 |
Технология Клиент-Сервер 2010'1
|
|
|
ROW_NUMBER(): Эффективная альтернатива подзапросам
Автор: Фрэнсис Родригес
Опубликовано: 08.07.2010
Версия текста: 1.1
Введение
SQL Server 2005 содержит набор функций ранжирования и «оконных» функций (windowing function), которые можно использовать, чтобы сравнивать данные и возвращать только нужные записи. Например, цикл разработки продукта может включать сотни релизов, и у этих релизов могут быть ассоциированные с ними версии: версия «0» со множеством подверсий, версия «1» со своими подверсиями, и т.д. Если сохраняется история релизов конкретного продукта, можно проанализировать, сколько версий создается до выхода продукта. Одно выражение ORDER BY не может выполнить это, поскольку запрос будет, скорее всего, возвращать историю продукта, а вовсе не последний релиз каждой версии.
Сценарий 1 – версионный
Чтобы продемонстрировать использование «оконной» функции ROW_NUMBER(), я буду использовать БД AdventureWorks. В частности, я использую данные из таблицы Production.ProductCostHistory. Продукты из этой таблицы идентифицируются по колонке ProductID; это внешний ключ таблицы Production.Product. Используя таблицу Production.ProductCostHistory, я смоделировал данные, чтобы создать версии для каждого продукта в таблице. Я использовал процесс генерирования случайных чисел, чтобы создать для каждого продукта такие атрибуты как Version, MinorVersion and ReleaseVersion. Предполагается, что эти атрибуты предоставляют подробную информацию о товаре. Здесь 7.0.59 означает, что в данное время используется 7 версия продукта, подверсия означает итерацию данной версии, а версия релиза этой конкретно инсталляции – 59. Следующая итерация жизненного цикла продукта может быть, например, 7.2.19. Я также использовал существующую таблицу StandardCost для создания разных цен для каждой из версий, чтобы эти версии имели какой-то смысл.
Я создал таблицу Production.ProductVersion с ProductID, Version, MinorVersion и ReleaseVersion в качестве первичного ключа, и StandardCost в качестве атрибута. Я вставил в эту таблицу смоделированные данные, сгенерированные кодом, чтобы смоделировать простую историю версий/стоимости продукта.
CREATE TABLE Production.ProductVersion
(
ProductID int NOT NULL,
Version int NOT NULL,
MinorVersion int NOT NULL,
ReleaseVersion int NOT NULL,
StandardCost numeric(30, 4) NOT NULL,
CONSTRAINT PK_ProductVersion PRIMARY KEY CLUSTERED
(
ProductID ASC,
Version ASC,
MinorVersion ASC,
ReleaseVersion ASC
)
);
|
Для заполнения таблицы случайными данными я использовал следующий код. Я создал данные, используя общее табличное выражение (common table expression, CTE), и после создания вставил их в таблицу. Данные основываются на таблице Production.ProductCostHistory.
WITH ProductVersion
AS
(
SELECT ProductID,
1 AS Version,
CAST((ABS(CHECKSUM(NEWID())) % 1001) AS INT) AS MinorVersion,
CAST((ABS(CHECKSUM(NEWID())) % 20001) AS INT) AS ReleaseVersion,
CAST(StandardCost AS NUMERIC(30,4)) AS StandardCost
FROM Production.ProductCostHistory WITH (NOLOCK)
UNION ALL
SELECT
ProductID,
ABS(CHECKSUM(NEWID())) % 3 AS Version,
CAST((ABS(CHECKSUM(NEWID())) % 1001) AS INT) AS MinorVersion,
CAST((ABS(CHECKSUM(NEWID())) % 20001) AS INT) AS ReleaseVersion,
CAST((CAST(StandardCost AS NUMERIC(30,4)) * 1.10) AS NUMERIC(30,4))
AS StandardCost
FROM Production.ProductCostHistory WITH (NOLOCK)
UNION ALL
SELECT
ProductID,
ABS(CHECKSUM(NEWID())) % 5 AS Version,
CAST((ABS(CHECKSUM(NEWID())) % 1001) AS INT) AS MinorVersion,
CAST((ABS(CHECKSUM(NEWID())) % 20001) AS INT) AS ReleaseVersion,
CAST((CAST(StandardCost AS NUMERIC(30,4)) * 2.10) AS NUMERIC(30,4))
AS StandardCost
FROM Production.ProductCostHistory WITH (NOLOCK)
)
INSERT INTO Production.ProductVersion
SELECT ProductID,
Version,
MinorVersion,
ReleaseVersion,
MAX(StandardCost) AS StandardCost
FROM ProductVersion
GROUP BY ProductID,
Version,
MinorVersion,
ReleaseVersion;
|
ABS(CHECKSUM(NEWID())) используется как генератор случайных чисел; оператор модуля дает верхнюю границу для генерируемых случайных чисел. Функция NEWID() гарантированно генерирует GUID для каждой строки. Оператор GROUP BY используется, чтобы исключить любые возможные нарушения ограничений внешнего ключа.
