 |
–Ę–Ķ—Ö–Ĺ–ĺ–Ľ–ĺ–≥–ł—Ź –ö–Ľ–ł–Ķ–Ĺ—ā-–°–Ķ—Ä–≤–Ķ—Ä 2010'4
|
|
|
–§–į–ļ—ā–ĺ—Ä –∑–į–Ņ–ĺ–Ľ–Ĺ–Ķ–Ĺ–ł—Ź (Fill Factor)
–ě–Ņ—É–Ī–Ľ–ł–ļ–ĺ–≤–į–Ĺ–ĺ: 28.12.2010
–í–Ķ—Ä—Ā–ł—Ź —ā–Ķ–ļ—Ā—ā–į: 1.1
–í —ć—ā–ĺ–Ļ —Ā—ā–į—ā—Ć–Ķ —Ź —Ā–ĺ–Ī–ł—Ä–į—é—Ā—Ć —Ä–į—Ā—Ā–ļ–į–∑–į—ā—Ć –ĺ —Ą–į–ļ—ā–ĺ—Ä–Ķ –∑–į–Ņ–ĺ–Ľ–Ĺ–Ķ–Ĺ–ł—Ź (FILLFACTOR, FF, http://msdn.microsoft.com/en-us/library/ms191005.aspx), –≤–ĺ–∑–ľ–ĺ–∂–Ĺ–ĺ—Ā—ā–ł, –ļ–ĺ—ā–ĺ—Ä–ĺ–Ļ —á–į—Ā—ā–ĺ –Ĺ–Ķ –Ņ—Ä–ł–ī–į—é—ā –∑–Ĺ–į—á–Ķ–Ĺ–ł—Ź –ł –ĺ—Ā—ā–į–≤–Ľ—Ź—é—ā –Ķ–Ķ —Ā —É—Ā—ā–į–Ĺ–ĺ–≤–ļ–į–ľ–ł –Ņ–ĺ —É–ľ–ĺ–Ľ—á–į–Ĺ–ł—é.
Fill Factor —É–ļ–į–∑—č–≤–į–Ķ—ā, —Ā–ļ–ĺ–Ľ—Ć–ļ–ĺ –Ľ–ł—Ā—ā–ĺ–≤—č—Ö —Ā—ā—Ä–į–Ĺ–ł—Ü (leaf pages) –ł–Ĺ–ī–Ķ–ļ—Ā–į –∑–į–Ņ–ĺ–Ľ–Ĺ—Ź–Ķ—ā—Ā—Ź, –į Pad Index (http://msdn.microsoft.com/en-us/library/ms186872.aspx) —É–ļ–į–∑—č–≤–į–Ķ—ā, –ī–ĺ–Ľ–∂–Ĺ—č –Ľ–ł —Ā—ā—Ä–į–Ĺ–ł—Ü—č Intermediate Index –ł—Ā–Ņ–ĺ–Ľ—Ć–∑–ĺ–≤–į—ā—Ć —ā–ĺ—ā –∂–Ķ —Ą–į–ļ—ā–ĺ—Ä –∑–į–Ņ–ĺ–Ľ–Ĺ–Ķ–Ĺ–ł—Ź, —á—ā–ĺ —É–ļ–į–∑–į–Ĺ –ī–Ľ—Ź –ł–Ĺ–ī–Ķ–ļ—Ā–į. –ü–ĺ —É–ľ–ĺ–Ľ—á–į–Ĺ–ł—é —Ą–į–ļ—ā–ĺ—Ä –∑–į–Ņ–ĺ–Ľ–Ĺ–Ķ–Ĺ–ł—Ź –ł–Ĺ–ī–Ķ–ļ—Ā–į –Ī–Ķ—Ä–Ķ—ā—Ā—Ź –ł–∑ –Ĺ–į—Ā—ā—Ä–ĺ–Ķ–ļ —ć–ļ–∑–Ķ–ľ–Ņ–Ľ—Ź—Ä–į –Ď–Ē, –ļ–į–ļ –Ņ–ĺ–ļ–į–∑–į–Ĺ–ĺ –Ĺ–ł–∂–Ķ. –ó–Ĺ–į—á–Ķ–Ĺ–ł–Ķ –Ņ–ĺ —É–ľ–ĺ–Ľ—á–į–Ĺ–ł—é —Ä–į–≤–Ĺ–ĺ 0, —á—ā–ĺ –∑–Ĺ–į—á–ł—ā, —á—ā–ĺ –ī–≤–ł–∂–ĺ–ļ SQL Server –Ī—É–ī–Ķ—ā –Ņ–ĺ–Ľ–Ĺ–ĺ—Ā—ā—Ć—é –∑–į–Ņ–ĺ–Ľ–Ĺ—Ź—ā—Ć –≤—Ā–Ķ —Ā—ā—Ä–į–Ĺ–ł—Ü—č –ł–Ĺ–ī–Ķ–ļ—Ā–į –ī–į–Ĺ–Ĺ—č–ľ–ł, —ā–ĺ –Ķ—Ā—ā—Ć —ā–ĺ –∂–Ķ, —á—ā–ĺ –ł 100%. –Ě–į —Ä–ł—Ā—É–Ĺ–ļ–Ķ 1 –Ņ–ĺ–ļ–į–∑–į–Ĺ–ĺ, –ļ–į–ļ –ł–∑–ľ–Ķ–Ĺ–ł—ā—Ć –Ĺ–į—Ā—ā—Ä–ĺ–Ļ–ļ–ł –Ņ–ĺ —É–ľ–ĺ–Ľ—á–į–Ĺ–ł—é.
–†–ł—Ā—É–Ĺ–ĺ–ļ 1.
