 |
Технология Клиент-Сервер 2010'2
|
|
|
Разбиение на страницы и управление версиями с помощью ROW_NUMBER()
Автор: Лоуренс Мур
Опубликовано: 02.07.2010
Версия текста: 1.1
Введение
Функция ROW_NUMBER() появилась в SQL Server 2005 и предлагает ряд существенных преимуществ в смысле функциональности и производительности. Выгоды ее использования часто недооценивают.
Кроме стандартных задач по нумерации строк и разбиению на страницы (о которых я кратко скажу ниже), выражение PARTITION BY дает возможность выполнять эффективные запросы, фильтрованные по версиям. До появления функции ROW_NUMBER() такие запросы приходилось выполнять с помощью менее интуитивных и менее эффективных коррелированных подзапросов.
В целом, функция ROW_NUMBER() должна быть частью инструментария каждого разработчика, и должна естественно приходить на ум в определенных условиях.
Эту статью я начну с того, что покажу основы работы с функцией ROW_NUMBER() и то, как можно использовать ее для выдачи клиенту результатов "по странице за раз". Затем я перейду к использованию реальной мощи этой функции, используя ее выражение PARTITION BY.
Основы нумерации строк
Функция ROW_NUMBER() в своей простейшей форме позволяет добавить колонку RowNumber к табличному набору результатов. В настольных СУБД типа Access это может показаться тривиальным, но в суровом реляционном мире SQL Server до версии 2005 добавление колонки с последовательными номерами-идентификаторами записей к набору результатов было непростой задачей.
Стоит упомянуть, что эта возможность – вовсе не то же самое, что колонка IDENTITY, хранящаяся в таблице и сохраняемая в момент вставки записи (хотя в нескольких решениях до появления функции ROW_NUMBER() использовался такой подход с использованием временной таблицы).
Функция ROW_NUMBER() вместо этого конструирует колонку на лету в качестве части запроса. Преимущества этого я покажу ниже.
Давайте создадим простую таблицу Books, которую будем использовать в качестве примера:
IF OBJECT_ID('dbo.Books')IS NOT NULL
DROP TABLE dbo.Books
GO
CREATE TABLE dbo.Books
(
BookId BIGINT NOT NULL PRIMARY KEY IDENTITY(1,1),
BookTitle VARCHAR(100) NOT NULL,
BookEdition SMALLINT NOT NULL,
BookPublishDate SMALLDATETIME NOT NULL,
BookAuthor VARCHAR(100) NOT NULL
)
CREATE UNIQUE INDEX uq_BookTitleEdition ON dbo.Books(BookTitle, BookEdition)
INSERT dbo.Books(BookTitle, BookEdition, BookPublishDate, BookAuthor)
VALUES ('Eating Cheese Without Getting Killed', 1, '01 jan 2009', 'M.Mouse')
INSERT dbo.Books(BookTitle, BookEdition, BookPublishDate, BookAuthor)
VALUES ('Eating Cheese Without Getting Killed', 2, '01 jan 2010', 'M.Mouse')
INSERT dbo.Books(BookTitle, BookEdition, BookPublishDate, BookAuthor)
VALUES ('Why I Split With Minnie', 1, '01 feb 2010', 'M.Mouse')
INSERT dbo.Books(BookTitle, BookEdition, BookPublishDate, BookAuthor)
VALUES ('Why Pluto Wrecked My Life', 1, '02 mar 2010', 'M.Mouse')
INSERT dbo.Books(BookTitle, BookEdition, BookPublishDate, BookAuthor)
VALUES ('My Drug Addiction and How I Rebuilt My Life', 1, '01 apr 2010', 'M.Mouse')
INSERT dbo.Books(BookTitle, BookEdition, BookPublishDate, BookAuthor)
VALUES ('1001 Great Carrot Recipes', 1, '01 jan 2009', 'B.Bunny')
INSERT dbo.Books(BookTitle, BookEdition, BookPublishDate, BookAuthor)
VALUES ('1001 Great Carrot Recipes', 2, '01 jan 2010', 'B.Bunny')
INSERT dbo.Books(BookTitle, BookEdition, BookPublishDate, BookAuthor)
VALUES ('Counter Surveillance in Rural Locations', 1, '01 feb 2010', 'B.Bunny')
INSERT dbo.Books(BookTitle, BookEdition, BookPublishDate, BookAuthor)
VALUES ('Counter Surveillance in Rural Locations', 2, '02 mar 2010', 'B.Bunny')
INSERT dbo.Books(BookTitle, BookEdition, BookPublishDate, BookAuthor)
VALUES ('My Celebrity Tips for a Shiny Coat and Fluffy Tail', 1, '01 apr 2010', 'B.Bunny')
INSERT dbo.Books(BookTitle, BookEdition, BookPublishDate, BookAuthor)
VALUES ('Elementary Mathematics, and Numbers Higher Than Infinite', 1,'01 jan 2007', 'B.LightYear')
INSERT dbo.Books(BookTitle, BookEdition, BookPublishDate, BookAuthor)
VALUES ('Elementary Mathematics, and Numbers Higher Than Infinite', 2,'01 jan 2008', 'B.LightYear')
INSERT dbo.Books(BookTitle, BookEdition, BookPublishDate, BookAuthor)
VALUES ('Elementary Mathematics, and Numbers Higher Than Infinite', 3,'01 jan 2009', 'B.LightYear')
INSERT dbo.Books(BookTitle, BookEdition, BookPublishDate, BookAuthor)
VALUES ('How to Spot and Avoid CowBoys', 2, '02 mar 2010', 'B.LightYear')
INSERT dbo.Books(BookTitle, BookEdition, BookPublishDate, BookAuthor)
VALUES ('Exploring The MetaPhysical - Am I Real or Just a Toy?', 1, '01 apr 2010', 'B.LightYear')
|
ПРИМЕЧАНИЕ
Примечание: это упрощенный дизайн таблицы, служащий только для примера. В реальности поле BookAuthor скорее всего будет внешним ключом для другой таблицы.
