 |
Технология Клиент-Сервер 2010'1
|
|
|
Быстрая нормализация денормализованных источников данных с использованием суррогатных ID
Автор: Адам Аспин
Опубликовано: 08.07.2010
Версия текста: 1.1
Эта статья – как и множество других, написанных желающими поделиться опытом, подозреваю я – основана на решении реальной проблемы. Проблема была обманчиво проста: как загрузить данные из одной системы, использующей свою архитектуру данных, в другую систему, основанную на совершенно другой реляционной модели. Да, исходные данные предоставлялись с использованием плоского (или денормализованного) представления данных. Просто чтобы жить было интереснее, исходные данные должны предоставляться без сколько-нибудь пригодной к использованию информации о первичных и внешних ключах, а БД назначения должна использовать целочисленные суррогатные ключи во всех таблицах, сгенерированных с использованием SQL Server-функции IDENTITY. Конечно, данные должны вноситься в существующие таблицы, так что есть множество уже существующих суррогатных ключей, и архитектор хочет, чтобы ключи равномерно возрастали, чтобы обеспечивать максимально быстрый доступ к системе для существующих приложений.
Хорошие новости состоят в том, что исходные данные гарантированно не содержат дубликатов и считаются чистыми и готовыми к загрузке к загрузке в систему назначения. Еще одно – и это нетривиальный аспект проблемы – каждая строка/запись в исходных данных это полный и согласованный набор данных, который отображается на разрозненный реляционный набор таблиц назначения. Другими словами, нам не придется работать над изоляцией множественных строк/записей исходного набора данных для создания плоской или денормализованной записи, так что мороки с множественными строками не будет. Наконец (и это важно), мы используем SQL Server 2005 или 2008, а не более раннюю версию.
Никаких настоящих проблем – на самом деле у клиента было готовое решение, использовавшее курсор для перебора в цикле денормализованных исходных данных, и генерации и применения суррогатных ключей. Проблемы в этом процессе заключались в следующем:
- Он был громоздким и его было трудно поддерживать.
- Он использовал множество ссылок @SCOPE_IDENTITY, потенциально приводящих к ошибкам.
- И, что хуже всего, обработка миллиона исходных записей занимала два часа.
Теперь, перед поиском решения, я хочу обойти два вопроса – использование курсоров и использование «натуральных» вместо «суррогатных» ключей. Я знаю, что вокруг обоих вопросов кипят страсти, которые могут помешать обсуждению, так что здесь я просто укажу бизнес-требования:
- Использование суррогатных ключей – это часть корпоративного стандарта.
- Нужно ускорить процесс - а использование логики, основанной на использовании наборов данных, является хорошей отправной точкой.
Так что если вы предпочитаете «натуральные» ключи и/или любите/ненавидите курсоры – или еще как-то, в любой комбинации – поищите другое место для споров, здесь я говорю только о решении конкретной проблемы, но таком, которое, по моему опыту, может применить во многих решениях по интеграции данных.
В любом случае, вернемся к проблеме. Данные хранятся в большом денормализованном наборе записей (возможно, результате выражения OPENQUERY на связанном сервере, или выражения OPENROWSET, или сложного запроса к нескольким БД, или даже в плоском файле, импортированном во временную таблицу с помощью SSIS), который доступен через SQL Server, и который придется нормализовать, используя несколько таблиц. Чтобы упростить пример, и одновременно показать сложности, предположим, что в нормализации участвуют три таблицы:
- Таблица "Client"
- Таблица "Order Header"
- Таблица "Order Detail"
Чтобы сделать проблему яснее, давайте посмотрим на следующие три примера записей из исходных данных, имеющих вид текстового файла:
ClientName Town OrderNumber OrderDate ItemID ItemQuantity ItemCost ItemTotal
Jon Smythe Stoke 1 29/09/2009 777 5 9.99 49.95
Jon Smythe Stoke 2 25/10/2009 888 3 19.99 59.97
Jon Smythe Stoke 2 05/11/2009 999 10 49.99 499.9
|
На рисунке 1 показаны таблицы назначения:
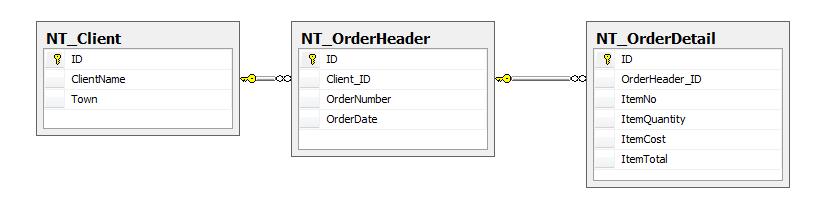
Рисунок 1.
Это, очевидно, это очень большое упрощение сложности и детализации реальных исходных и конечных данных, но здесь я рассказываю о концепции, а не о головной боли нескольких дней!
Теперь, прежде чем погрузиться в кодирование, вернемся на шаг назад и посмотрим на нормализуемые данные:
Так, если все пойдет нормально, можно увидеть, какие столбцы в какие таблицы вставляются.
Можно приступать к основной проблеме – как задать суррогатные ID, не конфликтующие с существующими ID в трех таблицах, и как выполнить быструю загрузку.
На секундочку переключимся на таблицы назначения. Исходные данные добавят:
- Одну запись в таблицу "Client".
- Две записи в таблицу "Order Header".
- Три записи в таблицу "Order Detail".