–ü–ĺ–ł—Ā–ļ –ł –∑–į–ī–į–Ĺ–ł–Ķ –ł–ī–Ķ–į–Ľ—Ć–Ĺ–ĺ–≥–ĺ FF –ī–Ľ—Ź –Ď–Ē ‚Äď –Ĺ–Ķ —Ā–į–ľ–ĺ–Ķ –Ņ—Ä–ĺ—Ā—ā–ĺ–Ķ –ī–Ķ–Ľ–ĺ. –≠—ā–ĺ –Ĺ–Ķ —ā–ĺ—ā —Ā–Ľ—É—á–į–Ļ, –ļ–ĺ–≥–ī–į –ī–ĺ—Ā—ā–į—ā–ĺ—á–Ĺ–ĺ –∑–į–ī–į—ā—Ć –Ĺ–Ķ–ļ–ł–Ķ –ľ–į–≥–ł—á–Ķ—Ā–ļ–ł–Ķ —á–ł—Ā–Ľ–į, —á—ā–ĺ–Ī—č –Ď–Ē —Ä–į–Ī–ĺ—ā–į–Ľ–į –≤—Ā–Ķ–≥–ī–į –ł –≤–ĺ –≤—Ā–Ķ—Ö —Ā—Ü–Ķ–Ĺ–į—Ä–ł—Ź—Ö. –Ě—É–∂–Ĺ–ĺ –Ņ–ĺ—Ä–į–∑–ľ—č—Ā–Ľ–ł—ā—Ć –ł –Ņ—Ä–ĺ–≤–Ķ—Ā—ā–ł —ā–Ķ—Ā—ā—č, —á—ā–ĺ–Ī—č —É–Ī–Ķ–ī–ł—ā—Ć—Ā—Ź, —á—ā–ĺ –≤—č–Ī—Ä–į–Ĺ–Ĺ—č–Ķ –∑–Ĺ–į—á–Ķ–Ĺ–ł—Ź —É–ī–ĺ–≤–Ľ–Ķ—ā–≤–ĺ—Ä–ł—ā–Ķ–Ľ—Ć–Ĺ–ĺ —Ä–į–Ī–ĺ—ā–į—é—ā. –ü—Ä–ł –≤—č—Ā–ĺ–ļ–ĺ–ľ FF –Ī–ĺ–Ľ—Ć—ą–Ķ —Ā—ā—Ä–ĺ–ļ —É–Ņ–į–ļ–ĺ–≤—č–≤–į–Ķ—ā—Ā—Ź –≤ –ĺ–ī–Ĺ—É —Ā—ā—Ä–į–Ĺ–ł—Ü—É –ī–į–Ĺ–Ĺ—č—Ö, –Ĺ–ĺ –Ķ—Ā—ā—Ć –Ī–ĺ–Ľ—Ć—ą–ł–Ķ —ą–į–Ĺ—Ā—č, —á—ā–ĺ —Ä–į–∑–Ī–ł–Ķ–Ĺ–ł–Ļ —Ā—ā—Ä–į–Ĺ–ł—Ü —Ā—ā–į–Ĺ–Ķ—ā –Ī–ĺ–Ľ—Ć—ą–Ķ, –ĺ—Ā–ĺ–Ī–Ķ–Ĺ–Ĺ–ĺ –≤ —ā—Ä–į–Ĺ–∑–į–ļ—Ü–ł–ĺ–Ĺ–Ĺ—č—Ö —Ā–ł—Ā—ā–Ķ–ľ–į—Ö. –≠—ā–ĺ –Ĺ–Ķ–∂–Ķ–Ľ–į—ā–Ķ–Ľ—Ć–Ĺ–ĺ, –Ņ–ĺ—Ā–ļ–ĺ–Ľ—Ć–ļ—É —á–Ķ–ľ –ľ–Ķ–Ĺ—Ć—ą–Ķ —Ä–į–∑–Ī–ł–Ķ–Ĺ–ł–Ļ —Ā—ā—Ä–į–Ĺ–ł—Ü, —ā–Ķ–ľ –Ľ—É—á—ą–Ķ –ī–Ľ—Ź –Ņ—Ä–ĺ–ł–∑–≤–ĺ–ī–ł—ā–Ķ–Ľ—Ć–Ĺ–ĺ—Ā—ā–ł. –° –ī—Ä—É–≥–ĺ–Ļ —Ā—ā–ĺ—Ä–ĺ–Ĺ—č, –Ņ—Ä–ł –Ĺ–ł–∑–ļ–ĺ–ľ FF –Ĺ–į —Ā—ā—Ä–į–Ĺ–ł—Ü–Ķ –ī–į–Ĺ–Ĺ—č—Ö –Ī—É–ī–Ķ—ā –ľ–Ķ–Ĺ—Ć—ą–Ķ –∑–į–Ņ–ł—Ā–Ķ–Ļ, —á—ā–ĺ —Ā–Ĺ–ł–∑–ł—ā —á–ł—Ā–Ľ–ĺ —Ä–į–∑–Ī–ł–Ķ–Ĺ–ł–Ļ —Ā—ā—Ä–į–Ĺ–ł—Ü, –Ĺ–ĺ –Ņ–ĺ—ā—Ä–Ķ–Ī—É–Ķ—ā –Ī–ĺ–Ľ—Ć—ą–Ķ —ā–į–ļ–ł—Ö —Ä–Ķ—Ā—É—Ä—Ā–ĺ–≤, –ļ–į–ļ I/O, –ī–Ľ—Ź —á—ā–Ķ–Ĺ–ł—Ź —ā–ĺ–≥–ĺ –∂–Ķ –ĺ–Ī—ä–Ķ–ľ–į –ī–į–Ĺ–Ĺ—č—Ö, —ā–į–ļ –ļ–į–ļ –ī–į–Ĺ–Ĺ—č–Ķ –Ī—É–ī—É—ā —Ä–į—Ā–Ņ—Ä–Ķ–ī–Ķ–Ľ–Ķ–Ĺ—č –Ņ–ĺ –Ī–ĺ–Ľ—Ć—ą–Ķ–ľ—É —á–ł—Ā–Ľ—É —Ā—ā—Ä–į–Ĺ–ł—Ü.
–ö—Ä–ĺ–ľ–Ķ –Ĺ–į—Ā—ā—Ä–ĺ–Ļ–ļ–ł FF –ī–Ľ—Ź —Ü–Ķ–Ľ–ĺ–Ļ –Ď–Ē, –ľ–ĺ–∂–Ĺ–ĺ –Ĺ–į—Ā—ā—Ä–ĺ–ł—ā—Ć FF –ī–Ľ—Ź –ļ–į–∂–ī–ĺ–≥–ĺ –ł–Ĺ–ī–Ķ–ļ—Ā–į –ł–Ĺ–ī–ł–≤–ł–ī—É–į–Ľ—Ć–Ĺ–ĺ. –≠—ā–ĺ –ī–Ķ–Ľ–į–Ķ—ā—Ā—Ź –Ņ—Ä–ł –ĺ–ī–Ĺ–ĺ–Ļ –ł–∑ —Ā–Ľ–Ķ–ī—É—é—Č–ł—Ö –ĺ–Ņ–Ķ—Ä–į—Ü–ł–Ļ:
- –Ņ—Ä–ł –Ņ–Ķ—Ä–Ķ—Ā—ā—Ä–ĺ–Ļ–ļ–Ķ –ł–Ĺ–ī–Ķ–ļ—Ā–į;
- –Ņ—Ä–ł —Ä–Ķ–ĺ—Ä–≥–į–Ĺ–ł–∑–į—Ü–ł–ł –ł–Ĺ–ī–Ķ–ļ—Ā–į;
- –Ņ—Ä–ł —Ā–ĺ–∑–ī–į–Ĺ–ł–ł –ł–Ĺ–ī–Ķ–ļ—Ā–į.
Fill Factor –ī–Ľ—Ź –ł–Ĺ–ī–Ķ–ļ—Ā–į –≤—č—á–ł—Ā–Ľ—Ź–Ķ—ā—Ā—Ź –ł –Ņ—Ä–ł–ľ–Ķ–Ĺ—Ź–Ķ—ā—Ā—Ź —ā–ĺ–Ľ—Ć–ļ–ĺ –≤ –Ņ–Ķ—Ä–Ķ—á–ł—Ā–Ľ–Ķ–Ĺ–Ĺ—č—Ö –≤—č—ą–Ķ –ĺ–Ņ–Ķ—Ä–į—Ü–ł—Ź—Ö. –ü—Ä–ł –ĺ–Ī—č—á–Ĺ—č—Ö –ĺ–Ņ–Ķ—Ä–į—Ü–ł—Ź—Ö, —ā.–Ķ. DML-–≤—č—Ä–į–∂–Ķ–Ĺ–ł—Ź—Ö, –Ĺ–į—Ā—ā—Ä–ĺ–Ļ–ļ–ł FF –ł–≥–Ĺ–ĺ—Ä–ł—Ä—É—é—ā—Ā—Ź, –ł –ī–≤–ł–∂–ĺ–ļ –Ī—É–ī–Ķ—ā –Ņ—č—ā–į—ā—Ć—Ā—Ź –∑–į–Ņ–ĺ–Ľ–Ĺ–ł—ā—Ć —Ā—ā—Ä–į–Ĺ–ł—Ü—č –ł–Ĺ–ī–Ķ–ļ—Ā–į –Ĺ–į—Ā—ā–ĺ–Ľ—Ć–ļ–ĺ –Ņ–ĺ–Ľ–Ĺ–ĺ, –Ĺ–į—Ā–ļ–ĺ–Ľ—Ć–ļ–ĺ —Ā–ľ–ĺ–∂–Ķ—ā. –ö–ĺ–≥–ī–į –≤ –ļ–ĺ–Ĺ—Ü–Ķ –ļ–ĺ–Ĺ—Ü–ĺ–≤ –Ņ—Ä–ĺ–ł—Ā—Ö–ĺ–ī–ł—ā —Ä–į–∑–Ī–ł–Ķ–Ĺ–ł–Ķ —Ā—ā—Ä–į–Ĺ–ł—Ü—č, –ī–≤–ł–∂–ĺ–ļ –≤ –ĺ–Ī—Č–Ķv —Ā–Ľ—É—á–į–Ķ –Ņ–Ķ—Ä–Ķ–ľ–Ķ—Ā—ā–ł—ā –Ņ–ĺ–Ľ–ĺ–≤–ł–Ĺ—É –ł—Ā—Ö–ĺ–ī–Ĺ–ĺ–Ļ —Ā—ā—Ä–į–Ĺ–ł—Ü—č –Ĺ–į –Ĺ–ĺ–≤—É—é —Ā—ā—Ä–į–Ĺ–ł—Ü—É, –Ĺ–Ķ–∑–į–≤–ł—Ā–ł–ľ–ĺ –ĺ—ā –Ĺ–į—Ā—ā—Ä–ĺ–Ķ–ļ FF. –ü–ĺ–ī—Ä–ĺ–Ī–Ĺ–Ķ–Ķ –ĺ–Ī —ć—ā–ĺ–ľ –ľ–ĺ–∂–Ĺ–ĺ –Ņ—Ä–ĺ—á–ł—ā–į—ā—Ć –Ņ–ĺ –į–ī—Ä–Ķ—Ā—É http://msdn.microsoft.com/en-us/library/ms177459.aspx.