|
Теперь, когда у нас есть данные, мы можем использовать функцию ROW_NUMBER(), чтобы приказать SQL Server возвратить набор результатов в определенном порядке, добавляя по ходу дела колонку с номерами записей.
Базовый синтаксис функции ROW_NUMBER() требует выражения ORDER BY, определяющего порядок создания значений в колонке с номерами записей.
Рассмотрим, например, все книги, упорядоченные по BookAuthor, BookTitle и BookEdition:
SELECT
ROW_NUMBER()OVER(ORDER BY BookAuthor, BookTitle, BookEdition)AS 'RowNumber',
BookAuthor, BookTitle, BookEdition
FROM dbo.Books
ORDER BY BookAuthor, BookTitle, BookEdition
|
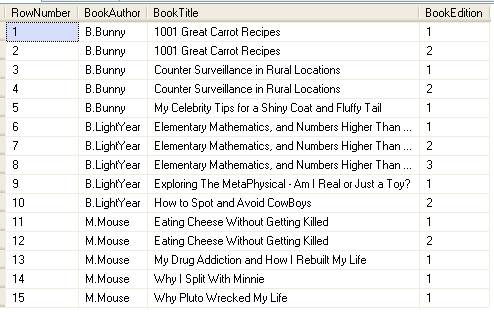
Заметьте, что по вашему желанию оператор ORDER BY для главного выражения SELECT может отличаться от указанного для функции ROW_NUMBER(). В общем, более интуитивно иметь два оператора ORDER BY.
Я не хочу тратить слишком много времени на рассмотрение основ синтаксиса, так как дополнительные возможности функции ROW_NUMBER() по разбиению на страницы куда интереснее. Несложно заметить, что использование этого подхода существенно упрощает встраивание разбиения на страницы в отчеты.
Давайте напишем хранимую процедуру, демонстрирующую это:
IF OBJECT_ID('dbo.usp_ShowBooks') IS NOT NULL DROP PROCEDURE dbo.usp_ShowBooks
GO
CREATE PROCEDURE dbo.usp_ShowBooks
@PageNumber INT,
@PageSize INT
AS
BEGIN
;WITH BookCTE (RowNumber, BookAuthor, BookTitle, BookEdition)
AS
(
SELECT
ROW_NUMBER()OVER (ORDER BY BookAuthor, BookTitle, BookEdition),
BookAuthor, BookTitle, BookEdition
FROM dbo.Books
)
SELECT TOP (@PageSize) BookAuthor, BookTitle, BookEdition
FROM BookCTE WHERE RowNumber>((@PageNumber-1)*@PageSize)
ORDER BY BookAuthor, BookTitle, BookEdition
END
|
Одно из ограничений колонки, созданной функцией ROW_NUMBER(), состоит в том, что ее нельзя использовать напрямую в выражении WHERE. Это достаточно просто обойти. Так, здесь мы используем CTE (Common Table Expression) в качестве удобного способа ссылаться на колонку RowNumber в последующих выражениях WHERE. Можно было создать для этого промежуточную временную таблицу, но CTE лучше, так как они являются четкими и самодостаточными.