Смысл этого упражнения в том, чтобы уменьшить сложность некоторого кода с помощью использования «оконной функции ROW_NUMBER(). Предположим, что вам нужно возвратить только последнюю версию продукта с ассоциированными MinorVersion, ReleaseVersion и StandardCost. Следующий запрос не возвращает правильный набор результатов:
SELECT
ProductID,
MAX(Version) AS Version,
MAX(MinorVersion) AS MinorVersion,
MAX(ReleaseVersion) AS ReleaseVersion,
MAX(StandardCost) AS StandardCost
FROM Production.ProductVersion WITH (NOLOCK)
GROUP BY ProductID;
|
На самом деле этот запрос нарушает целостность записей в таблице. Он просто возвращает максимальные значения Version, MinorVersion, ReleaseVersion и StandardCost для конкретного продукта. В эту ловушку нетрудно попасться. Сравните результаты на рисунках 2 и 3. Настоящие данные из Production.ProductVersion показаны на рисунке 1.
Следующий пример запроса содержит настоящие требования и выдает корректный результат, но он сложный и запутанный.
SELECT ProductID,
(
SELECT MAX(Version)
FROM Production.ProductVersion pv2 WITH (NOLOCK)
WHERE pv2.ProductID = pv.ProductID
) AS Version,
(
SELECT MAX(MinorVersion)
FROM Production.ProductVersion pv3 WITH (NOLOCK)
WHERE pv3.ProductID = pv.ProductID
AND pv3.Version = (
SELECT MAX(Version)
FROM Production.ProductVersion pv2 WITH (NOLOCK)
WHERE pv2.ProductID = pv.ProductID
)
) AS MinorVersion,
(
SELECT MAX(ReleaseVersion)
FROM Production.ProductVersion pv4 WITH (NOLOCK)
WHERE pv4.ProductID = pv.ProductID
AND pv4.Version = (
SELECT MAX(Version)
FROM Production.ProductVersion pv2 WITH (NOLOCK)
WHERE pv2.ProductID = pv.ProductID
)
AND pv4.MinorVersion = (
SELECT MAX(MinorVersion)
FROM Production.ProductVersion pv3 WITH (NOLOCK)
WHERE pv3.ProductID = pv.ProductID
AND pv3.Version = (
SELECT MAX(Version)
FROM Production.ProductVersion pv2
WITH (NOLOCK)
WHERE pv2.ProductID = pv.ProductID
)
)
) AS ReleaseVersion,
(
SELECT StandardCost
FROM Production.ProductVersion pv5 WITH (NOLOCK)
WHERE pv5.ProductID = pv.ProductID
AND pv5.Version = (
SELECT MAX(Version)
FROM Production.ProductVersion pv2 WITH (NOLOCK)
WHERE pv2.ProductID = pv.ProductID
)
AND pv5.MinorVersion = (
SELECT MAX(MinorVersion)
FROM Production.ProductVersion pv3 WITH (NOLOCK)
WHERE pv3.ProductID = pv.ProductID
AND pv3.Version = (
SELECT MAX(Version)
FROM Production.ProductVersion pv2
WITH (NOLOCK)
WHERE pv2.ProductID = pv.ProductID
)
)
AND pv5.ReleaseVersion = (
SELECT MAX(ReleaseVersion)
FROM Production.ProductVersion pv4 WITH (NOLOCK)
WHERE pv4.ProductID = pv.ProductID
AND pv4.Version = (
SELECT MAX(Version)
FROM Production.ProductVersion pv2
WITH (NOLOCK)
WHERE pv2.ProductID = pv.ProductID
)
AND pv4.MinorVersion = (
SELECT MAX(MinorVersion)
FROM Production.ProductVersion pv3
WITH (NOLOCK)
WHERE pv3.ProductID = pv.ProductID
AND pv3.Version = (
SELECT MAX(Version)
FROM Production.ProductVersion pv2
WITH (NOLOCK)
WHERE pv2.ProductID = pv.ProductID
)
)
)
) AS StandardCost
FROM Production.ProductVersion pv WITH (NOLOCK)
GROUP BY ProductID;
|