–Ę–Ķ—Ā—ā–ĺ–≤—č–Ķ —Ā—Ü–Ķ–Ĺ–į—Ä–ł–ł
–í –Ņ—Ä–ł–Ľ–į–≥–į–Ķ–ľ–ĺ–ľ —Ā–ļ—Ä–ł–Ņ—ā–Ķ —Ź —Ā–ĺ–∑–ī–į—é –ī–≤–Ķ –ĺ–ī–Ĺ–ĺ—Ā—ā–ĺ–Ľ–Ī—Ü–ĺ–≤—č—Ö —ā–į–Ī–Ľ–ł—Ü—č, _TEST1 –ł _TEST2, —Ā–ĺ–ĺ—ā–≤–Ķ—ā—Ā—ā–≤–Ķ–Ĺ–Ĺ–ĺ.
–Ē–Ľ—Ź —ā–į–Ī–Ľ–ł—Ü—č _TEST1 —Ā–ĺ–∑–ī–į–Ķ—ā—Ā—Ź –ł–Ĺ–ī–Ķ–ļ—Ā INDEX1 –Ņ–ĺ —Ā—ā–ĺ–Ľ–Ī—Ü—É col_1 —Ā–ĺ 100% —Ą–į–ļ—ā–ĺ—Ä–ĺ–ľ –∑–į–Ņ–ĺ–Ľ–Ĺ–Ķ–Ĺ–ł—Ź.
–Ē–Ľ—Ź —ā–į–Ī–Ľ–ł—Ü—č _TEST2 —Ā–ĺ–∑–ī–į–Ķ—ā—Ā—Ź –ł–Ĺ–ī–Ķ–ļ—Ā INDEX2 –Ņ–ĺ —Ā—ā–ĺ–Ľ–Ī—Ü—É col_2 —Ā 50% —Ą–į–ļ—ā–ĺ—Ä–ĺ–ľ –∑–į–Ņ–ĺ–Ľ–Ĺ–Ķ–Ĺ–ł—Ź.
–ě–Ī–Ķ —ā–į–Ī–Ľ–ł—Ü—č —Ā–ĺ–ī–Ķ—Ä–∂–į—ā –Ņ–ĺ 8 –∑–į–Ņ–ł—Ā–Ķ–Ļ.
|
–Ę–į–Ī–Ľ–ł—Ü—č _TEST
|
|
–Ě–į–∑–≤–į–Ĺ–ł–Ķ —ā–į–Ī–Ľ–ł—Ü—č
|
–Ě–į–∑–≤–į–Ĺ–ł–Ķ
–ł–Ĺ–ī–Ķ–ļ—Ā–į
|
–Ě–į–∑–≤–į–Ĺ–ł–Ķ —Ā—ā–ĺ–Ľ–Ī—Ü–į
|
–§–į–ļ—ā–ĺ—Ä
–∑–į–Ņ–ĺ–Ľ–Ĺ–Ķ–Ĺ–ł—Ź
|
|
_TEST1
|
INDEX1 (CLUSTERED)
|
Col_1 char(900)
|
100%
|
|
_TEST2
|
INDEX2 (CLUSTERED)
|
Col_2 char(900)
|
50%
|
USE tempdb
GO
CREATE TABLE [dbo].[_TEST1](
[Col_1] [char](900) NULL
) ON [PRIMARY]
GO
CREATE TABLE [dbo].[_TEST2](
[Col_2] [char](900) NULL
) ON [PRIMARY]
GO
Delete _TEST1;
Delete _TEST2;
Declare @Counter Int;
set @Counter = 1;
While @Counter <= 8
Begin
INSERT INTO _TEST1 (Col_1)
Values ('Test Data - Column 1');
INSERT INTO _TEST2 (Col_2)
Values ('Test Data - Column 2');
Set @Counter = @Counter + 1;
End
IF EXISTS (SELECT * FROM sys.indexes WHERE object_id = OBJECT_ID(N'[dbo].[_TEST1]') AND name = N'INDEX1')
DROP INDEX [INDEX1] ON [dbo].[_TEST1]
GO
CREATE CLUSTERED INDEX [INDEX1] ON [dbo].[_TEST1] ([Col_1] ASC)
GO
IF EXISTS (SELECT * FROM sys.indexes WHERE object_id = OBJECT_ID(N'[dbo].[_TEST2]') AND name = N'INDEX2')
DROP INDEX [INDEX2] ON [dbo].[_TEST2]
GO
CREATE CLUSTERED INDEX [INDEX2] ON [dbo].[_TEST2]
([Col_2] ASC) WITH (FILLFACTOR = 50, PAD_INDEX = ON)
GO
|
–ė—Ā–Ņ–ĺ–Ľ–Ĺ—Ź—Ź –Ņ—Ä–ł–≤–Ķ–ī–Ķ–Ĺ–Ĺ—č–Ļ –Ĺ–ł–∂–Ķ —Ā–ļ—Ä–ł–Ņ—ā, –Ľ–Ķ–≥–ļ–ĺ –Ņ—Ä–ĺ–≤–Ķ—Ä–ł—ā—Ć —Ä–į—Ā–Ņ—Ä–Ķ–ī–Ķ–Ľ–Ķ–Ĺ–ł–Ķ –ī–į–Ĺ–Ĺ—č—Ö.
USE tempdb
GO
SELECT CAST(OBJECT_NAME(S.object_id, DB_ID('tempdb'))
AS VARCHAR(20))
AS 'Table Name',
  I.name AS IndexName,
  CAST(index_type_desc AS VARCHAR(20))
AS 'Index Type',
  CASE WHEN I.fill_factor in (0,100) THEN
  100
  ELSE
  I.fill_factor
  END AS fill_factor,
  CASE WHEN I.is_padded = 1 THEN
  'On'
  ELSE
  'Off'
  END As 'Pad Index',
  avg_fragmentation_in_percent AS 'Avg % Fragmentation',
  record_count AS 'RecordCount',
  page_count AS 'Pages Allocated',
  avg_page_space_used_in_percent AS 'Avg % Page Space Used',
  avg_record_size_in_bytes,
  Case When Index_level = 0 Then
  'Leaf'
  Else
  'Intermediate'
  End As 'Index Level'
FROM sys.dm_db_index_physical_stats (
DB_ID('tempdb'),
OBJECT_ID('_TEST'),
NULL,NULL,'DETAILED' ) S
INNER JOIN sys.indexes I On (
I.object_id = S.object_id
AND I.index_id = S.index_id)
|
–†–Ķ–∑—É–Ľ—Ć—ā–į—ā –Ņ–ĺ–ļ–į–∑–į–Ĺ –Ĺ–į —Ä–ł—Ā—É–Ĺ–ļ–Ķ 2.