Таким образом, будет добавлен 1 новый ID в таблицу "Client", два (и соответствующий Client ID) в таблицу "Order Header", и три (и соответствующий Order Header ID) в таблицу "Order Detail". Это сохранит ссылочную целостность исходных данных.

Рисунок 2.
Следующий вопрос должен, похоже, быть таким: когда добавлять эти ID? Кажется, есть две основные возможности:
- При добавлении данных в таблицы назначения.
- В исходную таблицу, а затем перенести их в таблицы назначения.
Здесь, поскольку имеющееся решение, использующее курсор, использует первый подход, а также из чувства противоречия, я попробую использовать второй подход – добавить все нужные суррогатные ID в денормализованные исходные данные, и посмотрю, можно ли их использовать при переносе данных в нормализованные таблицы.
Это, кажется, подразумевает:
- Добавление колонки в таблицу с исходными данными для каждого ID, нужного в таблице назначения.
- В каждой таблице назначения нужно найти последний (самый большой) ID.
- Добавить ID, монотонно увеличивающиеся в соответствии с реляционной структурой.
Минуточку, последнее выглядит довольно сложно. На самом деле это не так, это просто значит, что в приведенном выше примере новые колонки будут выглядеть примерно так:
ClientID OrderHeaderID OrderDetailID
1 1 1
1 2 2
1 2 3
|
Итак, на самом нижнем уровне гранулярности, будет новый, отдельный ID для каждой записи Order Detail, два ID для двух записей Order Header и один ID для клиента.
Все хорошо – но возможно ли?
Как ни удивительно (или независимо от уровня вашего цинизма), это не только возможно, но и довольно просто. Сейчас мы перейдем к коду, и вы поймете, как.
Первое, получим ID
Здесь нет ничего сложного, мы просто должны получить самый поздний ID из колонки IDENTITY двух из трех таблиц назначения. Да, в этом сценарии реально нужны только две, так как суррогатный ID для таблицы самого нижнего уровня реляционной иерархии (в этом примере это таблица NT_OrderDetail) можно добавить совершенно нормально с использованием колонки IDENTITY:
DECLARE @Client_ID INT
DECLARE @OrderHeader_ID INT
SELECT @Client_ID = ISNULL(IDENT_CURRENT('NT_Client'),0) + 1
SELECT @OrderHeader_ID = ISNULL(IDENT_CURRENT('NT_OrderHeader'),0) + 1
|
ПРИМЕЧАНИЕ
Обратите внимание на использование ISNULL – это позволяет создать самый первый ID, даже если таблица пуста.
Да, можно использовать MAX(), чтобы получить последнее значение ID, но IDENT_CURRENT, несомненно, быстрее.
|
Второе, получаем данные
В этом примере я исхожу из того, что исходные данные находятся во вспомогательной таблице SQL Server (хотя, как говорилось выше, это непринципиально), и что запрос для получения данных выглядит так:
SELECT
ClientName
,Town
,OrderNumber
,OrderDate
,ItemID
,ItemQty
,ItemCost
,ItemTotal
,CAST(NULL AS INT) AS Client_ID
,CAST(NULL AS INT) AS OrderHeader_ID
INTO #Tmp_SourceData
FROM dbo.NT_SourceData
|
Прямо сейчас нужно обратить внимание на несколько важных моментов:
<...>
Результат
Так стоит ли такой подход затраченных усилий?
Что ж, начнем с того, что посмотрим, ускорился ли процесс. Как вы помните, раньше на один миллион записей уходило два часа. На той же аппаратуре с использованием описанного выше подхода это заняло 104 секунды.
Да, именно так, 1.44% от исходного времени – то есть в 69 раз быстрее.
«Ага», – скажут процедурные программисты: «А были ли данные в таблицах назначения теми же самыми?"
Ну... да, в точности те же. Корпоративная команда тестировщиков это доказала.
Что насчет сложности кода и его поддержки? Это, конечно, труднее подсчитать. Ограничусь тем, что скажу, что в решении на основе курсора было в два раза больше строк кода.
А как насчет системных ресурсов? Тесты опять же показывают, что основанный на наборах данных подход использует существенно меньше ресурсов. На нашем тестовом сервере было проведено несколько стресс-тестов, но я у меня нет желания заниматься публикацией результатов. Если кто-то захочет провести тестирование за меня и дать мне готовые цифры, я буду признателен.
Дальнейшие идеи
Прежде чем расстаться с этим подходом к нормализации данных, рассмотрим несколько потенциальных отрицательных моментов.
Одна из потенциальных проблем этого подхода – риск того, что другой процесс будет вставлять данные в таблицы назначения одновременно со вставкой набора данных. Конечно, это сильно нарушит ссылочную целостность. Если вы изменяете данные во вспомогательной БД, или в качестве подготовки данных при работе с хранилищем данных, то вы, вероятно, контролируете всю процедуру, и можете не допускать параллельного исполнения каких-либо других процессов. В этом случае, пока вы тщательно следите за своим ETL, проблем не будет.
Заключение
Итак, мы получили большой выигрыш в скорости, и куда более простой код, чем при использовании курсора. Конечно, этот подход может потребовать экспериментов, но, без сомнения, производительность и удобство сопровождения при его использовании значительно улучшаются.
........................
"С полным содержанием данной статьи можно ознакомиться в печатной версии журнала"
Любой из материалов, опубликованных на этом сервере, не может быть воспроизведен в какой бы
то ни было форме и какими бы то ни было средствами без письменного разрешения владельцев авторских
прав.
Copyright © 1994-2016 ООО "К-Пресс"