Этот запрос использует вложенные подзапросы, чтобы обеспечить целостность каждой строки. Первый подзапрос (строки 117-25 в коде) выдает максимальную версию для каждого продукта. Второй подзапрос выдает максимальную подверсию для максимальной версии каждого продукта. Подзапрос в выражении WHERE обеспечивает соответствие MinorVersion и Version. Третий подзапрос:
SELECT MAX(ReleaseVersion)
FROM Production.ProductVersion pv4 WITH (NOLOCK)
WHERE pv4.ProductID = pv.ProductID
AND pv4.Version = (
SELECT MAX(Version)
FROM Production.ProductVersion pv2 WITH (NOLOCK)
WHERE pv2.ProductID = pv.ProductID
)
AND pv4.MinorVersion = (
SELECT MAX(MinorVersion)
FROM Production.ProductVersion pv3 WITH (NOLOCK)
WHERE pv3.ProductID = pv.ProductID
AND pv3.Version = (
SELECT MAX(Version)
FROM Production.ProductVersion pv2 WITH (NOLOCK)
WHERE pv2.ProductID = pv.ProductID
)
)
|
выдает максимальное значение ReleaseVersion для максимальной MinorVersion максимальной версии каждого продукта. Еще раз – подзапросы гарантируют, что выбираются только полные строки данных. Если эта логика звучит слишком сложно, то это просто потому, что она такая и есть. Расчетная стоимость поддерева для этого запроса – 0.583005. Сюда входят несколько операций Clustered Index Scan и Seek. План запроса показан на рисунке 4. Сложность подхода с подзапросами может еще увеличиться в случае изменения требований.
Упрощенный подход использует функцию ROW_NUMBER(), как показано ниже.
WITH RowExample1
AS
(
SELECT ROW_NUMBER() OVER(PARTITION BY ProductID
ORDER BY ProductID,
Version DESC,
MinorVersion DESC,
ReleaseVersion DESC
) AS MaxVersion,
ProductID,
Version,
MinorVersion,
ReleaseVersion,
StandardCost
FROM Production.ProductVersion pv WITH (NOLOCK)
)
SELECT ProductID,
Version,
MinorVersion,
ReleaseVersion,
StandardCost
FROM RowExample1
WHERE MaxVersion = 1
ORDER BY ProductID;
|
Набор результатов для этого запроса показан на рисунке 3.
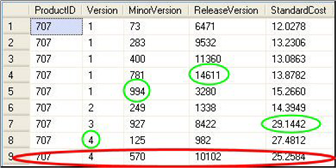
Рисунок 1. Пример исполнения Production.ProductVersion.

Рисунок 2. Пример исполнения некорректного запроса.

Рисунок 3. Пример исполнения правильно реализованного запроса.
Выражение PARTITION BY позволяет назначить набор номеров строк для всех отдельных продуктов. Когда встречается новый ProductID, нумерация строк будет начинаться с 1 и увеличиваться для каждой строки с тем же ProductID. Номер строки будет назначен согласно порядку сортировки колонок, указанному в выражении OVER оператора ORDER BY. Расчетная стоимость поддерева для этого, улучшенного, запроса - 0.039954. Запрос содержит только одну операцию Clustered Index Scan. План запроса показан на рисунке 5.
Благодаря выражению OVER функция ROW_NUMBER() может назначить номер каждой строке в запросе. То, что я упорядочил разделы по ProductID и затем, в убывающем порядке, по Version, MinorVersion и ReleaseVersion, гарантирует, что максимальная версия будет содержаться в первой строке каждого раздела ProductID. Это позволяет мне использовать простой предикат WHERE MaxVersion = 1 вместо запутанной логики подзапросов из предыдущего запроса.
Чтобы проверить воздействие индексирования на разницу между двумя методами, я использовал следующую таблицу.