–†–ł—Ā—É–Ĺ–ĺ–ļ 2.
–†–ł—Ā—É–Ĺ–ĺ–ļ 3.

–†–ł—Ā—É–Ĺ–ĺ–ļ 4.
Table: _TEST1. INDEX1
–Ē–Ľ—Ź —ć—ā–ĺ–Ļ —ā–į–Ī–Ľ–ł—Ü—č –Ī—č–Ľ —É–ļ–į–∑–į–Ĺ FF, —Ä–į–≤–Ĺ—č–Ļ 100%, –ł –ł–∑-–∑–į —ć—ā–ĺ–≥–ĺ –ī–≤–ł–∂–ĺ–ļ –∑–į–Ņ–ĺ–Ľ–Ĺ–ł–Ľ –≤—Ā—é —Ā—ā—Ä–į–Ĺ–ł—Ü—É –ī–į–Ĺ–Ĺ—č—Ö (8060 –Ī–į–Ļ—ā). 8 –∑–į–Ņ–ł—Ā–Ķ–Ļ, –ł–ľ–Ķ—é—Č–ł—Ö—Ā—Ź –≤ —ā–į–Ī–Ľ–ł—Ü–Ķ, —É–ľ–Ķ—Č–į—é—ā—Ā—Ź –Ĺ–į –ĺ–ī–Ĺ–ĺ–Ļ –Ľ–ł—Ā—ā–ĺ–≤–ĺ–Ļ —Ā—ā—Ä–į–Ĺ–ł—Ü–Ķ (–ļ–į–ļ –Ņ–ĺ–ļ–į–∑–į–Ĺ–ĺ –≤—č—ą–Ķ). –ē—Ā–Ľ–ł –Ņ—Ä–ĺ–≤–Ķ—Ā—ā–ł –Ĺ–Ķ–ļ–ĺ—ā–ĺ—Ä—č–Ķ –≤—č—á–ł—Ā–Ľ–Ķ–Ĺ–ł—Ź:
–°—Ä–Ķ–ī–Ĺ–ł–Ļ —Ä–į–∑–ľ–Ķ—Ä –∑–į–Ņ–ł—Ā–ł = 914bytes
–†–į–∑–ľ–Ķ—Ä 1 —Ā—ā—Ä–į–Ĺ–ł—Ü—č ‚Äď 8060 –Ī–į–Ļ—ā.
–ó–į–Ņ–ł—Ā–ł, –ļ–ĺ—ā–ĺ—Ä—č–Ķ —É–ľ–Ķ—Ā—ā—Ź—ā—Ā—Ź –Ĺ–į —Ā—ā—Ä–į–Ĺ–ł—Ü–Ķ = 8060/914 = 8.818, —ā–ĺ –Ķ—Ā—ā—Ć –ĺ–ļ—Ä—É–≥–Ľ–Ķ–Ĺ–Ĺ–ĺ 8 –∑–į–Ņ–ł—Ā–Ķ–Ļ, —ā–į–ļ –ļ–į–ļ –∑–į–Ņ–ł—Ā—Ć –Ĺ–Ķ –ľ–ĺ–∂–Ķ—ā –Ī—č—ā—Ć —Ä–į–∑–ī–Ķ–Ľ–Ķ–Ĺ–į –ľ–Ķ–∂–ī—É –Ĺ–Ķ—Ā–ļ–ĺ–Ľ—Ć–ļ–ł–ľ–ł —Ā—ā—Ä–į–Ĺ–ł—Ü–į–ľ–ł.
–ė—Ā–Ņ–ĺ–Ľ—Ć–∑–ĺ–≤–į–Ĺ–ĺ 90.511% —Ā—ā—Ä–į–Ĺ–ł—Ü—č. –Ē–≤–ł–∂–ĺ–ļ –Ņ—č—ā–į–Ľ—Ā—Ź –ł—Ā–Ņ–ĺ–Ľ—Ć–∑–ĺ–≤–į—ā—Ć –≤—Ā—é —Ā—ā—Ä–į–Ĺ–ł—Ü—É —Ü–Ķ–Ľ–ł–ļ–ĺ–ľ (FF = 100%). –ě–ī–Ĺ–į–ļ–ĺ –ĺ—Ā—ā–į–≤—ą–ł–Ķ—Ā—Ź 10% –Ĺ–Ķ–≤–ĺ–∑–ľ–ĺ–∂–Ĺ–ĺ –ł—Ā–Ņ–ĺ–Ľ—Ć–∑–ĺ–≤–į—ā—Ć, –Ņ–ĺ—Ā–ļ–ĺ–Ľ—Ć–ļ—É –Ķ—Č–Ķ –ĺ–ī–Ĺ–į –∑–į–Ņ–ł—Ā—Ć –Ĺ–Ķ —É–ľ–Ķ—Ā—ā–ł—ā—Ā—Ź –Ĺ–į –ĺ—Ā—ā–į–≤—ą–Ķ–ľ—Ā—Ź –ľ–Ķ—Ā—ā–Ķ, –ļ–ĺ—ā–ĺ—Ä–ĺ–Ķ —Ā–ĺ—Ā—ā–į–≤–Ľ—Ź–Ķ—ā (8060 - (8 x 914)) = 748 –Ī–į–Ļ—ā!
Table: _TEST2. INDEX2
–Ē–Ľ—Ź —ć—ā–ĺ–Ļ —ā–į–Ī–Ľ–ł—Ü—č –Ī—č–Ľ —É–ļ–į–∑–į–Ĺ FF –≤ 50%, –ł –ī–≤–ł–∂–ĺ–ļ –∑–į–Ņ–ĺ–Ľ–Ĺ–ł–Ľ —Ā—ā—Ä–į–Ĺ–ł—Ü—č –ī–į–Ĺ–Ĺ—č—Ö –Ĺ–į–Ņ–ĺ–Ľ–ĺ–≤–ł–Ĺ—É (–Ĺ–į –ļ–į–∂–ī–ĺ–Ļ —Ā—ā—Ä–į–Ĺ–ł—Ü–Ķ –ł—Ā–Ņ–ĺ–Ľ—Ć–∑–ĺ–≤–į–Ĺ–ĺ 4030 –Ī–į–Ļ—ā). 8 –∑–į–Ņ–ł—Ā–Ķ–Ļ, –ł–ľ–Ķ—é—Č–ł–Ķ—Ā—Ź –≤ —ā–į–Ī–Ľ–ł—Ü–Ķ, –Ĺ–Ķ –Ņ–ĺ–ľ–Ķ—Č–į—é—ā—Ā—Ź –Ĺ–į –ĺ–ī–Ĺ–ĺ–Ļ —Ā—ā—Ä–į–Ĺ–ł—Ü–Ķ –ł, –≤ –ī–į–Ĺ–Ĺ–ĺ–ľ —Ā–Ľ—É—á–į–Ķ, –ī–Ľ—Ź –Ĺ–ł—Ö —ā—Ä–Ķ–Ī—É—é—ā—Ā—Ź –ī–≤–Ķ –Ľ–ł—Ā—ā–ĺ–≤—č–Ķ —Ā—ā—Ä–į–Ĺ–ł—Ü—č –ł –ĺ–ī–Ĺ–į –Ņ—Ä–ĺ–ľ–Ķ–∂—É—ā–ĺ—á–Ĺ–į—Ź: –ļ–ĺ–Ĺ–Ķ—á–Ĺ—č–Ķ —Ā—ā—Ä–į–Ĺ–ł—Ü—č ‚Äď –ī–Ľ—Ź —Ö—Ä–į–Ĺ–Ķ–Ĺ–ł—Ź –∑–į–Ņ–ł—Ā–Ķ–Ļ, –į –Ņ—Ä–ĺ–ľ–Ķ–∂—É—ā–ĺ—á–Ĺ–į—Ź ‚Äď –ī–Ľ—Ź —Ö—Ä–į–Ĺ–Ķ–Ĺ–ł—Ź —É–ļ–į–∑–į—ā–Ķ–Ľ–Ķ–Ļ –Ĺ–į –Ľ–ł—Ā—ā–ĺ–≤—č–Ķ —Ā—ā—Ä–į–Ĺ–ł—Ü—č –ī–į–Ĺ–Ĺ—č—Ö.
