'Orders'
|
На рисунке ниже приводится пример результата вышеописанных действий.
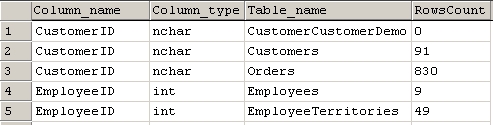
ПРИМЕЧАНИЕ
Примечание: Конечно же, необходимо проверять и вторичные ключи.
|
Ограничение в пределах таблицы
Третья процедура возвращает некоторую полезную информацию о выбранной таблице. Это может оказаться важным, особенно если вы намереваетесь удалить пустые или почти пустые колонки (вы уже просмотрели таблицы с сотнями колонок, большинство из которых на самом деле не используются). Процедура предоставляет данные о количестве индексов, зависимостей (повторяю: оценивайте результаты запроса, не обращая внимания на возможные ошибки со стороны sp_msdependencies), строк, колонок и различающихся записей в колонке.
CREATE PROCEDURE spTableQuality
(@tTableName VARCHAR(150))
As
DECLARE @tTableID int
SET @tTABLEID =
(SELECT id FROM sysobjects WHERE name=@tTableName and xtype='U')
SELECT name INTO #tmpCols FROM syscolumns
WHERE 1=1
AND id = @tTABLEID
AND xtype not in (34, 35, 36, 99, 189)
CREATE TABLE #tDepends
(oType smallint, oobjname sysname, oowner varchar(50), osequence smallint)
INSERT INTO #tDepends EXEC sp_MSdependencies @tTableName, null, 1315327
SELECT @tTableName As TableName,
(SELECT COUNT(*)
FROM INFORMATION_SCHEMA.COLUMNS
WHERE table_name=@tTableName) As ColumnsCount,
(SELECT COUNT(*)
FROM sysindexes si
WHERE si.id = @tTableID and (si.status & 64) = 0) As IndexesCount,
(SELECT COUNT(*) FROM #tDepends) As DependenciesCount,
CREATE TABLE #tTABLEQuality
(
Column_Name sysname,
Column_Type varchar(50),
Count_Distincts int
)
DECLARE @tColName VARCHAR(255)
DECLARE cCols CURSOR STATIC FORWARD_ONLY READ_ONLY
FOR SELECT name FROM #tmpCols
OPEN cCols
FETCH NEXT FROM cCols INTO @tColName
WHILE @@FETCH_STATUS = 0
BEGIN
EXECUTE('INSERT INTO #tTABLEQuality
(Column_Name, Column_Type, Count_Distincts)
SELECT t.name,
(SELECT data_type
FROM INFORMATION_SCHEMA.COLUMNS
WHERE table_name='''+@tTableName+'''
AND column_name='''+@tColName+'''),
COUNT(distinct isnull([' + @tColName + '],0))
FROM [' + @tTableName + '], #tmpCols t
WHERE t.name=''' + @tColName + ''' GROUP BY t.name')
FETCH NEXT FROM cCols INTO @tColName
END
CLOSE cCols
DEALLOCATE cCols
SELECT * FROM #tTABLEQuality order by Count_Distincts asc, Column_Name
DROP TABLE #tTABLEQuality
DROP TABLE #tmpCols
DROP TABLE #tDepends
GO
EXEC spTableQuality 'KommTran'
|
На рисунке ниже приводится пример результата вышеописанных действий.
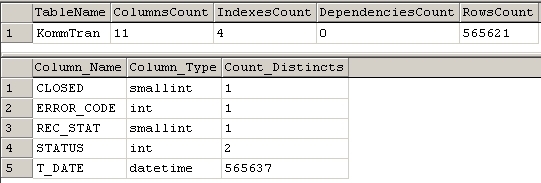
ПРИМЕЧАНИЕ
Примечание: Такие результаты позволяют понять, что происходит с таблицей table "KommTrans". Все хранится в поле T_DATE. Остальные колонки, скорее всего, не имеют большого значения (для пользователя, интересующегося содержанием).
|
Заключение
Проработка подобным образом, к примеру, сотен таблиц займет несколько секунд, но имейте в виду, что при работе с большим количеством, возможно, лучше подогнать запросы под конкретные условия. Однажды я обработал таким образом базу данных размером 200 GB, содержащую 30 000 таблиц – проверка зависимостей заняла 5 часов! Что это означает: еще раз хорошенько продумайте, как именно вы хотите проверить связи объектов. Описанные выше процедуры хороши для начинающих, но пару раз я пользовался ими и в серьезных случаях. Я использовал их в SQL 2000; они действует и в SQL 2005, но в последней версии должен существовать более легкий способ это делать. Занятное наблюдение: в SQL 2005, в отличие от SQL 2000, процедура sp_msdependencies ведет себя вполне прилично. По крайней мере, во время экспериментов с ней у меня не было ошибок.
|
Технология Клиент-Сервер 2009'1
|
|
|
Copyright © 1994-2016 ООО "К-Пресс"