CREATE TABLE Production.ProductVersion2
(
ProductID int NOT NULL,
Version int NOT NULL,
MinorVersion int NOT NULL,
ReleaseVersion int NOT NULL,
StandardCost numeric(30, 4) NOT NULL,
);
|
Я использовал следующий запрос, чтобы сгенерировать большой набор случайных данных для сравнения расчетной стоимости запроса при разных размерах наборов данных.
WITH RCTE
AS
(
SELECT 0 AS X,
ProductID,
1 AS Version,
CAST((ABS(CHECKSUM(NEWID())) % 1001) AS INT) AS MinorVersion,
CAST((ABS(CHECKSUM(NEWID())) % 20001) AS INT) AS ReleaseVersion,
CAST(StandardCost AS NUMERIC(30,4)) AS StandardCost
FROM Production.ProductCostHistory WITH (NOLOCK)
UNION ALL
SELECT X + 1,
pv.ProductID,
ABS(CHECKSUM(NEWID())) % 3 AS Version,
CAST((ABS(CHECKSUM(NEWID())) % 1001) AS INT) AS MinorVersion,
CAST((ABS(CHECKSUM(NEWID())) % 20001) AS INT) AS ReleaseVersion,
CAST((CAST(pv.StandardCost AS NUMERIC(30,4)) * 1.10) AS NUMERIC(30,4)) AS StandardCost
FROM RCTE pv
WHERE X < 14
UNION ALL
SELECT X + 2,
pv.ProductID,
ABS(CHECKSUM(NEWID())) % 5 AS Version,
CAST((ABS(CHECKSUM(NEWID())) % 1001) AS INT) AS MinorVersion,
CAST((ABS(CHECKSUM(NEWID())) % 20001) AS INT) AS ReleaseVersion,
CAST((CAST(pv.StandardCost AS NUMERIC(30,4)) * 2.10)
AS NUMERIC(30,4)) AS StandardCost
FROM RCTE pv
WHERE X < 15
)
INSERT INTO Production.ProductVersion2
SELECT TOP (100000) ProductID,
Version,
MinorVersion,
ReleaseVersion,
MAX(StandardCost)
FROM RCTE
GROUP BY ProductID,
Version,
MinorVersion,
ReleaseVersion
OPTION (MAXRECURSION 0);
|
Ниже приведены расчетные стоимости запросов для разных размеров строк. Я начал с 1000, поскольку у меня есть 286 разных ProductID, и если начать со 100, слишком много строк будут исключены.
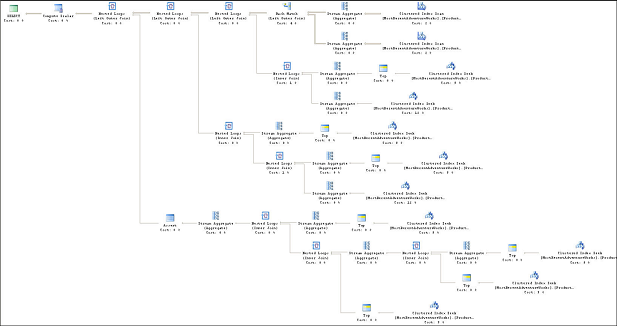
Рисунок 5. Подход с подзапросами

Рисунок 5. Подход с ROW_NUMBER()
Следующая таблица показывает расчетную стоимость запроса для Production.ProductVersion. Реализация на подзапросах реально заняла менее 1 секунды, а реализация на ROW_NUMBER() – около 2 секунд для 1 000 000 строк.
Таблица 1. Расчетная стоимость запроса (с индексацией)
|
Число строк
|
Стоимость реализации на подзапросах
|
Стоимость
реализации на ROW_NUMBER()
|
|
1000
|
0.0652462
|
0.0355736
|
|
10000
|
0.238573
|
0.673282
|
|
100000
|
2.2258
|
5.97198
|
|
1000000
|
14.3881
|
83.7228
|
Следующая таблица показывает расчетную стоимость запроса для Production.ProductVersion2. Реализация на подзапросах заняла 43 секунды, а реализация на ROW_NUMBER() – около 5 секунд для 1 000 000 строк.
Таблица 2. Расчетная стоимость запроса (без индексации)
|
Число строк
|
Стоимость реализации на подзапросах
|
Стоимость
реализации на ROW_NUMBER()
|
|
1000
|
0.0355736
|
0.225896
|
|
10000
|
1.6397
|
0.673282
|
|
100000
|
44.1332
|
5.97202
|
|
1000000
|
448.47
|
83.7229
|
Эти результаты зависят от аппаратного обеспечения, используемого для выполнения запросов. Колонка ROW_NUMBER() показывает, что индексация практически не влияет на стоимость этой реализации запроса, но очень важна для реализации на подзапросах.