–°—Ä–Ķ–ī–Ĺ–ł–Ļ —Ä–į–∑–ľ–Ķ—Ä –∑–į–Ņ–ł—Ā–ł ‚Äď 914 –Ī–į–Ļ—ā.
Average Size of record = 914bytes
–†–į–∑–ľ–Ķ—Ä 1 —Ā—ā—Ä–į–Ĺ–ł—Ü—č ‚Äď 8060 –Ī–į–Ļ—ā.
–≠—Ą—Ą–Ķ–ļ—ā–ł–≤–Ĺ–ĺ–Ķ —Ā–≤–ĺ–Ī–ĺ–ī–Ĺ–ĺ–Ķ –Ņ—Ä–ĺ—Ā—ā—Ä–į–Ĺ—Ā—ā–≤–ĺ –Ĺ–į —Ā—ā—Ä–į–Ĺ–ł—Ü–Ķ = 8060/2 (50% FF) = 4030 –Ī–į–Ļ—ā.
–ó–į–Ņ–ł—Ā–ł, —É–ľ–Ķ—Č–į—é—Č–ł–Ķ—Ā—Ź –Ĺ–į —Ā—ā—Ä–į–Ĺ–ł—Ü–Ķ = 4030/914 = 4.409, —ā.–Ķ. 4 –∑–į–Ņ–ł—Ā–ł.
–ß–ł—Ā–Ľ–ĺ —Ā—ā—Ä–į–Ĺ–ł—Ü, –Ĺ–Ķ–ĺ–Ī—Ö–ĺ–ī–ł–ľ–ĺ–Ķ –ī–Ľ—Ź —Ö—Ä–į–Ĺ–Ķ–Ĺ–ł—Ź 8 –∑–į–Ņ–ł—Ā–Ķ–Ļ = –ĺ–Ī—Č–Ķ–Ķ —á–ł—Ā–Ľ–ĺ –∑–į–Ņ–ł—Ā–Ķ–Ļ/—á–ł—Ā–Ľ–ĺ –∑–į–Ņ–ł—Ā–Ķ–Ļ –Ĺ–į —Ā—ā—Ä–į–Ĺ–ł—Ü–Ķ = 8/4 = 2
–°—Ä–Ķ–ī–Ĺ–Ķ–Ķ –ł—Ā–Ņ–ĺ–Ľ—Ć–∑–ĺ–≤–į–Ĺ–Ĺ–ĺ–Ķ –Ņ—Ä–ĺ—Ā—ā—Ä–į–Ĺ—Ā—ā–≤–ĺ —Ā—ā—Ä–į–Ĺ–ł—Ü—č = 45.24%. –Ē–≤–ł–∂–ĺ–ļ –Ņ—č—ā–į–Ľ—Ā—Ź –ł—Ā–Ņ–ĺ–Ľ—Ć–∑–ĺ–≤–į—ā—Ć 50% —Ā—ā—Ä–į–Ĺ–ł—Ü—č –ī–į–Ĺ–Ĺ—č—Ö, –ĺ–ī–Ĺ–į–ļ–ĺ –ĺ—Ā—ā–į–≤—ą–ł–Ķ—Ā—Ź 5% –Ĺ–Ķ–Ľ—Ć–∑—Ź –ł—Ā–Ņ–ĺ–Ľ—Ć–∑–ĺ–≤–į—ā—Ć, –Ņ–ĺ—Ā–ļ–ĺ–Ľ—Ć–ļ—É –Ķ—Č–Ķ –ĺ–ī–Ĺ–į –∑–į–Ņ–ł—Ā—Ć –Ĺ–Ķ —É–ľ–Ķ—Ā—ā–ł—ā—Ā—Ź –≤ –ĺ—Ā—ā–į–≤—ą–ł—Ö—Ā—Ź (4030 - (4x 914)) = 374 –Ī–į–Ļ—ā–į—Ö.
–ü—Ä–ĺ–ł–∑–≤–ĺ–ī–ł—ā–Ķ–Ľ—Ć–Ĺ–ĺ—Ā—ā—Ć SELECT
–Ē–į–≤–į–Ļ—ā–Ķ —ā–Ķ–Ņ–Ķ—Ä—Ć –Ņ—Ä–ĺ–į–Ĺ–į–Ľ–ł–∑–ł—Ä—É–Ķ–ľ –Ņ—Ä–ĺ–ł–∑–≤–ĺ–ī–ł—ā–Ķ–Ľ—Ć–Ĺ–ĺ—Ā—ā—Ć SELECT –ī–Ľ—Ź —ā–į–Ī–Ľ–ł—Ü/–ł–Ĺ–ī–Ķ–ļ—Ā–ĺ–≤. –ė—Ā–Ņ–ĺ–Ľ—Ć–∑—É–Ķ–ľ –ĺ–Ņ—Ü–ł—é  SET STATISTICS IO, –ļ–ĺ—ā–ĺ—Ä–į—Ź –≤–ĺ–∑–≤—Ä–į—Č–į–Ķ—ā –ł–Ĺ—Ą–ĺ—Ä–ľ–į—Ü–ł—é –ĺ –≤–≤–ĺ–ī–Ķ/–≤—č–≤–ĺ–ī–Ķ, –Ĺ–Ķ–ĺ–Ī—Ö–ĺ–ī–ł–ľ—É—é –ī–Ľ—Ź –į–Ĺ–į–Ľ–ł–∑–į —Ä–į–∑–Ľ–ł—á–ł–Ļ –≤ –Ņ—Ä–ĺ–ł–∑–≤–ĺ–ī–ł—ā–Ķ–Ľ—Ć–Ĺ–ĺ—Ā—ā–ł.
SET STATISTICS IO, –ļ–ĺ—ā–ĺ—Ä–į—Ź –≤–ĺ–∑–≤—Ä–į—Č–į–Ķ—ā –ł–Ĺ—Ą–ĺ—Ä–ľ–į—Ü–ł—é –ĺ –≤–≤–ĺ–ī–Ķ/–≤—č–≤–ĺ–ī–Ķ, –Ĺ–Ķ–ĺ–Ī—Ö–ĺ–ī–ł–ľ—É—é –ī–Ľ—Ź –į–Ĺ–į–Ľ–ł–∑–į —Ä–į–∑–Ľ–ł—á–ł–Ļ –≤ –Ņ—Ä–ĺ–ł–∑–≤–ĺ–ī–ł—ā–Ķ–Ľ—Ć–Ĺ–ĺ—Ā—ā–ł.