Теперь мы можем использовать эту хранимую процедуру, чтобы передавать наборы записей клиентским приложениям, которые будут выводить страницы с данными. Например, предполагая, что клиентское приложение ожидает 5 записей за раз:
EXEC dbo.usp_ShowBooks @PageNumber=1, @PageSize=5
EXEC dbo.usp_ShowBooks @PageNumber=2, @PageSize=5
EXEC dbo.usp_ShowBooks @PageNumber=3, @PageSize=5
|
Еще о нумерации записей и разбиении на страницы
Возможности разбиения на страницы функции ROW_NUMBER() действительно позволяют хвастаться ее возможностями. Это выражение определяет "разбиение", которое говорит, когда значения номеров строк будут сброшены и снова начнутся с 1.
Например, предположим, что мы хотим показать все книги по авторам, пронумеровав книги в порядке дат их создания:
SELECT
ROW_NUMBER()OVER(PARTITION BY BookAuthor ORDER BY BookPublishDate) AS ' RowNumber',
BookAuthor, BookPublishDate, BookTitle, BookEdition
FROM dbo.Books
ORDER BY BookAuthor, BookPublishDate
|
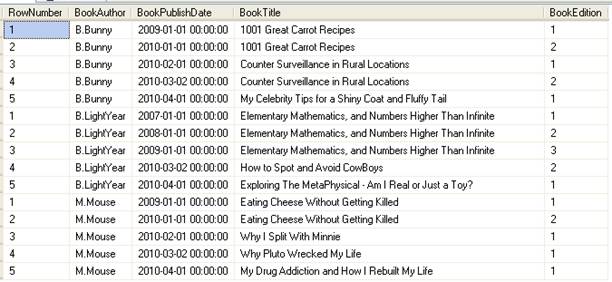
При "разбиении" по BookAuthor, значения RowNumber сбрасываются в 1 при каждом изменении Author. Выражение ORDER BY функции RowNumber() обеспечивает, что первая книга каждого автора получит RowNumber 1.
Это был гипотетический пример, показывающий синтаксис и результат выполнения.
Перейдем к более полезному примеру – найдем самое позднее издание каждой из книг:
;WITHBookCTE (RowNumber, BookTitle, BookEdition, BookPublishDate, BookAuthor)
AS
(
SELECT
ROW_NUMBER()OVER (PARTITION BY BookTitle ORDER BY BookEdition DESC),
BookTitle, BookEdition, BookPublishDate, BookAuthor
FROM dbo.Books
)
SELECT BookTitle, BookEdition, BookPublishDate, BookAuthor
FROM BookCTE
WHERE RowNumber=1
ORDER BY BookTitle
|
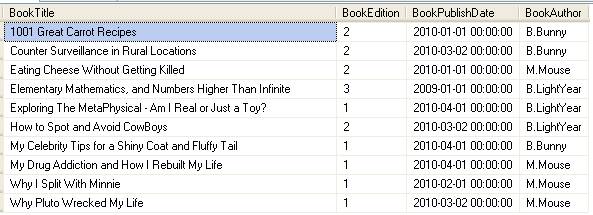
На этот раз мы разбиваем результат по BookTitle, и упорядочиваем по BookEdition DESCENDING, так что последнее издание всегда возвращается с RowNumber=1.
Затем мы оборачиваем все в CTE, как раньше, и фильтруем по WHERE RowNumber=1.
Логически это просто понять, и это более эффективно, чем вариант на коррелированных подзапросах. Вот результат SET STATISTICS IO для приведенного выше запроса:
Table 'Books'. Scan count 1, logical reads 2, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
|
Вот эквивалентное решение на коррелированных подзапросах без использования ROW_NUMBER():
SELECT BookTitle, BookEdition, BookPublishDate, BookAuthor
FROM dbo.Books b
WHERE BookEdition=(SELECT MAX(BookEdition)FROM dbo.Books WHERE BookTitle=b.BookTitle)
Table 'Books'. Scan count 1, logical reads 42, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
|
2 логических чтения против 42. И это для таблицы всего из 15 строк!
Прежде чем перейти к примерам из реального мира, использующим функцию ROW_NUMBER(), давайте вернемся к последней книге каждого автора, поскльку это очень просто:
;WITH BookCTE (RowNumber, BookTitle, BookEdition, BookPublishDate, BookAuthor)
AS
(
SELECT
ROW_NUMBER()OVER (PARTITION BY BookAuthor ORDER BY BookPublishDate DESC),
BookTitle, BookEdition, BookPublishDate, BookAuthor
FROM dbo.Books
)
SELECT BookTitle, BookEdition, BookPublishDate, BookAuthor
FROM BookCTE
WHERE RowNumber=1
ORDER BY BookTitle
|

Примеры из реального мира
Сделки
Допустим, у нас есть таблица dbo.Deal, которая содержит финансовые атрибуты сделок. Первичный ключ - DealID, а логический (естественный) идентификатор каждой сделки DealCode. Каждому DealCode соответствуют несколько записей, идентифицируемых по колонке DealVersion, добавленной, поскольку атрибуты сделки могут меняться со временем. Кроме того, могут существовать множественные DealCode с разными SourceID, идентифицирующими исходную систему, где была создана сделка.