Сценарий 1 – изменение требований
Предположим, что требования изменились, и нужно получить максимальную MinorVersions для каждой комбинации (ProductID, Version). Подход на запросах в новых условиях будет выглядеть так:
SELECT ProductID,
Version,
(
SELECT MAX(MinorVersion)
FROM Production.ProductVersion pv3 WITH (NOLOCK)
WHERE pv3.ProductID = pv.ProductID AND pv3.Version = pv.Version
) AS MinorVersion,
(
SELECT MAX(ReleaseVersion)
FROM Production.ProductVersion pv4 WITH (NOLOCK)
WHERE pv4.ProductID = pv.ProductID
AND pv4.Version = pv.Version
AND pv4.MinorVersion = (
SELECT MAX(MinorVersion)
FROM Production.ProductVersion pv3 WITH (NOLOCK)
WHERE pv3.ProductID = pv.ProductID
AND pv3.Version = pv.Version
)
) AS ReleaseVersion,
(
SELECT StandardCost
FROM Production.ProductVersion pv5 WITH (NOLOCK)
WHERE pv5.ProductID = pv.ProductID
AND pv5.Version = pv.Version
AND pv5.MinorVersion = (
SELECT MAX(MinorVersion)
FROM Production.ProductVersion pv3 WITH (NOLOCK)
WHERE pv3.ProductID = pv.ProductID
AND pv3.Version = pv.Version
)
AND pv5.ReleaseVersion = (
SELECT MAX(ReleaseVersion)
FROM Production.ProductVersion pv4 WITH (NOLOCK)
WHERE pv4.ProductID = pv.ProductID
AND pv4.Version = pv.Version
AND pv4.MinorVersion = (
SELECT MAX(MinorVersion)
FROM Production.ProductVersion pv3
WITH (NOLOCK)
WHERE pv3.ProductID = pv.ProductID
AND pv3.Version = pv.Version
)
)
) AS StandardCost
FROM Production.ProductVersion pv WITH (NOLOCK)
GROUP BY ProductID,
Version;
|
Новые требования устраняют надобность в некоторых подзапросах. Однако расчетная стоимость запроса для Production.ProductVersion изменяется несущественно.
Это новое изменение требует только маленького изменения реализации ROW_NUMBER(). Вот так в новых условиях выглядит реализация ROW_NUMBER():
WITH RowExample2
AS
(
SELECT ROW_NUMBER() OVER(PARTITION BY ProductID,
Version
ORDER BY ProductID,
Version,
MinorVersion DESC,
ReleaseVersion DESC
) AS MaxVersion,
ProductID,
Version,
MinorVersion,
ReleaseVersion,
StandardCost
FROM Production.ProductVersion pv WITH (NOLOCK)
)
SELECT ProductID,
Version,
MinorVersion,
ReleaseVersion,
StandardCost
FROM RowExample2
WHERE MaxVersion = 1
ORDER BY ProductID;
|
В этом примере номера строк делятся согласно ProductID и Version. Выражение WHERE по-прежнему действительно, поскольку максимальное значение MinorVersion для каждого (ProductID, Version) гарантированно находится в первой строке. Расчетная стоимость запроса для измененного кода меняется несущественно. Читаемость, легкость поддержки и эффективность функции делают ее лучшим выбором, чем подход, основанный на подзапросах
Заключение
Эти примеры показывают критическую роль индексации для подхода, основанного на подзапросах. Реализация ROW_NUMBER() куда проще читается, и поэтому ее легче поддерживать. Она также является относительно независимой от индексации даже при больших объемах данных. Поскольку функция использует возможности SQL Server по сортировке записей, большинство запросов, которые должны поддержать уровень упорядочения, должно по крайней мере учитывать возможность такой реализации. Сама по себе сортировка может существенно уменьшить или вовсе устранить необходимость в логике, нужной для обеспечения целостности данных на уровне строк.
Любой из материалов, опубликованных на этом сервере, не может быть воспроизведен в какой бы
то ни было форме и какими бы то ни было средствами без письменного разрешения владельцев авторских
прав.
Copyright © 1994-2016 ООО "К-Пресс"