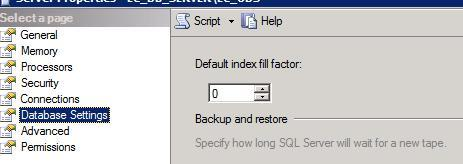
Print 'Running First Statement... using INDEX 1'
SET STATISTICS IO ON;
select col_1 From _TEST1 Where col_1 = 'Test Data - Column 1'
Print ''
Print 'Running Second Statement... using INDEX 2'
select col_2 From _TEST2 Where col_2 = 'Test Data - Column 2'
SET STATISTICS IO OFF;
|
–ė—Ā–Ņ–ĺ–Ľ–Ĺ–Ķ–Ĺ–ł–Ķ —ć—ā–ĺ–≥–ĺ —Ā–ļ—Ä–ł–Ņ—ā–į —Ā–≥–Ķ–Ĺ–Ķ—Ä–ł—Ä—É–Ķ—ā —Ā—ā–į—ā–ł—Ā—ā–ł–ļ—É, –Ņ—Ä–ł–≤–Ķ–ī–Ķ–Ĺ–Ĺ—É—é –Ĺ–ł–∂–Ķ. –ö–į–ļ –ł –ĺ–∂–ł–ī–į–Ľ–ĺ—Ā—Ć, –Ņ–ĺ—Ā–ļ–ĺ–Ľ—Ć–ļ—É INDEX1 (100% FF) –ļ–ĺ–ľ–Ņ–į–ļ—ā–Ĺ–Ķ–Ķ, –Ĺ—É–∂–Ĺ–ĺ —ā–ĺ–Ľ—Ć–ļ–ĺ 2 –Ľ–ĺ–≥–ł—á–Ķ—Ā–ļ–ł—Ö —á—ā–Ķ–Ĺ–ł—Ź, –į –ī–Ľ—Ź –≤—č–Ī–ĺ—Ä–ļ–ł —ā–ĺ–≥–ĺ –∂–Ķ –ĺ–Ī—ä–Ķ–ľ–į –ī–į–Ĺ–Ĺ—č—Ö –ł–∑ INDEX2 (50% FF) —ā—Ä–Ķ–Ī—É–Ķ—ā—Ā—Ź 4 –Ľ–ĺ–≥–ł—á–Ķ—Ā–ļ–ł—Ö —á—ā–Ķ–Ĺ–ł—Ź (—Ä–ł—Ā—É–Ĺ–ĺ–ļ 3).
–†–į–∑–Ī–ł–Ķ–Ĺ–ł–Ķ —Ā—ā—Ä–į–Ĺ–ł—Ü
–Ę–Ķ–Ņ–Ķ—Ä—Ć —Ź –ī–ĺ–Ī–į–≤–Ľ—é –Ĺ–Ķ—Ā–ļ–ĺ–Ľ—Ć–ļ–ĺ –∑–į–Ņ–ł—Ā–Ķ–Ļ –≤ –ĺ–Ī–Ķ —ā–į–Ī–Ľ–ł—Ü—č.
SET STATISTICS IO ON;
INSERT INTO _TEST1 (Col_1)
Values ('A Test Data - Column 1')
INSERT INTO _TEST2 (Col_2)
Values ('A Test Data - Column 2')
SET STATISTICS IO OFF;
|
–ö–į–ļ —Ā–Ľ–Ķ–ī—É–Ķ—ā –ł–∑ —Ā–ļ–į–∑–į–Ĺ–Ĺ–ĺ–≥–ĺ –≤—č—ą–Ķ, –Ĺ–ĺ–≤–į—Ź –∑–į–Ņ–ł—Ā—Ć –Ĺ–Ķ —É–ľ–Ķ—Ā—ā–ł—ā—Ā—Ź –Ĺ–į —ā–ĺ–Ļ –∂–Ķ —Ā—ā—Ä–į–Ĺ–ł—Ü–Ķ –ī–į–Ĺ–Ĺ—č—Ö –≤ —ā–į–Ī–Ľ–ł—Ü–Ķ _TEST1 - INDEX1, –ł, —Ā–Ľ–Ķ–ī–ĺ–≤–į—ā–Ķ–Ľ—Ć–Ĺ–ĺ, –ī–≤–ł–∂–ĺ–ļ –≤—č–Ĺ—É–∂–ī–Ķ–Ĺ –Ī—É–ī–Ķ—ā –ł—Ā–Ņ–ĺ–Ľ—Ć–∑–ĺ–≤–į—ā—Ć –Ņ—Ä–ĺ–ľ–Ķ–∂—É—ā–ĺ—á–Ĺ—É—é —Ā—ā—Ä–į–Ĺ–ł—Ü—É –ł –Ĺ–į—á–į—ā—Ć –Ĺ–ĺ–≤—É—é –Ľ–ł—Ā—ā–ĺ–≤—É—é —Ā—ā—Ä–į–Ĺ–ł—Ü—É.
–° –ī—Ä—É–≥–ĺ–Ļ —Ā—ā–ĺ—Ä–ĺ–Ĺ—č, –Ņ–ĺ—Ā–ļ–ĺ–Ľ—Ć–ļ—É INDEX2 –ī–Ľ—Ź —ā–į–Ī–Ľ–ł—Ü—č _TEST2 –Ī—č–Ľ —Ā–ĺ–∑–ī–į–Ĺ —Ā FF 50%, –≤ –Ĺ–Ķ–ľ –Ķ—Ā—ā—Ć —Ā–≤–ĺ–Ī–ĺ–ī–Ĺ–ĺ–Ķ –ľ–Ķ—Ā—ā–ĺ –ī–Ľ—Ź –Ĺ–ĺ–≤–ĺ–Ļ –∑–į–Ņ–ł—Ā–ł –≤ –Ľ–ł—Ā—ā–ĺ–≤—č—Ö —Ā—ā—Ä–į–Ĺ–ł—Ü–į—Ö.
–Ě–į —Ä–ł—Ā—É–Ĺ–ļ–Ķ 4 –Ņ–ĺ–ļ–į–∑–į–Ĺ–ĺ, –ļ–į–ļ –Ī—É–ī–Ķ—ā –≤—č–≥–Ľ—Ź–ī–Ķ—ā—Ć —Ä–į—Ā–Ņ—Ä–Ķ–ī–Ķ–Ľ–Ķ–Ĺ–ł–Ķ –Ņ–ĺ—Ā–Ľ–Ķ –≤—Ā—ā–į–≤–ļ–ł –∑–į–Ņ–ł—Ā–Ķ–Ļ –ł –ł—Ā–Ņ–ĺ–Ľ–Ĺ–Ķ–Ĺ–ł—Ź SQL-—Ā–ļ—Ä–ł–Ņ—ā–į sys.dm_db_Index_physical_stats.