Небольшой кусок таблицы Deal выглядит примерно так:
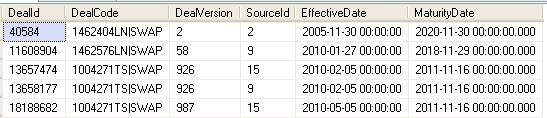
Сейчас в таблице Deal более 13 миллионов записей, так что при запросах к ней нужно обеспечивать максимальную эффективность (впрочем, как всегда).
У нас есть также предварительно созданная временная таблица (#PNLData), которая содержит оценочные данные, включающие DealCode и SourceId. Теперь мы хотим "отыскать" последние версии этих сделок, чтобы возвратить самые поздние информационные атрибуты сделок для наших оценочных данных:
;WITH PNLWithDealInfo(RowNumber, DealCode, DealVersion, SourceId, EffectiveDate, MaturityDate, LocalValue, LocalCurrencyCode)
AS
(
SELECT ROW_NUMBER() OVER(PARTITION BY d.DealCode, d.SourceId ORDER BY d.DealVersion DESC),
d.DealCode, d.DealVersion, d.SourceId, d.EffectiveDate, d.MaturityDate,
t.LocalValue, t.LocalCurrencyCode
FROM dbo.Deal d INNER JOIN #PNLData t ON d.DealCode=t.DealCode AND d.SourceId=t.SourceId
)
SELECT DealCode, DealVersion, SourceId, EffectiveDate, MaturityDate, LocalValue, LocalCurrencyCode
FROM PNLWithDealInfo
WHERE RowNumber=1
|
(результаты сокращены)
Хеджи
Для примера этого знать не нужно, но, для общего кругозора, Хедж – это набор активов и рисков с аналогичными, но смещенными характеристиками. Они используются, среди прочего, для смещения рыночных рисков и получения бухгалтерских преимуществ.
Допустим, у нас есть таблица состояния хеджей (dbo.hfv_hedge_rel_state), которая хранит историческую информацию о хеджах за каждый отчетный месяц.
Каждый запись о хедже (помеченная hfv_hedge_rel_id) либо продолжается со статусом “Active” в следующем месяце, либо закрывается как “Dedesignated”, и никаких вхождений в нее больше не добавляется.
Например, для хеджа 5815 существуют следующие записи:
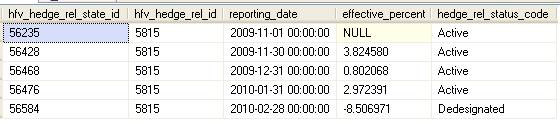
Используя функцию ROW_NUMBER() и CTE, использованное выше, можно создать следующее полезное представление, чтобы получить последнюю информацию о статусе каждого хеджа:
CREATE VIEW dbo.v_hfv_latest_hedge_status
AS
WITH LatestHedgeStatus (
RowNumber, hfv_hedge_rel_state_id,
hfv_hedge_rel_id, reporting_date,
effective_percent, hedge_rel_status_code
)
AS (SELECT ROW_NUMBER() OVER(PARTITION BY hfv_hedge_rel_id ORDER BY reporting_date DESC),
hfv_hedge_rel_state_id, hfv_hedge_rel_id, reporting_date,
effective_percent, hedge_rel_status_code
FROM dbo.hfv_hedge_rel_state
)
SELECT hfv_hedge_rel_state_id, hfv_hedge_rel_id, reporting_date,
effective_percent, hedge_rel_status_code
FROM LatestHedgeStatus
WHERE RowNumber=1
GO
|
Теперь мы просто используем представление в ранее приводившемся запросе:
SELECT hfv_hedge_rel_id, reporting_date, effective_percent, hedge_rel_status_code
FROM dbo.v_hfv_latest_hedge_status
WHERE hfv_hedge_rel_id=5815
|

Заключение
Функция ROW_NUMBER() предлагает интуитивный и эффективный метод получения поднаборов версионных данных, "разбитых" по нашему требованию. Решения, использующие ROW_NUMBER(), проще читать, интуитивнее писать, причем они более эффективны чем их эквиваленты, использующие коррелированные подзапросы.
Если вам придется писать коррелированный подзапрос, использующий MAX или MIN, лучше сперва рассмотреть использование ROW_NUMBER().
Любой из материалов, опубликованных на этом сервере, не может быть воспроизведен в какой бы
то ни было форме и какими бы то ни было средствами без письменного разрешения владельцев авторских
прав.
Copyright © 1994-2016 ООО "К-Пресс"