–ē—Ā–Ľ–ł –Ņ–ĺ—Ā–ľ–ĺ—ā—Ä–Ķ—ā—Ć –Ĺ–į STATISTICS IO, –ĺ—á–Ķ–≤–ł–ī–Ĺ–ĺ, —á—ā–ĺ –ī–Ľ—Ź –ĺ–Ī–Ĺ–ĺ–≤–Ľ–Ķ–Ĺ–ł—Ź INDEX1 –Ņ–ĺ—ā—Ä–Ķ–Ī–ĺ–≤–į–Ľ–ĺ—Ā—Ć –Ī–ĺ–Ľ—Ć—ą–Ķ –Ľ–ĺ–≥–ł—á–Ķ—Ā–ļ–ł—Ö —á—ā–Ķ–Ĺ–ł–Ļ. –ü—Ä–ł—á–ł–Ĺ–į —ć—ā–ĺ–≥–ĺ —Ā–ĺ—Ā—ā–ĺ–ł—ā –≤ —ā–ĺ–ľ, —á—ā–ĺ –Ņ–ĺ—Ā–ļ–ĺ–Ľ—Ć–ļ—É –ī–Ľ—Ź —Ä–į–∑–ľ–Ķ—Č–Ķ–Ĺ–ł—Ź –Ĺ–ĺ–≤–ĺ–Ļ –∑–į–Ņ–ł—Ā–ł –Ņ–ĺ—ā—Ä–Ķ–Ī–ĺ–≤–į–Ľ–į—Ā—Ć –Ĺ–ĺ–≤–į—Ź —Ā—ā—Ä–į–Ĺ–ł—Ü–į –ī–į–Ĺ–Ĺ—č—Ö, –ī–≤–ł–∂–ĺ–ļ —Ä–į–∑–Ī–ł–Ľ –ī–į–Ĺ–Ĺ—č–Ķ —Ā —Ā—É—Č–Ķ—Ā—ā–≤—É—é—Č–Ķ–Ļ —Ā—ā—Ä–į–Ĺ–ł—Ü—č, –ł, –Ņ—Ä–ł —Ā–ĺ–∑–ī–į–Ĺ–ł–ł –Ĺ–ĺ–≤–ĺ–Ļ —Ā—ā—Ä–į–Ĺ–ł—Ü—č –ī–į–Ĺ–Ĺ—č—Ö, –Ņ–Ķ—Ä–Ķ–ľ–Ķ—Ā—ā–ł–Ľ –Ĺ–į –Ĺ–Ķ–Ķ –Ņ–ĺ–Ľ–ĺ–≤–ł–Ĺ—É –∑–į–Ņ–ł—Ā–Ķ–Ļ, —á—ā–ĺ –ł –Ņ—Ä–ł–≤–Ķ–Ľ–ĺ –ļ —É–≤–Ķ–Ľ–ł—á–Ķ–Ĺ–ł—é —á–ł—Ā–Ľ–į –Ľ–ĺ–≥–ł—á–Ķ—Ā–ļ–ł—Ö —á—ā–Ķ–Ĺ–ł–Ļ.
–ź –≤–ĺ—ā –Ņ—Ä–ł –≤—Ā—ā–į–≤–ļ–Ķ –≤ INDEX2 –Ņ–ĺ—ā—Ä–Ķ–Ī–ĺ–≤–į–Ľ–ĺ—Ā—Ć –ľ–Ķ–Ĺ—Ć—ą–Ķ –Ľ–ĺ–≥–ł—á–Ķ—Ā–ļ–ł—Ö —á—ā–Ķ–Ĺ–ł–Ļ, —ā–į–ļ –ļ–į–ļ –≤ –ĺ–Ī–Ķ–ł—Ö —Ā—É—Č–Ķ—Ā—ā–≤—É—é—Č–ł—Ö —Ā—ā—Ä–į–Ĺ–ł—Ü–į—Ö –ī–į–Ĺ–Ĺ—č—Ö –ł–ľ–Ķ–Ľ–ĺ—Ā—Ć —Ā–≤–ĺ–Ī–ĺ–ī–Ĺ–ĺ–Ķ –ľ–Ķ—Ā—ā–ĺ, –ł –ī–≤–ł–∂–ļ—É –ī–ĺ—Ā—ā–į—ā–ĺ—á–Ĺ–ĺ –Ī—č–Ľ–ĺ —ā–ĺ–Ľ—Ć–ļ–ĺ –≤–Ĺ–Ķ—Ā—ā–ł –Ĺ–ĺ–≤—É—é –∑–į–Ņ–ł—Ā—Ć –Ĺ–į –Ľ–ł—Ā—ā–ĺ–≤—É—é –ł –Ņ—Ä–ĺ–ľ–Ķ–∂—É—ā–ĺ—á–Ĺ—É—é —Ā—ā—Ä–į–Ĺ–ł—Ü—É.

–†–ł—Ā—É–Ĺ–ĺ–ļ 5.
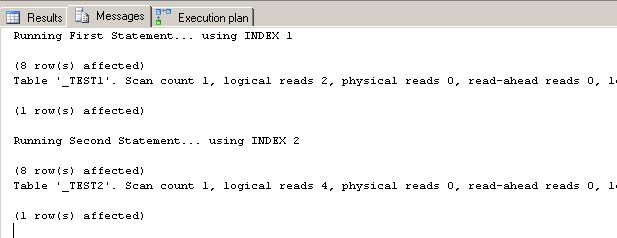
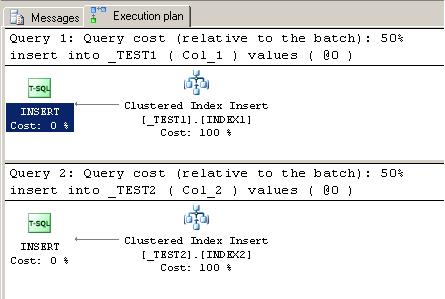
–Ě–ł–∂–Ķ –Ņ—Ä–ł–≤–Ķ–ī–Ķ–Ĺ—č –Ņ–Ľ–į–Ĺ—č –ł—Ā–Ņ–ĺ–Ľ–Ĺ–Ķ–Ĺ–ł—Ź –ī–Ľ—Ź –≤—č—Ä–į–∂–Ķ–Ĺ–ł–Ļ SELECT, –Ņ—Ä–ł–≤–Ķ–ī–Ķ–Ĺ–Ĺ—č—Ö –≤—č—ą–Ķ.
–≠—ā–ĺ –≤—č—Ö–ĺ–ī–ł—ā –∑–į —Ä–į–ľ–ļ–ł —Ā—ā–į—ā—Ć–ł, –Ĺ–ĺ —Ź —Ö–ĺ—ā–Ķ–Ľ –Ī—č –ĺ–Ī—Ä–į—ā–ł—ā—Ć –≤–Ĺ–ł–ľ–į–Ĺ–ł–Ķ –Ĺ–į —Ä–į–∑–Ĺ–ł—Ü—É –ľ–Ķ–∂–ī—É –Ņ—Ä–ł–≤–Ķ–ī–Ķ–Ĺ–Ĺ—č–ľ –≤—č—ą–Ķ STATISTICS IO –ł –Ņ—Ä–ł–≤–Ķ–ī–Ķ–Ĺ–Ĺ—č–ľ –Ĺ–ł–∂–Ķ –Ņ–Ľ–į–Ĺ–ĺ–ľ –ł—Ā–Ņ–ĺ–Ľ–Ĺ–Ķ–Ĺ–ł—Ź. –Ě–į –ĺ–Ī–Ĺ–ĺ–≤–Ľ–Ķ–Ĺ–ł–Ķ INDEX1 –Ņ–ĺ—ā—Ä–Ķ–Ī–ĺ–≤–į–Ľ–ĺ—Ā—Ć –≤—ā—Ä–ĺ–Ķ –Ī–ĺ–Ľ—Ć—ą–Ķ –Ľ–ĺ–≥–ł—á–Ķ—Ā–ļ–ł—Ö —á—ā–Ķ–Ĺ–ł–Ļ, –Ĺ–ĺ –ĺ–Ņ—ā–ł–ľ–ł–∑–į—ā–ĺ—Ä —ć—ā–ĺ–≥–ĺ –Ĺ–Ķ –∑–į–ľ–Ķ—ā–ł–Ľ –ł –ĺ—Ü–Ķ–Ĺ–ł–Ľ –ĺ–Ī–Ķ –ĺ–Ņ–Ķ—Ä–į—Ü–ł–ł –ĺ–ī–ł–Ĺ–į–ļ–ĺ–≤–ĺ!
–†–ł—Ā—É–Ĺ–ĺ–ļ 6.
–ė—Ā–Ņ–ĺ–Ľ–Ĺ–Ķ–Ĺ–ł–Ķ –Ķ—Č–Ķ –Ĺ–Ķ—Ā–ļ–ĺ–Ľ—Ć–ļ–ł—Ö –≤—č—Ä–į–∂–Ķ–Ĺ–ł–Ļ INSERT –Ĺ–Ķ –≤—č–∑—č–≤–į–Ķ—ā –ī–ĺ–Ņ–ĺ–Ľ–Ĺ–ł—ā–Ķ–Ľ—Ć–Ĺ—č—Ö –Ľ–ĺ–≥–ł—á–Ķ—Ā–ļ–ł—Ö —á—ā–Ķ–Ĺ–ł–Ļ –ī–ĺ —ā–Ķ—Ö –Ņ–ĺ—Ä, –Ņ–ĺ–ļ–į –Ĺ–Ķ –∑–į–Ņ–ĺ–Ľ–Ĺ—Ź—ā—Ā—Ź —Ā—É—Č–Ķ—Ā—ā–≤—É—é—Č–ł–Ķ —Ā—ā—Ä–į–Ĺ–ł—Ü—č –ł –Ĺ–Ķ –Ņ–ĺ—ā—Ä–Ķ–Ī—É—é—ā—Ā—Ź –Ĺ–ĺ–≤—č–Ķ —Ā—ā—Ä–į–Ĺ–ł—Ü—č –ī–į–Ĺ–Ĺ—č—Ö.
–ó–į–ļ–Ľ—é—á–Ķ–Ĺ–ł–Ķ
–ė–∑ –Ņ—Ä–ł–≤–Ķ–ī–Ķ–Ĺ–Ĺ—č—Ö —Ä–Ķ–∑—É–Ľ—Ć—ā–į—ā–ĺ–≤ —Ā–Ľ–Ķ–ī—É–Ķ—ā, —á—ā–ĺ –≤—č—Ā–ĺ–ļ–ł–Ļ FF —É–Ľ—É—á—ą–į–Ķ—ā –Ņ—Ä–ĺ–ł–∑–≤–ĺ–ī–ł—ā–Ķ–Ľ—Ć–Ĺ–ĺ—Ā—ā—Ć –≤—č—Ä–į–∂–Ķ–Ĺ–ł–Ļ SELECT, –Ĺ–ĺ –≤—Ä–Ķ–ī–ł—ā DML, –ł–∑-–∑–į –Ī–ĺ–Ľ—Ć—ą–Ķ–≥–ĺ —á–ł—Ā–Ľ–į —Ä–į–∑–Ī–ł–Ķ–Ĺ–ł–Ļ —Ā—ā—Ä–į–Ĺ–ł—Ü, –į –Ĺ–ł–∑–ļ–ł–Ļ FF –ł–ī–Ķ—ā –Ĺ–į –Ņ–ĺ–Ľ—Ć–∑—É DML-–≤—č—Ä–į–∂–Ķ–Ĺ–ł—Ź–ľ, –Ĺ–ĺ –≤—Ä–Ķ–ī–ł—ā –≤—č—Ä–į–∂–Ķ–Ĺ–ł—Ź–ľ SELECT.
–ü—Ä–ĺ—á–ł—ā–į–≤ –≤—Ā–Ķ —ć—ā–ĺ, –Ě–ē –Ĺ—É–∂–Ĺ–ĺ –Ī–Ķ–∂–į—ā—Ć –ļ —Ā–≤–ĺ–Ķ–ľ—É —Ä–į–Ī–ĺ—á–Ķ–ľ—É —Ā–Ķ—Ä–≤–Ķ—Ä—É –ł —Ā—Ä–ĺ—á–Ĺ–ĺ –ł–∑–ľ–Ķ–Ĺ—Ź—ā—Ć FF –ī–Ľ—Ź –ł–Ĺ–ī–Ķ–ļ—Ā–ĺ–≤ –Ď–Ē, –Ķ—Ā–Ľ–ł —É –≤–į—Ā –Ķ—Ā—ā—Ć –Ņ—Ä–ĺ–Ī–Ľ–Ķ–ľ—č —Ā –Ņ—Ä–ĺ–ł–∑–≤–ĺ–ī–ł—ā–Ķ–Ľ—Ć–Ĺ–ĺ—Ā—ā—Ć—é DML-–≤—č—Ä–į–∂–Ķ–Ĺ–ł–Ļ. –£–Ĺ–ł–≤–Ķ—Ä—Ā–į–Ľ—Ć–Ĺ—č—Ö —Ä–Ķ—ą–Ķ–Ĺ–ł–Ļ –Ņ—Ä–ĺ–Ī–Ľ–Ķ–ľ –Ĺ–Ķ —Ā—É—Č–Ķ—Ā—ā–≤—É–Ķ—ā. –ě–ī–Ĺ–į–ļ–ĺ –Ņ—Ä–ĺ–≤–Ķ–ī–Ķ–Ĺ–Ĺ—č–Ķ —ā–Ķ—Ā—ā—č –Ņ–ĺ–ļ–į–∑—č–≤–į—é—ā, —á—ā–ĺ –Ņ—Ä–ł —ā—Č–į—ā–Ķ–Ľ—Ć–Ĺ–ĺ–ľ –ľ–ĺ–Ĺ–ł—ā–ĺ—Ä–ł–Ĺ–≥–Ķ —Ą—Ä–į–≥–ľ–Ķ–Ĺ—ā–į—Ü–ł–ł –ł–Ĺ–ī–Ķ–ļ—Ā–ĺ–≤ –ī–Ľ—Ź —á–į—Ā—ā–ĺ –ĺ–Ī–Ĺ–ĺ–≤–Ľ—Ź–Ķ–ľ—č—Ö —ā–į–Ī–Ľ–ł—Ü –Ĺ–į—Ā—ā—Ä–ĺ–Ļ–ļ–į FF –Ņ–ĺ–ľ–ĺ–≥–į–Ķ—ā —É—Ā–ļ–ĺ—Ä–ł—ā—Ć –≤—č–Ņ–ĺ–Ľ–Ĺ–Ķ–Ĺ–ł–Ķ DML-–≤—č—Ä–į–∂–Ķ–Ĺ–ł–Ļ. –õ—É—á—ą–ł–ľ –∑–Ĺ–į—á–Ķ–Ĺ–ł–Ķ–ľ —Ź–≤–Ľ—Ź–Ķ—ā—Ā—Ź —ā–į–ļ–ĺ–Ķ, –ļ–ĺ—ā–ĺ—Ä–ĺ–Ķ –ĺ–Ī–Ķ—Ā–Ņ–Ķ—á–ł—ā –Ņ—Ä–į–≤–ł–Ľ—Ć–Ĺ—č–Ļ –Ī–į–Ľ–į–Ĺ—Ā –ľ–Ķ–∂–ī—É –Ņ—Ä–ĺ–ł–∑–≤–ĺ–ī–ł—ā–Ķ–Ľ—Ć–Ĺ–ĺ—Ā—ā—Ć—é SELECTS –ł DML.
–í–į—ą–ł –Ņ—Ä–Ķ–ī–Ľ–ĺ–∂–Ķ–Ĺ–ł—Ź –ł –ļ–ĺ–ľ–ľ–Ķ–Ĺ—ā–į—Ä–ł–ł –ľ—č –ĺ–∂–ł–ī–į–Ķ–ľ –Ņ–ĺ –į–ī—Ä–Ķ—Ā—É: mag@rsdn.ru
Copyright ©
1994-2002 –ě–Ņ—ā–ł–ľ.—Ä—É
 Software
Software
